BMC Medical Informatics and Decision Making 2006, 6:30
|
|
|
- Lilian Palmer
- 6 years ago
- Views:
Transcription
 versions will be made available soon.")
1 BMC Medical Informatics and Decision Making This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Extracting principal diagnosis, co-morbidity and smoking status for asthma research: evaluation of a natural language processing system BMC Medical Informatics and Decision Making 2006, 6:30 doi: / Qing T Zeng (qzeng@dsg.harvard.edu) Sergey Goryachev (sgoryachev@dsg.harvard.edu) Scott Weiss (scott.weiss@channing.harvard.edu) Margarita Sordo (msordo@dsg.harvard.edu) Shawn N Murphy (SNMURPHY@PARTNERS.ORG) Ross Lazarus (ross.lazarus@channing.harvard.edu) ISSN Article type Research article Submission date 9 May 2006 Acceptance date 26 July 2006 Publication date 26 July 2006 Article URL Like all articles in BMC journals, this peer-reviewed article was published immediately upon acceptance. It can be downloaded, printed and distributed freely for any purposes (see copyright notice below). Articles in BMC journals are listed in PubMed and archived at PubMed Central. For information about publishing your research in BMC journals or any BioMed Central journal, go to Zeng et al., licensee BioMed Central Ltd. This is an open access article distributed under the terms of the Creative Commons Attribution License ( which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
2 Extracting principal diagnosis, co-morbidity and smoking status for asthma research: evaluation of a natural language processing system Qing T Zeng 1, Sergey Goryachev 1, Scott Weiss 2, Margarita Sordo 2, Shawn N Murphy 3, Ross Lazarus 2 1 Decision Systems Group, Brigham and Women s Hospital, Boston, MA, United States 2 Channing Laboratory, Brigham and Women s Hospital, Boston, MA, United States 3 Laboratory of Computer Science, Massachusetts General Hospital, Harvard Medical School, Boston, MA, United States Corresponding author addresses: QTZ: qzeng@dsg.harvard.edu SG: sgoryachev@dsg.harvard.edu SW: scott.weiss@channing.harvard.edu MS: msordo@dsg.harvard.edu SNM: snmurphy@partners.org RL: ross.lazarus@channing.harvard.edu Abstract Background The text descriptions in electronic medical records are a rich source of information. We have developed a Health Information Text Extraction (HITEx) tool and used it to extract key findings for a research study on airways disease. Methods The principal diagnosis, co-morbidity and smoking status extracted by HITEx from a set of 150 discharge summaries were compared to an expert-generated gold standard. Results The accuracy of HITEx was 82% for principal diagnosis, 87% for co-morbidity, and 90% for smoking status extraction, when cases labeled Insufficient Data by the gold standard were excluded. Conclusions We consider the results promising, given the complexity of the discharge summaries and the extraction tasks. 1
3 Background Clinical records contain much potentially useful information in free text form. In electronic medical records (EMR), information such as family history, signs and symptoms and personal history of drinking and smoking are typically embedded in text descriptions provided by clinicians in the form of progress notes and in more formalized discharge summaries. Even when coded data are available (e.g. billing codes for principal diagnoses and co-morbidities), they may not always be accurately assigned or widely utilized and may be subtly influenced by financial incentives. Natural language processing (NLP) techniques have demonstrated the potential to unlock such information from text. The MEDLEE system developed by Friedman et al [1], the Symtxt system developed by Haug [2], the statistical NLP tool by Taira et al [3], and the widely used MetaMap/MMtx [4] by National Library of Medicine researchers are examples of medical NLP systems. These and other systems have been evaluated for a variety of tasks from extracting pathology findings to identify pneumonia cases [5-12]. One challenge with many previously described medical NLP tools is that they are not easy to adapt, generalize and reuse. There had have been few examples of a NLP system developed by one institution adapted for use by an unrelated institution. One reason is that medical NLP programs are often tailored to domain or institution-specific document formats and other text characteristics. The intellectual property of software, of course, has also been an obstacle in sharing. As a part of the National Center for Biomedical Computing I2B2 (Informatics for Integrating Biology & the Bedside) project [13], we have been developing a NLP tool that we refer to as the Health Information Text Extraction (HITEx) tool. Following the example of GATE (General Architecture for Text Engineering) [14] and using GATE as a platform, a suite of open-source NLP modules were adapted or created. We then assembled these modules into pipelines for different tasks. One of the component projects under I2B2 is a study investigating factors contributing to asthma exacerbation and hospitalization. HITEx was used to extract from discharge summaries the principal diagnoses and co-morbidities associated with a hospitalization, and the smoking status of the patient, from discharge summaries and longitudinal medical record s free form text notes [15]. To evaluate the accuracy of information extracted by HITEx, an asthma expert reviewed 150 discharge summaries of patients with known history of asthma or Chronic Obstructive Pulmonary Disease (COPD) and extracted principal diagnoses, co-morbidities and smoking status information from each report. Since a human s ability to maintain focus tends to decline after hours of review, so the human expert s extraction were confirmed by four other physician members of the I2B2 team. The HITEx results were then compared to the human extractions. 2
4 NLP HITEx uses GATE as the development platform. GATE is an open-source natural language processing framework; it includes a set of NLP modules, collectively known as CREOLE: a Collection of REusable Objects for Language Engineering [14]. CREOLE contains NLP modules that perform some common tasks, such as tokenizing, part-of-speech (POS) tagging, and noun phrases parsing. The GATE framework can be viewed as a backplane for plugging in CREOLE components. The framework provides various services to the components, such as component discovery, bootstrapping, loading and reloading, management and visualization of data structures, and data storage and process execution. GATE is an active project at the University of Sheffield, UK with a large user community worldwide. HITEx uses 11 GATE modules (components), two of which were adapted from the CREOLE, and rest were developed specifically for HITEx (see Figure 1): 1. Section Splitter: splits the medical report into the sections; assigns the section to the category (categories), which are based on the section headers for each type of the medical document. For the parsing of discharge summaries and outpatient notes, we collected and categorized over 1000 section headers. For example, principal diagnosis is categorized as Primary Diagnosis, while the discharge medications header is mapped to both the Discharge and Medications categories. The header collections are not part of the section splitter, but supplied to the splitter as a configuration file. 2. Section Filter: selects the subset of sections based on the selection criteria, such as category name, section name, etc. This module uses a simple expression language that allows rather complex criteria expressions to be created. 3. Sentence Splitter: splits the section into sentences. The module relies on the set of regular expression-based rules that define sentence breaks. 4. Sentence Tokenizer: splits the sentence into the tokens (words). The module uses the extensive set of regular expressions that define both token delimiters and special cases when certain punctuation symbols should not be used as token delimiters (e.g. decimal point in numbers, period in some multi-word abbreviations, etc). 5. POS Tagger: assigns part-of-speech tags to each word (token) in the sentence. This module is based on the Brill-style, rule-based POS tagger, originally written by Mark Hepple [16] as a plug-in for the Gate framework. 6. Noun Phrase Finder: groups POS-tagged words into the noun phrases using the set of rules and the lexicon. This module is an implementation of the Ramshaw and Marcus transformational learning-based noun phrase chunker [17]. The original version is available as a Gate framework plug-in. 7. UMLS Concept Mapper: maps the strings of text to UMLS (Unified Medical Language System) concepts. The module first attempts exact match; when exact matches are not found, it stems, normalizes and truncates the string. For instance, failures of heart is mapped to the concept Heart Failure and back pain and asthma is mapped to concepts Back Pain and Asthma. 8. Negation Finder: assigns the negation modifier to the existing UMLS concepts. Currently, this module is an implementation of NexEx-2 negation algorithm developed by Chapman et al. [18]. 3
5 9. N-gram tool: extract n-word text fragments along with their frequency from a collection of text. 10. Classifier: takes a smoking-related sentence to determine the smoking status of a patient. The classifier is a support vector machine (SVM) using single words as features. It was trained and tested on a data set of about 8500 smoking-related sentences through 10-fold cross-validation. To create the classifier, we experimented with naïve Bayes, SVM and decision trees, and 1-3 word phrase features using Weka [19], which is a publicly available tool kit. The detailed description of the experiments can be found in a previous publication [15]. 11. Regular Expression-based Concept Finder: finds all occurrences of the concepts defined as a regular expression in the input chunk of text. For example: medications, smoking keywords, etc. Each module expects a set of parameters/configuration files. Take the task of extracting principal diagnosis for example, we would specify the primary diagnosis headers for the Section Filter module. For each task, a different pipeline of modules may be assembled. To extract diagnoses, Section Splitter, Section Filter, Sentence Splitter, Sentence Tokenizer, Part-of-Speech, Noun Phrase Finder, UMLS Concept Mapper and Negation Finder modules would be applied sequentially. While for extracting smoking status, Section Splitter, Section Filter, Sentence Splitter, N-gram tool and Classifier are formed into a pipeline. Except the smoking classifier module, none of the modules had been formally evaluated. In adhoc testing, results obtained from the modules were satisfactory. Asthma and COPD Asthma is the most common disease of the airways in children and adults [20]. Although most asthma patients are generally well controlled on modern medications, acute asthma flare-ups happen in a small subset of patients, occasionally leading to a life-threatening status asthmaticus exacerbation episode, often associated with hospitalization. Identifying preventable risk factors may allow clinicians to decrease these unfortunate events. In order to perform appropriate statistical analyses, measures of important environmental exposures are needed because these are known to substantially increase exacerbation risk, including co-morbidity, medication use, tobacco smoking history and smoking status. Since these were not available in coded form in the large data collection we are using, we sought to obtain estimates for these covariates from the case notes and discharge summary text corpus available for each patient, using NLP tools. While diagnosis is often the first item a medical NLP application extracts, distinguishing principal diagnosis from co-morbidities in text is a much more subtle task, because it requires us to reliably differentiate present from historical, and primary from secondary. In terms of complexity, inferring smoking status from text similarly requires distinguishing present from historical, and often requires subtle distinctions between syntactically similar textual expressions such as recent non-smoker and never smoked. 4
6 For billing purpose, professional coders (typically not clinicians) assign ICD9 codes to each encounter such as a hospitalization. While these codes are very useful, a number of studies have shown that they are not very reliable records of diagnoses [21-23]. Smoking status, on the other hand, is often not encoded. Methods A large data set containing records on approximately 97,000 asthma and COPD patients was obtained from the Partners Health Care Research Patient Data Repository (RPDR). The RPDR data warehouse includes a wide variety of records (not deidentified) including free text, administrative codes, laboratory codes and text, and numerous other data sources for all encounters for all patients at all Partners facilities. The patients included in our data set had one or more asthma or COPD related admission diagnosis (determined by their ICD9 billing codes) in one or more of their RPDR records. The RPDR population includes 90-98% of the total Partners patient population. The study was approved by the Brigham and Women s Hospital s institutional review board; the protocol number is 2004P (Subphenotypes in Common Airways Disorders). In the evaluation, we focused on discharge summaries, in particular, those related to hospitalization caused by asthma or COPD exacerbation. We collected a random sub-sample of 150 discharge summaries from the data set that either has had an asthma or COPD related ICD9 billing code or contains an asthma or COPD related string from an extensive list of related concepts and names that we manually identified. An asthma expert (STW) reviewed the 150 reports and answered the following questions for each report: 1. Principal diagnosis include asthma: yes/no/insufficient data 2. Principal diagnosis include COPD: yes/no/insufficient data 3. Co-morbidities include asthma: yes/no/insufficient data 4. Co-morbidities include COPD: yes/no/insufficient data 5. Smoking status: current smoker, past smoker, non smoker, patient denies smoking, insufficient data Similarly, HITEx was used to answer the same 5 questions for each report. First, we created three HITEx pipelines to extract principal diagnosis, co-morbidities and smoking status, respectively. The principal diagnosis and co-morbidities were then processed to determine if they contained an asthma or COPD diagnosis. To do so, we used the relationship table (MRREL) in the UMLS. All descendants of the asthma and COPD concepts were considered to be a type of asthma and COPD. Diagnoses extracted from the principal diagnosis sections (determined by the section headers) were deemed as principal. When we could not determine if a diagnosis was primary or secondary because of the lack of header information, it was considered to be primary by default. We also used ICD9 codes to answer the questions regarding the principal diagnosis and comorbidities. The ICD9 hierarchy was used to determine if a code is asthma or COPD related. The codes are: Asthma 493.*; COPD *, *, 466.*. 5
7 For asthma/copd principal diagnosis and co-morbidities, we compared the HITEx and ICD9 answers to that of the human expert. For smoking status, HITEx results were compared to the human expert s. Generally speaking, NLP programs infer yes for a diagnosis if certain string patterns are found, no if they are not found, but often do not have a notion of insufficient data. On the other hand, the human label of insufficient data could result from the absence of explicit information, the presence of ambiguous information or the presence of conflicting information. To compare HITEx results to the human ratings, we treated the insufficient data label in three ways: exclude cases with the label, regard it as yes, and regard it as no. In the case of smoking, though, non-smoker status are often explicitly stated so insufficient data was interpreted to mean that no smoking-related information was found. In addition, we experimented with two ways to combine ICD9 and HITEx results to improve the diagnosis extraction performance: NLP and ICD9: - Both are YES YES - everything else NO NLP or ICD9: - either one is YES YES - everything else NO We calculated the accuracy of HITEx, ICD9 and HITEx-ICD9 combinations, i.e. the percentage of cases which HITEx, ICD9 or HITEx-ICD9 combinations agreed with the expert. Sensitivity and specificity were also calculated, assuming the human expert as the correct classifier. In practice, a human s ability to maintain focus tends to decline after a few hours of this relatively tedious chart review, so the human expert s answers were confirmed by four other physician members of the I2B2 team. Some obvious errors and omissions were corrected by a consensus of clinicians at the team meeting. Results Comparing to the expert, the accuracy of HITEx for principal diagnosis extraction was 73% to 82% and for co-morbidity was 78% to 87% depending on how the expert label insufficient data was treated. The HITEx accuracy was higher than ICD9 in every category, though sometimes only by a small margin (Table 1). The combination of HITEx or ICD9 resulted in better accuracy of principal diagnosis extraction 78% to 86%, while the combination of HITEx and ICD9 resulted in better accuracy of comorbidities extraction 79% to 91%. HITEx achieved 64% to 77% sensitivity and 82% to 87% specificity in principal diagnosis extraction; and 40% to 71% sensitivity and 87% to 89% specificity in co-morbidity extraction (Table 2). Precision is reported in Table 3. We believe the lower sensitivity and higher 6
8 specificity of co-morbidity extraction was a result of HITEx treating a diagnosis as primary when we could differentiate primary from secondary. Overall, HITEx had better sensitivity and worse specificity than ICD9 (60% to 72% sensitivity and 85% to 91% specificity in principal diagnosis extraction; and 11% to 15% sensitivity and 90%-91% specificity in co-morbidity extraction). The combination of HITEx or ICD9 led to better sensitivities 78% to 92% for principal diagnosis extraction and 46% to 74% for co-morbidities extraction, while the combination of HITEx and ICD9 resulted in better specificities 93% to 97% for principal diagnosis extraction and 99% for co-morbidities extraction. The accuracy of smoking status extraction was 90%. The sensitivities and specificities range from 60% to 100% and 93 to 99% respectively (Table 3). Precision is reported in Table 5. Discussion This study evaluated the information extraction accuracy of a new, portable NLP system HITEx, by comparing it to an expert human gold standard. When Insufficient Data cases were excluded, the accuracy of HITEx for principal diagnosis extraction was 82% and for comorbidities was 87%. The sensitivity and specificity of HITEx were 77% and 87% for principal diagnosis and 70% and 89% for co-morbidity extraction. The accuracy of smoking status extraction was 90% and the sensitivities and specificities range from 60% to 100% and 93 to 99% respectively. Since ICD9 codes are generally available, we found that it could be used to complement the HITEx results: the combination of HITEx or ICD9 improves the accuracy to 86% for principal diagnosis, while the combination of HITEx and ICD9 improves the accuracy to 89% for comorbidities. The combination of HITEx or ICD9 led to better sensitivities 92% for principal diagnosis and 74% for co-morbidity, while the combination of HITEx and ICD9 resulted in better specificities 97% for principal diagnosis and 99% for co-morbidity. The HITEx performance we report here is comparable to the results from a number of previous studies in the literature [1, 24, 25], though there had also been better sensitivity and specificity reported for certain NLP applications [26, 27]. We find the HITEx results promising for the following reasons: 1. The discharge summaries we processed are a far messier corpus than narrower domain (e.g. radiology or pathology) reports reported in many previous studies. For example, each individual unit in each individual hospital within the Partners system tends to have its own specific style for these summary documents, with numerous broadly common features but also many idiosyncratic, local conventions. 2. The tasks we undertook in this study were relatively challenging. We are not aware of prior NLP attempts to differentiate principal diagnoses and co-morbidities. Determination of smoking status is more complicated than extracting the status of fever or headache, because smoking status is itself a relatively complex construct, and unfortunately is rarely the focus of specific attention in the discharge summary texts we encountered. 7
9 3. We made a decision not to embed decision making logic in the NLP system: for example, inferring HIV status from AZT or inferring pneumonia from infiltrate. While such logic is very useful, we believe it should be developed and evaluated separately. HITEx modules 3 through 7 provide the same functionality available in the MetaMap/MMTx. Instead of using MetaMap/MMTx, we adopted or developed these modules to allow local manipulation of the UMLS tables (e.g. add and remove synonyms) as well as utilization of the sentence and POS tags in other modules. Though no formal evaluation has been done, we have been collaborating with the MMTx s developer (Mr. Divita) and have observed that the HITEx concept mapping capabilities were similar to that of the MMTx. When we analyzed the disagreement between the human gold standard and the NLP program, we found that while HITEx had made some mistakes, the disagreements in a large number of cases were a result of the human expert s extensive domain knowledge. Here are some examples: In one case, COPD was listed as one of the final diagnoses and asthma was not, but the expert chose asthma not COPD as the principal diagnosis. In another case, though the text did not mention anything about smoking, the expert inferred the non-smoking status from the patient s age (5 years old). When the designation of primary and secondary diagnoses not made explicit in the text, the expert could still differentiate them or give label insufficient data. Our NLP program does not have this level of sophistication. Of course, the expert human is not infallible either. In this study, we first used one domain expert as the basis for the gold standard. Because extracting information from text is a tedious task, it was necessary for us to correct some obvious oversights in a second pass. This study over-sampled asthma and COPD cases, which biased the evaluation. This was partially necessary because the prevalence of asthma and COPD in patients was relative low and the prevalence of asthma and COPD related hospitalization was even lower. When we manually reviewed the principal diagnoses of hospitalization in those patients who had at least one asthmaor COPD-related billing code in the past 10 years, we found most of them not caused by asthma or COPD exacerbations. A very large number of hospitalizations appeared to be associated with elderly patients with other serious diseases (e.g. cancer and heart disease). We mainly depended on one expert in the study, though a few other researchers later participated in the review of the gold standard; ideally, at least 3 experts working independently would be desirable. This evaluation gives an estimate of the HITEx extracted data quality for the airways disease project. More rigorously designed evaluations of HITEx are being planned for the future. One issue that deserves further thought is how to establish realistic and reliable gold standards. First, there is inherit ambiguity in text and clinical conditions which need to be accounted for in the gold standard (e.g. differentiate insufficient data from no data ). Second, a domain expert may need to work with lay reviewers to come up with the gold standard for NLP. Domain experts are sometimes influenced by their clinical experience (e.g. most COPD patients to be past or current smoker), while lay reviewers tend to rely on text alone. Although eventually we want to have a computer system to behave like a human expert, NLP is a different task from 8
10 clinical decision making. We should probably not try to build expert knowledge such as bipolar disorder implies smoker into text processing applications these rules may be useful but ideally might be applied in a separate processing step. Finally, in terms of smoking history and status, the generally accepted epidemiological gold standard is patient self-report using a structured and standardized questionnaire. From a practical point of view, it seems difficult to imagine a more reliable gold standard measure than self-report to use in evaluating NLP tools, since most of the text corpora available to us in medical records are created by a health care provider after talking to the patient. Unfortunately, there is a rich literature on recall bias and other problems with this approach, suggesting that this method is not always free from error [28, 29]. Without wishing to engage in debates about what truth really is, it is clear that the task of evaluating any NLP system is made more vexing by the complex layers between the contents of the corpora available and the historical facts as related to a health care provider by a patient. The evaluation helped us identify a few important development areas for HITEx: 1. Accurate identification of negation and uncertainty modifiers: HITEx has a negation finder module that uses the Chapman algorithm [18], the error rate of which is between 5% to 10%. 2. Differentiation between family and personal history: not all diagnosis mentioned referred to the patients. 3. Extraction of temporal modifiers: this is particularly important for interpreting the smoking status correctly. We also recognize the need to create certain post-processing functionalities of HITEx results to support asthma and other research. Taking principal diagnoses extraction for instance, we may train a classifier to perform this task based occurrence frequency when diagnoses are not explicitly labeled as primary or secondary. Conclusions Free text clinical records contain a large amount of useful information, and NLP has the potential to unlock this wealth of information. One challenge with medical NLP tools is that they are not easy to adapt, generalize and reuse. We have developed an open source, reusable, component-based NLP system called HITEx. HITEx was evaluated on 150 discharge summaries and the results were compared to a human-created gold standard. The evaluation showed the accuracy of HITEx in principal diagnosis, co-morbidity and smoking status extraction to be in the 70% to 90% range, generally comparable to a number of previously reported NLP systems. HITEx performed slightly better than ICD9 in diagnosis extraction. Combining HITEx and ICD9 could further improve the accuracy, sensitivity and specificity. We found these results encouraging given the complexity of the tasks, and heterogeneity of the discharge summaries. Competing Interests 9
11 The authors declare that they have no competing interests. Authors Contributions QTZ designed the HITEx system and drafted the manuscript; SG was the main developer of HITEx; SW provided expert review of the discharge summaries; MS was responsible for the smoking status classification module in HITEx; SNM collected the discharge summaries and participated in the evaluation study design; RL conceived the evaluation and helped to draft the manuscript. All authors have read and approved the final manuscript. Acknowledgements All authors on this study were funded by the NIH grant number U54 LM The authors thank Drs Susanne E. Churchill and Isaac Kohane for advice and discussion. References 1. Friedman, C., L. Shagina, Y. Lussier, and G. Hripcsak, Automated encoding of clinical documents based on natural language processing. J Am Med Inform Assoc, (5): p Haug, P.J., S. Koehler, L.M. Lau, P. Wang, R. Rocha, and S.M. Huff, Experience with a mixed semantic/syntactic parser. Proc Annu Symp Comput Appl Med Care, 1995: p Taira, R.K. and S.G. Soderland, A statistical natural language processor for medical reports. Proc AMIA Symp, 1999: p Aronson, A.R., Effective mapping of biomedical text to the UMLS Metathesaurus: the MetaMap program. Proc AMIA Symp, 2001: p Chuang, J.H., C. Friedman, and G. Hripcsak, A comparison of the Charlson comorbidities derived from medical language processing and administrative data. Proc AMIA Symp, 2002: p Fiszman, M., W.W. Chapman, S.R. Evans, and P.J. Haug, Automatic identification of pneumonia related concepts on chest x-ray reports. Proc AMIA Symp, 1999: p Mendonca, E.A., J. Haas, L. Shagina, E. Larson, and C. Friedman, Extracting information on pneumonia in infants using natural language processing of radiology reports. J Biomed Inform, (4): p Xu, H. and C. Friedman, Facilitating research in pathology using natural language processing. AMIA Annu Symp Proc, 2003: p Schadow, G. and C.J. McDonald, Extracting structured information from free text pathology reports. AMIA Annu Symp Proc, 2003: p Mitchell, K.J., M.J. Becich, J.J. Berman, W.W. Chapman, J. Gilbertson, D. Gupta, J. Harrison, E. Legowski, and R.S. Crowley, Implementation and evaluation of a negation tagger in a pipeline-based system for information extract from pathology reports. Medinfo, (Pt 1): p
12 11. Meystre, S. and P.J. Haug, Evaluation of Medical Problem Extraction from Electronic Clinical Documents Using MetaMap Transfer (MMTx). Stud Health Technol Inform, : p Divita, G., T. Tse, and L. Roth, Failure analysis of MetaMap Transfer (MMTx). Medinfo, (Pt 2): p I2B2: Informatics for Integrating Biology & the Bedside [ 14. Cunningham, H., K. Humphreys, R. Gaizauskas, and Y. Wilks. GATE -- a TIPSTERbased General Architecture for Text Engineering. in he TIPSTER Text Program (Phase III) 6 Month Workshop Morgan Kaufmann, California. 15. Sordo, M. and Q. Zeng, On Sample Size and Classification Accuracy: A Performance Comparison. Lecture Notes in Computer Science, / 2005: p Hepple, M. Independence and Commitment: Assumptions for Rapid Training and Execution of Rule-based Part-of-Speech Taggers. in Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics (ACL-2000) Hong Kong. 17. Ramshaw, L. and M. Marcus. Text Chunking Using Transformation-Based Learning. in Third ACL Workshop on Very Large Corpora. 1995: MIT. 18. Chapman, W.W., W. Bridewell, P. Hanbury, G.F. Cooper, and B.G. Buchanan, A simple algorithm for identifying negated findings and diseases in discharge summaries. J Biomed Inform, (5): p Weka 3 - Data Mining with Open Source Machine Learning Software in Java [ 20. Weiss, K.B., Challenges in evaluating and treating asthma. Manag Care, (8 Suppl): p. 8-11; discussion Birman-Deych, E., A.D. Waterman, Y. Yan, D.S. Nilasena, M.J. Radford, and B.F. Gage, Accuracy of ICD-9-CM codes for identifying cardiovascular and stroke risk factors. Med Care, (5): p Bazarian, J.J., P. Veazie, S. Mookerjee, and E.B. Lerner, Accuracy of mild traumatic brain injury case ascertainment using ICD-9 codes. Acad Emerg Med, (1): p O'Malley, K.J., K.F. Cook, M.D. Price, K.R. Wildes, J.F. Hurdle, and C.M. Ashton, Measuring diagnoses: ICD code accuracy. Health Serv Res, (5 Pt 2): p Huang, Y., H.J. Lowe, D. Klein, and R.J. Cucina, Improved identification of noun phrases in clinical radiology reports using a high-performance statistical natural language parser augmented with the UMLS specialist lexicon. J Am Med Inform Assoc, (3): p Chapman, W.W., M. Fiszman, J.N. Dowling, B.E. Chapman, and T.C. Rindflesch, Identifying respiratory findings in emergency department reports for biosurveillance using MetaMap. Medinfo, (Pt 1): p Meystre, S. and P.J. Haug, Automation of a problem list using natural language processing. BMC Med Inform Decis Mak, : p Xu, H., K. Anderson, V.R. Grann, and C. Friedman, Facilitating cancer research using natural language processing of pathology reports. Medinfo, (Pt 1): p Lewis, S.J., N.M. Cherry, L.N.R. Mc, P.V. Barber, K. Wilde, and A.C. Povey, Cotinine levels and self-reported smoking status in patients attending a bronchoscopy clinic. Biomarkers, (3-4): p
13 29. Martinez, M.E., M. Reid, R. Jiang, J. Einspahr, and D.S. Alberts, Accuracy of selfreported smoking status among participants in a chemoprevention trial. Prev Med, (4): p Figures Figure 1 Processing Flow Diagram Tables Table 1 - The accuracy of ICD9, HITEx and the combinations of ICD9 and HITEx for principal diagnosis and co-morbidity extraction. ICD9 HITEx ICD9 and HITEx ICD9 or HITEx Exclude Principal 80.08% 81.64% 75.78% 85.94% Insufficient Data Co-morbidity 82.57% 86.72% 88.80% 80.50% Insufficient Data Principal 71.57% 73.20% 66.34% 78.43% = Yes Co-morbidity 74.18% 77.45% 79.41% 72.22% Insufficient Data Principal 78.76% 79.74% 76.80% 81.70% = No Co-morbidity 83.33% 84.64% 90.52% 77.45% Table 2 - The accuracy of ICD9, HITEx and the combinations of ICD9 and HITEx for principal diagnosis and co-morbidity extraction. Exclude Insufficient Data Insufficient Data = Yes Insufficient Data = No ICD9 (Sens/Spec) Principal 72.52% / 90.91% Co-morbidity 14.81% / 91.12% Principal 60.22% / 90.91% Co-morbidity 11.11% / 90.53% Principal 72.52% / 85.38% Co-morbidity 11.11% / 90.32% HITEx (Sens/Spec) 76.69% / 86.99% 70.37% / 88.79% 63.93% / 86.99% 39.68% / 87.24% 76.69% / 82.08% 66.67% / 86.38% ICD9 and HITEx (Sens/Spec) 56.39% / 96.75% 11.11% / 98.60% 45.90% / 96.75% 04.76% / 98.77% 56.39% / 92.49% 07.41% / 98.57% ICD9 or HITEx (Sens/Spec) 92.42% / 80.99% 74.07% / 81.31% 78.02% / 80.99% 46.03% / 37.86% 92.42% / 74.85% 70.37% / 78.14% Table 3 -The precision of ICD9 and HITEx for principal diagnosis and co-morbidity extraction. ICD9 HITEx ICD9 and ICD9 or 12
14 Exclude Insufficient Data Insufficient HITEx HITEx Principal 82.32% 82.28% 81.06% 87.41% Co-morbidity 53.46% 69.71% 69.88% 64.63% Principal 75.64% 75.03% / 75.01% 78.24% Data = Yes Co-morbidity 50.99% 64.51% 65.00% 60.63% Insufficient Principal 79.69% 79.35% 79.22% 83.19% Data = No Co-morbidity 50.53% 64.11% 62.48% 60.14% Table 4 - The sensitivity and specificity of HITEx for smoking status extraction. Current Smoker Never Smoked Denies Smoking Past Smoker Not mentioned / Insufficient Data Sensitivity 90.32% 60.00% % 77.78% 94.57% Specificity 92.56% 98.60% 99.34% 99.26% 95.08% Table 5 - The precision of HITEx for smoking status extraction. Current Never Denies Past Not Mentioned / Average Smoker Smoked Smoking Smoker Insufficient Data Precision 75.68% 75.00% 66.67% 93.33% 96.67% 81.47% 13
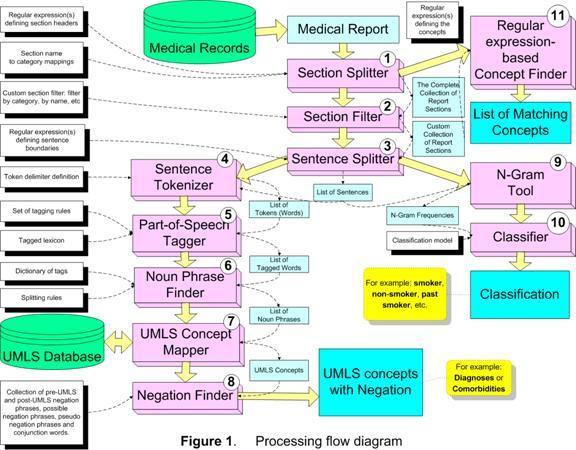
15 Figure 1
Automatic Identification & Classification of Surgical Margin Status from Pathology Reports Following Prostate Cancer Surgery
 Automatic Identification & Classification of Surgical Margin Status from Pathology Reports Following Prostate Cancer Surgery Leonard W. D Avolio MS a,b, Mark S. Litwin MD c, Selwyn O. Rogers Jr. MD, MPH
Automatic Identification & Classification of Surgical Margin Status from Pathology Reports Following Prostate Cancer Surgery Leonard W. D Avolio MS a,b, Mark S. Litwin MD c, Selwyn O. Rogers Jr. MD, MPH
A Study of Abbreviations in Clinical Notes Hua Xu MS, MA 1, Peter D. Stetson, MD, MA 1, 2, Carol Friedman Ph.D. 1
 A Study of Abbreviations in Clinical Notes Hua Xu MS, MA 1, Peter D. Stetson, MD, MA 1, 2, Carol Friedman Ph.D. 1 1 Department of Biomedical Informatics, Columbia University, New York, NY, USA 2 Department
A Study of Abbreviations in Clinical Notes Hua Xu MS, MA 1, Peter D. Stetson, MD, MA 1, 2, Carol Friedman Ph.D. 1 1 Department of Biomedical Informatics, Columbia University, New York, NY, USA 2 Department
A Simple Pipeline Application for Identifying and Negating SNOMED CT in Free Text
 A Simple Pipeline Application for Identifying and Negating SNOMED CT in Free Text Anthony Nguyen 1, Michael Lawley 1, David Hansen 1, Shoni Colquist 2 1 The Australian e-health Research Centre, CSIRO ICT
A Simple Pipeline Application for Identifying and Negating SNOMED CT in Free Text Anthony Nguyen 1, Michael Lawley 1, David Hansen 1, Shoni Colquist 2 1 The Australian e-health Research Centre, CSIRO ICT
Text mining for lung cancer cases over large patient admission data. David Martinez, Lawrence Cavedon, Zaf Alam, Christopher Bain, Karin Verspoor
 Text mining for lung cancer cases over large patient admission data David Martinez, Lawrence Cavedon, Zaf Alam, Christopher Bain, Karin Verspoor Opportunities for Biomedical Informatics Increasing roll-out
Text mining for lung cancer cases over large patient admission data David Martinez, Lawrence Cavedon, Zaf Alam, Christopher Bain, Karin Verspoor Opportunities for Biomedical Informatics Increasing roll-out
Extracting Diagnoses from Discharge Summaries
 Extracting Diagnoses from Discharge Summaries William Long, PhD CSAIL, Massachusetts Institute of Technology, Cambridge, MA, USA Abstract We have developed a program for extracting the diagnoses and procedures
Extracting Diagnoses from Discharge Summaries William Long, PhD CSAIL, Massachusetts Institute of Technology, Cambridge, MA, USA Abstract We have developed a program for extracting the diagnoses and procedures
Analyzing the Semantics of Patient Data to Rank Records of Literature Retrieval
 Proceedings of the Workshop on Natural Language Processing in the Biomedical Domain, Philadelphia, July 2002, pp. 69-76. Association for Computational Linguistics. Analyzing the Semantics of Patient Data
Proceedings of the Workshop on Natural Language Processing in the Biomedical Domain, Philadelphia, July 2002, pp. 69-76. Association for Computational Linguistics. Analyzing the Semantics of Patient Data
Text Mining of Patient Demographics and Diagnoses from Psychiatric Assessments
 University of Wisconsin Milwaukee UWM Digital Commons Theses and Dissertations December 2014 Text Mining of Patient Demographics and Diagnoses from Psychiatric Assessments Eric James Klosterman University
University of Wisconsin Milwaukee UWM Digital Commons Theses and Dissertations December 2014 Text Mining of Patient Demographics and Diagnoses from Psychiatric Assessments Eric James Klosterman University
Query Refinement: Negation Detection and Proximity Learning Georgetown at TREC 2014 Clinical Decision Support Track
 Query Refinement: Negation Detection and Proximity Learning Georgetown at TREC 2014 Clinical Decision Support Track Christopher Wing and Hui Yang Department of Computer Science, Georgetown University,
Query Refinement: Negation Detection and Proximity Learning Georgetown at TREC 2014 Clinical Decision Support Track Christopher Wing and Hui Yang Department of Computer Science, Georgetown University,
Boundary identification of events in clinical named entity recognition
 Boundary identification of events in clinical named entity recognition Azad Dehghan School of Computer Science The University of Manchester Manchester, UK a.dehghan@cs.man.ac.uk Abstract The problem of
Boundary identification of events in clinical named entity recognition Azad Dehghan School of Computer Science The University of Manchester Manchester, UK a.dehghan@cs.man.ac.uk Abstract The problem of
Using Implicit Information to Identify Smoking Status in Smoke-Blind Medical Discharge Summaries
 WICENTOWSKI AND SYDES, Using Implicit Information to Identify Smoking Status in Smoke-Blind Discharge Summaries Technical Brief _ Using Implicit Information to Identify Smoking Status in Smoke-Blind Medical
WICENTOWSKI AND SYDES, Using Implicit Information to Identify Smoking Status in Smoke-Blind Discharge Summaries Technical Brief _ Using Implicit Information to Identify Smoking Status in Smoke-Blind Medical
Chapter 12 Conclusions and Outlook
 Chapter 12 Conclusions and Outlook In this book research in clinical text mining from the early days in 1970 up to now (2017) has been compiled. This book provided information on paper based patient record
Chapter 12 Conclusions and Outlook In this book research in clinical text mining from the early days in 1970 up to now (2017) has been compiled. This book provided information on paper based patient record
On-time clinical phenotype prediction based on narrative reports
 On-time clinical phenotype prediction based on narrative reports Cosmin A. Bejan, PhD 1, Lucy Vanderwende, PhD 2,1, Heather L. Evans, MD, MS 3, Mark M. Wurfel, MD, PhD 4, Meliha Yetisgen-Yildiz, PhD 1,5
On-time clinical phenotype prediction based on narrative reports Cosmin A. Bejan, PhD 1, Lucy Vanderwende, PhD 2,1, Heather L. Evans, MD, MS 3, Mark M. Wurfel, MD, PhD 4, Meliha Yetisgen-Yildiz, PhD 1,5
Lessons Extracting Diseases from Discharge Summaries
 Lessons Extracting Diseases from Discharge Summaries William Long, PhD CSAIL, Massachusetts Institute of Technology, Cambridge, MA, USA Abstract We developed a program to extract diseases and procedures
Lessons Extracting Diseases from Discharge Summaries William Long, PhD CSAIL, Massachusetts Institute of Technology, Cambridge, MA, USA Abstract We developed a program to extract diseases and procedures
Challenges and Practical Approaches with Word Sense Disambiguation of Acronyms and Abbreviations in the Clinical Domain
 Original Article Healthc Inform Res. 2015 January;21(1):35-42. pissn 2093-3681 eissn 2093-369X Challenges and Practical Approaches with Word Sense Disambiguation of Acronyms and Abbreviations in the Clinical
Original Article Healthc Inform Res. 2015 January;21(1):35-42. pissn 2093-3681 eissn 2093-369X Challenges and Practical Approaches with Word Sense Disambiguation of Acronyms and Abbreviations in the Clinical
Retrieving disorders and findings: Results using SNOMED CT and NegEx adapted for Swedish
 Retrieving disorders and findings: Results using SNOMED CT and NegEx adapted for Swedish Maria Skeppstedt 1,HerculesDalianis 1,andGunnarHNilsson 2 1 Department of Computer and Systems Sciences (DSV)/Stockholm
Retrieving disorders and findings: Results using SNOMED CT and NegEx adapted for Swedish Maria Skeppstedt 1,HerculesDalianis 1,andGunnarHNilsson 2 1 Department of Computer and Systems Sciences (DSV)/Stockholm
Atigeo at TREC 2012 Medical Records Track: ICD-9 Code Description Injection to Enhance Electronic Medical Record Search Accuracy
 Atigeo at TREC 2012 Medical Records Track: ICD-9 Code Description Injection to Enhance Electronic Medical Record Search Accuracy Bryan Tinsley, Alex Thomas, Joseph F. McCarthy, Mike Lazarus Atigeo, LLC
Atigeo at TREC 2012 Medical Records Track: ICD-9 Code Description Injection to Enhance Electronic Medical Record Search Accuracy Bryan Tinsley, Alex Thomas, Joseph F. McCarthy, Mike Lazarus Atigeo, LLC
Automatic Identification of Pneumonia Related Concepts on Chest x-ray Reports
 Automatic Identification of Pneumonia Related Concepts on Chest x-ray Reports Marcelo Fiszman MD, Wendy W. Chapman, Scott R. Evans Ph.D., Peter J. Haug MD Department of Medical Informatics, LDS Hospital,
Automatic Identification of Pneumonia Related Concepts on Chest x-ray Reports Marcelo Fiszman MD, Wendy W. Chapman, Scott R. Evans Ph.D., Peter J. Haug MD Department of Medical Informatics, LDS Hospital,
Asthma Surveillance Using Social Media Data
 Asthma Surveillance Using Social Media Data Wenli Zhang 1, Sudha Ram 1, Mark Burkart 2, Max Williams 2, and Yolande Pengetnze 2 University of Arizona 1, PCCI-Parkland Center for Clinical Innovation 2 {wenlizhang,
Asthma Surveillance Using Social Media Data Wenli Zhang 1, Sudha Ram 1, Mark Burkart 2, Max Williams 2, and Yolande Pengetnze 2 University of Arizona 1, PCCI-Parkland Center for Clinical Innovation 2 {wenlizhang,
EDUCATION/TRAINING (Begin with baccalaureate or other initial professional education, such as nursing, and include postdoctoral training.
 NAME Henry Lowe, M.D. BIOGRAPHICAL SKETCH Provide the following information for the key personnel and other significant contributors in the order listed on Form Page 2. Follow this format for each person.
NAME Henry Lowe, M.D. BIOGRAPHICAL SKETCH Provide the following information for the key personnel and other significant contributors in the order listed on Form Page 2. Follow this format for each person.
Not all NLP is Created Equal:
 Not all NLP is Created Equal: CAC Technology Underpinnings that Drive Accuracy, Experience and Overall Revenue Performance Page 1 Performance Perspectives Health care financial leaders and health information
Not all NLP is Created Equal: CAC Technology Underpinnings that Drive Accuracy, Experience and Overall Revenue Performance Page 1 Performance Perspectives Health care financial leaders and health information
How can Natural Language Processing help MedDRA coding? April Andrew Winter Ph.D., Senior Life Science Specialist, Linguamatics
 How can Natural Language Processing help MedDRA coding? April 16 2018 Andrew Winter Ph.D., Senior Life Science Specialist, Linguamatics Summary About NLP and NLP in life sciences Uses of NLP with MedDRA
How can Natural Language Processing help MedDRA coding? April 16 2018 Andrew Winter Ph.D., Senior Life Science Specialist, Linguamatics Summary About NLP and NLP in life sciences Uses of NLP with MedDRA
Pneumonia identification using statistical feature selection
 Pneumonia identification using statistical feature selection Research and applications Cosmin Adrian Bejan, 1 Fei Xia, 1,2 Lucy Vanderwende, 1,3 Mark M Wurfel, 4 Meliha Yetisgen-Yildiz 1,2 < An additional
Pneumonia identification using statistical feature selection Research and applications Cosmin Adrian Bejan, 1 Fei Xia, 1,2 Lucy Vanderwende, 1,3 Mark M Wurfel, 4 Meliha Yetisgen-Yildiz 1,2 < An additional
General Symptom Extraction from VA Electronic Medical Notes
 General Symptom Extraction from VA Electronic Medical Notes Guy Divita a,b, Gang Luo, PhD c, Le-Thuy T. Tran, PhD a,b, T. Elizabeth Workman, PhD a,b, Adi V. Gundlapalli, MD, PhD a,b, Matthew H. Samore,
General Symptom Extraction from VA Electronic Medical Notes Guy Divita a,b, Gang Luo, PhD c, Le-Thuy T. Tran, PhD a,b, T. Elizabeth Workman, PhD a,b, Adi V. Gundlapalli, MD, PhD a,b, Matthew H. Samore,
Modeling Annotator Rationales with Application to Pneumonia Classification
 Modeling Annotator Rationales with Application to Pneumonia Classification Michael Tepper 1, Heather L. Evans 3, Fei Xia 1,2, Meliha Yetisgen-Yildiz 2,1 1 Department of Linguistics, 2 Biomedical and Health
Modeling Annotator Rationales with Application to Pneumonia Classification Michael Tepper 1, Heather L. Evans 3, Fei Xia 1,2, Meliha Yetisgen-Yildiz 2,1 1 Department of Linguistics, 2 Biomedical and Health
Erasmus MC at CLEF ehealth 2016: Concept Recognition and Coding in French Texts
 Erasmus MC at CLEF ehealth 2016: Concept Recognition and Coding in French Texts Erik M. van Mulligen, Zubair Afzal, Saber A. Akhondi, Dang Vo, and Jan A. Kors Department of Medical Informatics, Erasmus
Erasmus MC at CLEF ehealth 2016: Concept Recognition and Coding in French Texts Erik M. van Mulligen, Zubair Afzal, Saber A. Akhondi, Dang Vo, and Jan A. Kors Department of Medical Informatics, Erasmus
Lecture 10: POS Tagging Review. LING 1330/2330: Introduction to Computational Linguistics Na-Rae Han
 Lecture 10: POS Tagging Review LING 1330/2330: Introduction to Computational Linguistics Na-Rae Han Overview Part-of-speech tagging Language and Computers, Ch. 3.4 Tokenization, POS tagging NLTK Book Ch.5
Lecture 10: POS Tagging Review LING 1330/2330: Introduction to Computational Linguistics Na-Rae Han Overview Part-of-speech tagging Language and Computers, Ch. 3.4 Tokenization, POS tagging NLTK Book Ch.5
Detecting Patient Complexity from Free Text Notes Using a Hybrid AI Approach
 Detecting Patient Complexity from Free Text Notes Using a Hybrid AI Approach Malcolm Pradhan, CMO MBBS, PhD, FACHI Daniel Padilla, ML Engineer BEng,, PhD Alcidion Corporation Overview Alcidion s Natural
Detecting Patient Complexity from Free Text Notes Using a Hybrid AI Approach Malcolm Pradhan, CMO MBBS, PhD, FACHI Daniel Padilla, ML Engineer BEng,, PhD Alcidion Corporation Overview Alcidion s Natural
The validity of the diagnosis of inflammatory arthritis in a large population-based primary care database
 Nielen et al. BMC Family Practice 2013, 14:79 RESEARCH ARTICLE Open Access The validity of the diagnosis of inflammatory arthritis in a large population-based primary care database Markus MJ Nielen 1*,
Nielen et al. BMC Family Practice 2013, 14:79 RESEARCH ARTICLE Open Access The validity of the diagnosis of inflammatory arthritis in a large population-based primary care database Markus MJ Nielen 1*,
Comparing ICD9-Encoded Diagnoses and NLP-Processed Discharge Summaries for Clinical Trials Pre-Screening: A Case Study
 Comparing ICD9-Encoded Diagnoses and NLP-Processed Discharge Summaries for Clinical Trials Pre-Screening: A Case Study Li Li, MS, Herbert S. Chase, MD, Chintan O. Patel, MS Carol Friedman, PhD, Chunhua
Comparing ICD9-Encoded Diagnoses and NLP-Processed Discharge Summaries for Clinical Trials Pre-Screening: A Case Study Li Li, MS, Herbert S. Chase, MD, Chintan O. Patel, MS Carol Friedman, PhD, Chunhua
Using Regular Expressions to Abstract Blood Pressure and Treatment Intensification Information from the Text of Physician Notes
 Journal of the American Medical Informatics Association Volume 13 Number 6 Nov / Dec 2006 691 Case Report Using Regular Expressions to Abstract Blood Pressure and Treatment Intensification Information
Journal of the American Medical Informatics Association Volume 13 Number 6 Nov / Dec 2006 691 Case Report Using Regular Expressions to Abstract Blood Pressure and Treatment Intensification Information
BMC Medical Informatics and Decision Making 2011, 11:3
 BMC Medical Informatics and Decision Making This Provisional PDF corresponds to the article as it appeared upon acceptance. Fully formatted PDF and full text (HTML) versions will be made available soon.
BMC Medical Informatics and Decision Making This Provisional PDF corresponds to the article as it appeared upon acceptance. Fully formatted PDF and full text (HTML) versions will be made available soon.
Automatically extracting, ranking and visually summarizing the treatments for a disease
 Automatically extracting, ranking and visually summarizing the treatments for a disease Prakash Reddy Putta, B.Tech 1,2, John J. Dzak III, BS 1, Siddhartha R. Jonnalagadda, PhD 1 1 Division of Health and
Automatically extracting, ranking and visually summarizing the treatments for a disease Prakash Reddy Putta, B.Tech 1,2, John J. Dzak III, BS 1, Siddhartha R. Jonnalagadda, PhD 1 1 Division of Health and
Case-based reasoning using electronic health records efficiently identifies eligible patients for clinical trials
 Case-based reasoning using electronic health records efficiently identifies eligible patients for clinical trials Riccardo Miotto and Chunhua Weng Department of Biomedical Informatics Columbia University,
Case-based reasoning using electronic health records efficiently identifies eligible patients for clinical trials Riccardo Miotto and Chunhua Weng Department of Biomedical Informatics Columbia University,
Classification of Smoking Status: The Case of Turkey
 Classification of Smoking Status: The Case of Turkey Zeynep D. U. Durmuşoğlu Department of Industrial Engineering Gaziantep University Gaziantep, Turkey unutmaz@gantep.edu.tr Pınar Kocabey Çiftçi Department
Classification of Smoking Status: The Case of Turkey Zeynep D. U. Durmuşoğlu Department of Industrial Engineering Gaziantep University Gaziantep, Turkey unutmaz@gantep.edu.tr Pınar Kocabey Çiftçi Department
IBM Research Report. Automated Problem List Generation from Electronic Medical Records in IBM Watson
 RC25496 (WAT1409-068) September 24, 2014 Computer Science IBM Research Report Automated Problem List Generation from Electronic Medical Records in IBM Watson Murthy Devarakonda, Ching-Huei Tsou IBM Research
RC25496 (WAT1409-068) September 24, 2014 Computer Science IBM Research Report Automated Problem List Generation from Electronic Medical Records in IBM Watson Murthy Devarakonda, Ching-Huei Tsou IBM Research
CLAMP-Cancer an NLP tool to facilitate cancer research using EHRs Hua Xu, PhD
 CLAMP-Cancer an NLP tool to facilitate cancer research using EHRs Hua Xu, PhD School of Biomedical Informatics The University of Texas Health Science Center at Houston 1 Advancing Cancer Pharmacoepidemiology
CLAMP-Cancer an NLP tool to facilitate cancer research using EHRs Hua Xu, PhD School of Biomedical Informatics The University of Texas Health Science Center at Houston 1 Advancing Cancer Pharmacoepidemiology
Building a framework for handling clinical abbreviations a long journey of understanding shortened words "
 Building a framework for handling clinical abbreviations a long journey of understanding shortened words " Yonghui Wu 1 PhD, Joshua C. Denny 2 MD MS, S. Trent Rosenbloom 2 MD MPH, Randolph A. Miller 2
Building a framework for handling clinical abbreviations a long journey of understanding shortened words " Yonghui Wu 1 PhD, Joshua C. Denny 2 MD MS, S. Trent Rosenbloom 2 MD MPH, Randolph A. Miller 2
Evaluating Classifiers for Disease Gene Discovery
 Evaluating Classifiers for Disease Gene Discovery Kino Coursey Lon Turnbull khc0021@unt.edu lt0013@unt.edu Abstract Identification of genes involved in human hereditary disease is an important bioinfomatics
Evaluating Classifiers for Disease Gene Discovery Kino Coursey Lon Turnbull khc0021@unt.edu lt0013@unt.edu Abstract Identification of genes involved in human hereditary disease is an important bioinfomatics
Semantic Alignment between ICD-11 and SNOMED-CT. By Marcie Wright RHIA, CHDA, CCS
 Semantic Alignment between ICD-11 and SNOMED-CT By Marcie Wright RHIA, CHDA, CCS World Health Organization (WHO) owns and publishes the International Classification of Diseases (ICD) WHO was entrusted
Semantic Alignment between ICD-11 and SNOMED-CT By Marcie Wright RHIA, CHDA, CCS World Health Organization (WHO) owns and publishes the International Classification of Diseases (ICD) WHO was entrusted
Looking for Subjectivity in Medical Discharge Summaries The Obesity NLP i2b2 Challenge (2008)
") Looking for Subjectivity in Medical Discharge Summaries The Obesity NLP i2b2 Challenge (2008) Michael Roylance and Nicholas Waltner Tuesday 3 rd June, 2014 Michael Roylance and Nicholas Waltner Looking
Looking for Subjectivity in Medical Discharge Summaries The Obesity NLP i2b2 Challenge (2008) Michael Roylance and Nicholas Waltner Tuesday 3 rd June, 2014 Michael Roylance and Nicholas Waltner Looking
Extraction of Adverse Drug Effects from Clinical Records
 MEDINFO 2010 C. Safran et al. (Eds.) IOS Press, 2010 2010 IMIA and SAHIA. All rights reserved. doi:10.3233/978-1-60750-588-4-739 739 Extraction of Adverse Drug Effects from Clinical Records Eiji Aramaki
MEDINFO 2010 C. Safran et al. (Eds.) IOS Press, 2010 2010 IMIA and SAHIA. All rights reserved. doi:10.3233/978-1-60750-588-4-739 739 Extraction of Adverse Drug Effects from Clinical Records Eiji Aramaki
Identifying Adverse Drug Events from Patient Social Media: A Case Study for Diabetes
 Identifying Adverse Drug Events from Patient Social Media: A Case Study for Diabetes Authors: Xiao Liu, Department of Management Information Systems, University of Arizona Hsinchun Chen, Department of
Identifying Adverse Drug Events from Patient Social Media: A Case Study for Diabetes Authors: Xiao Liu, Department of Management Information Systems, University of Arizona Hsinchun Chen, Department of
Clinical Decision Support Technologies for Oncologic Imaging
 Clinical Decision Support Technologies for Oncologic Imaging Ramin Khorasani, MD, MPH Professor of Radiology Harvard Medical School Distinguished Chair, Medical Informatics Vice Chair, Department of Radiology
Clinical Decision Support Technologies for Oncologic Imaging Ramin Khorasani, MD, MPH Professor of Radiology Harvard Medical School Distinguished Chair, Medical Informatics Vice Chair, Department of Radiology
Extracting geographic locations from the literature for virus phylogeography using supervised and distant supervision methods
 Extracting geographic locations from the literature for virus phylogeography using supervised and distant supervision methods D. Weissenbacher 1, A. Sarker 2, T. Tahsin 1, G. Gonzalez 2 and M. Scotch 1
Extracting geographic locations from the literature for virus phylogeography using supervised and distant supervision methods D. Weissenbacher 1, A. Sarker 2, T. Tahsin 1, G. Gonzalez 2 and M. Scotch 1
A Comparison of Collaborative Filtering Methods for Medication Reconciliation
 A Comparison of Collaborative Filtering Methods for Medication Reconciliation Huanian Zheng, Rema Padman, Daniel B. Neill The H. John Heinz III College, Carnegie Mellon University, Pittsburgh, PA, 15213,
A Comparison of Collaborative Filtering Methods for Medication Reconciliation Huanian Zheng, Rema Padman, Daniel B. Neill The H. John Heinz III College, Carnegie Mellon University, Pittsburgh, PA, 15213,
WikiWarsDE: A German Corpus of Narratives Annotated with Temporal Expressions
 WikiWarsDE: A German Corpus of Narratives Annotated with Temporal Expressions Jannik Strötgen, Michael Gertz Institute of Computer Science, Heidelberg University Im Neuenheimer Feld 348, 69120 Heidelberg,
WikiWarsDE: A German Corpus of Narratives Annotated with Temporal Expressions Jannik Strötgen, Michael Gertz Institute of Computer Science, Heidelberg University Im Neuenheimer Feld 348, 69120 Heidelberg,
Unifying Data-Directed and Goal-Directed Control: An Example and Experiments
 Unifying Data-Directed and Goal-Directed Control: An Example and Experiments Daniel D. Corkill, Victor R. Lesser, and Eva Hudlická Department of Computer and Information Science University of Massachusetts
Unifying Data-Directed and Goal-Directed Control: An Example and Experiments Daniel D. Corkill, Victor R. Lesser, and Eva Hudlická Department of Computer and Information Science University of Massachusetts
Symbolic rule-based classification of lung cancer stages from free-text pathology reports
 Symbolic rule-based classification of lung cancer stages from free-text pathology reports Anthony N Nguyen, 1 Michael J Lawley, 1 David P Hansen, 1 Rayleen V Bowman, 2 Belinda E Clarke, 3 Edwina E Duhig,
Symbolic rule-based classification of lung cancer stages from free-text pathology reports Anthony N Nguyen, 1 Michael J Lawley, 1 David P Hansen, 1 Rayleen V Bowman, 2 Belinda E Clarke, 3 Edwina E Duhig,
How preferred are preferred terms?
 How preferred are preferred terms? Gintare Grigonyte 1, Simon Clematide 2, Fabio Rinaldi 2 1 Computational Linguistics Group, Department of Linguistics, Stockholm University Universitetsvagen 10 C SE-106
How preferred are preferred terms? Gintare Grigonyte 1, Simon Clematide 2, Fabio Rinaldi 2 1 Computational Linguistics Group, Department of Linguistics, Stockholm University Universitetsvagen 10 C SE-106
An Intelligent Writing Assistant Module for Narrative Clinical Records based on Named Entity Recognition and Similarity Computation
 An Intelligent Writing Assistant Module for Narrative Clinical Records based on Named Entity Recognition and Similarity Computation 1,2,3 EMR and Intelligent Expert System Engineering Research Center of
An Intelligent Writing Assistant Module for Narrative Clinical Records based on Named Entity Recognition and Similarity Computation 1,2,3 EMR and Intelligent Expert System Engineering Research Center of
Learning to Use Episodic Memory
 Learning to Use Episodic Memory Nicholas A. Gorski (ngorski@umich.edu) John E. Laird (laird@umich.edu) Computer Science & Engineering, University of Michigan 2260 Hayward St., Ann Arbor, MI 48109 USA Abstract
Learning to Use Episodic Memory Nicholas A. Gorski (ngorski@umich.edu) John E. Laird (laird@umich.edu) Computer Science & Engineering, University of Michigan 2260 Hayward St., Ann Arbor, MI 48109 USA Abstract
A long journey to short abbreviations: developing an open-source framework for clinical abbreviation recognition and disambiguation (CARD)
") Journal of the American Medical Informatics Association, 24(e1), 2017, e79 e86 doi: 10.1093/jamia/ocw109 Advance Access Publication Date: 18 August 2016 Research and Applications Research and Applications
Journal of the American Medical Informatics Association, 24(e1), 2017, e79 e86 doi: 10.1093/jamia/ocw109 Advance Access Publication Date: 18 August 2016 Research and Applications Research and Applications
Collaborative Project of the 7th Framework Programme. WP6: Tools for bio-researchers and clinicians
 G.A. nº 270086 Collaborative Project of the 7th Framework Programme WP6: Tools for bio-researchers and clinicians Deliverable 6.1: Design of Inference Engine v.1.0 31/10/2011 www.synergy-copd.eu Document
G.A. nº 270086 Collaborative Project of the 7th Framework Programme WP6: Tools for bio-researchers and clinicians Deliverable 6.1: Design of Inference Engine v.1.0 31/10/2011 www.synergy-copd.eu Document
DOWNLOAD EASYCIE AND DATASET
 DOWNLOAD EASYCIE AND DATASET https://goo.gl/evdf1c https://goo.gl/xjr7xe EASYCIE: A DEVELOPMENT PLATFORM TO SUPPORT QUICK AND EASY, RULE-BASED CLINICAL INFORMATION EXTRACTION JIANLIN SHI, MS MD DANIELLE
DOWNLOAD EASYCIE AND DATASET https://goo.gl/evdf1c https://goo.gl/xjr7xe EASYCIE: A DEVELOPMENT PLATFORM TO SUPPORT QUICK AND EASY, RULE-BASED CLINICAL INFORMATION EXTRACTION JIANLIN SHI, MS MD DANIELLE
Bayesian Networks in Medicine: a Model-based Approach to Medical Decision Making
 Bayesian Networks in Medicine: a Model-based Approach to Medical Decision Making Peter Lucas Department of Computing Science University of Aberdeen Scotland, UK plucas@csd.abdn.ac.uk Abstract Bayesian
Bayesian Networks in Medicine: a Model-based Approach to Medical Decision Making Peter Lucas Department of Computing Science University of Aberdeen Scotland, UK plucas@csd.abdn.ac.uk Abstract Bayesian
SAGE. Nick Beard Vice President, IDX Systems Corp.
 SAGE Nick Beard Vice President, IDX Systems Corp. Sharable Active Guideline Environment An R&D consortium to develop the technology infrastructure to enable computable clinical guidelines, that will be
SAGE Nick Beard Vice President, IDX Systems Corp. Sharable Active Guideline Environment An R&D consortium to develop the technology infrastructure to enable computable clinical guidelines, that will be
Clinical Narrative Analytics Challenges
 Clinical Narrative Analytics Challenges Ernestina Menasalvas (B), Alejandro Rodriguez-Gonzalez, Roberto Costumero, Hector Ambit, and Consuelo Gonzalo Centro de Tecnología Biomédica, Universidad Politécnica
Clinical Narrative Analytics Challenges Ernestina Menasalvas (B), Alejandro Rodriguez-Gonzalez, Roberto Costumero, Hector Ambit, and Consuelo Gonzalo Centro de Tecnología Biomédica, Universidad Politécnica
Analysis of Semantic Classes in Medical Text for Question Answering
 Analysis of Semantic Classes in Medical Text for Question Answering Yun Niu and Graeme Hirst Department of Computer Science University of Toronto Toronto, Ontario M5S 3G4 Canada yun@cs.toronto.edu, gh@cs.toronto.edu
Analysis of Semantic Classes in Medical Text for Question Answering Yun Niu and Graeme Hirst Department of Computer Science University of Toronto Toronto, Ontario M5S 3G4 Canada yun@cs.toronto.edu, gh@cs.toronto.edu
Use of Online Resources While Using a Clinical Information System
 Use of Online Resources While Using a Clinical Information System James J. Cimino, MD; Jianhua Li, MD; Mark Graham, PhD, Leanne M. Currie, RN, MS; Mureen Allen, MB BS, Suzanne Bakken, RN, DNSc, Vimla L.
Use of Online Resources While Using a Clinical Information System James J. Cimino, MD; Jianhua Li, MD; Mark Graham, PhD, Leanne M. Currie, RN, MS; Mureen Allen, MB BS, Suzanne Bakken, RN, DNSc, Vimla L.
Clinician-Driven Automated Classification of Limb Fractures from Free-Text Radiology Reports
 Clinician-Driven Automated Classification of Limb Fractures from Free-Text Radiology Reports Amol Wagholikar 1, Guido Zuccon 1, Anthony Nguyen 1, Kevin Chu 2, Shane Martin 2, Kim Lai 2, Jaimi Greenslade
Clinician-Driven Automated Classification of Limb Fractures from Free-Text Radiology Reports Amol Wagholikar 1, Guido Zuccon 1, Anthony Nguyen 1, Kevin Chu 2, Shane Martin 2, Kim Lai 2, Jaimi Greenslade
Truth Versus Truthiness in Clinical Data
 Temple University Health System Truth Versus Truthiness in Clinical Data Mark Weiner, MD, FACP, FACMI Assistant Dean for Informatics, Temple University School of Medicine mark.weiner@tuhs.temple.edu 1
Temple University Health System Truth Versus Truthiness in Clinical Data Mark Weiner, MD, FACP, FACMI Assistant Dean for Informatics, Temple University School of Medicine mark.weiner@tuhs.temple.edu 1
Annotating Temporal Relations to Determine the Onset of Psychosis Symptoms
 Annotating Temporal Relations to Determine the Onset of Psychosis Symptoms Natalia Viani, PhD IoPPN, King s College London Introduction: clinical use-case For patients with schizophrenia, longer durations
Annotating Temporal Relations to Determine the Onset of Psychosis Symptoms Natalia Viani, PhD IoPPN, King s College London Introduction: clinical use-case For patients with schizophrenia, longer durations
Bellagio, Las Vegas November 26-28, Patricia Davis Computer-assisted Coding Blazing a Trail to ICD 10
 Bellagio, Las Vegas November 26-28, 2012 Patricia Davis Computer-assisted Coding Blazing a Trail to ICD 10 2 Publisher s Notice Although we have tried to include accurate and comprehensive information
Bellagio, Las Vegas November 26-28, 2012 Patricia Davis Computer-assisted Coding Blazing a Trail to ICD 10 2 Publisher s Notice Although we have tried to include accurate and comprehensive information
How to Advance Beyond Regular Data with Text Analytics
 Session #34 How to Advance Beyond Regular Data with Text Analytics Mike Dow Director, Product Development, Health Catalyst Carolyn Wong Simpkins, MD, PhD Chief Medical Informatics Officer, Health Catalyst
Session #34 How to Advance Beyond Regular Data with Text Analytics Mike Dow Director, Product Development, Health Catalyst Carolyn Wong Simpkins, MD, PhD Chief Medical Informatics Officer, Health Catalyst
The Impact of Belief Values on the Identification of Patient Cohorts
 The Impact of Belief Values on the Identification of Patient Cohorts Travis Goodwin, Sanda M. Harabagiu Human Language Technology Research Institute University of Texas at Dallas Richardson TX, 75080 {travis,sanda}@hlt.utdallas.edu
The Impact of Belief Values on the Identification of Patient Cohorts Travis Goodwin, Sanda M. Harabagiu Human Language Technology Research Institute University of Texas at Dallas Richardson TX, 75080 {travis,sanda}@hlt.utdallas.edu
Cardiac Risk Prediction Analysis Using Spark Python (PySpark)
") Cardiac Prediction Analysis Using Spark Python (PySpark) G.Tirupati, Prof. K.Venkata Rao Abstract-Cardiovascular disease is the acute disorder in the world today. Disease control and early diagnosis of
Cardiac Prediction Analysis Using Spark Python (PySpark) G.Tirupati, Prof. K.Venkata Rao Abstract-Cardiovascular disease is the acute disorder in the world today. Disease control and early diagnosis of
Clinical Narratives Context Categorization: The Clinician Approach using RapidMiner
 , pp.128-138 http://dx.doi.org/10.14257/astl.2014.51.30 Clinical Narratives Context Categorization: The Clinician Approach using RapidMiner Osama Mohammed 1, Sabah Mohammed 2, Jinan Fiaidhi 2, Simon Fong
, pp.128-138 http://dx.doi.org/10.14257/astl.2014.51.30 Clinical Narratives Context Categorization: The Clinician Approach using RapidMiner Osama Mohammed 1, Sabah Mohammed 2, Jinan Fiaidhi 2, Simon Fong
Lung Cancer Concept Annotation from Spanish Clinical Narratives
 Lung Cancer Concept Annotation from Spanish Clinical Narratives Marjan Najafabadipour 1, [0000-0002-1428-9330], Juan Manuel Tuñas 1[0000-0001-8241-5602], Alejandro Rodríguez-González 1,2,* [0000-0001-8801-4762]
Lung Cancer Concept Annotation from Spanish Clinical Narratives Marjan Najafabadipour 1, [0000-0002-1428-9330], Juan Manuel Tuñas 1[0000-0001-8241-5602], Alejandro Rodríguez-González 1,2,* [0000-0001-8801-4762]
Running Head: AUTOMATED SCORING OF CONSTRUCTED RESPONSE ITEMS. Contract grant sponsor: National Science Foundation; Contract grant number:
 Running Head: AUTOMATED SCORING OF CONSTRUCTED RESPONSE ITEMS Rutstein, D. W., Niekrasz, J., & Snow, E. (2016, April). Automated scoring of constructed response items measuring computational thinking.
Running Head: AUTOMATED SCORING OF CONSTRUCTED RESPONSE ITEMS Rutstein, D. W., Niekrasz, J., & Snow, E. (2016, April). Automated scoring of constructed response items measuring computational thinking.
This is a repository copy of Measuring the effect of public health campaigns on Twitter: the case of World Autism Awareness Day.
 This is a repository copy of Measuring the effect of public health campaigns on Twitter: the case of World Autism Awareness Day. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/127215/
This is a repository copy of Measuring the effect of public health campaigns on Twitter: the case of World Autism Awareness Day. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/127215/
An Ontology for Healthcare Quality Indicators: Challenges for Semantic Interoperability
 414 Digital Healthcare Empowering Europeans R. Cornet et al. (Eds.) 2015 European Federation for Medical Informatics (EFMI). This article is published online with Open Access by IOS Press and distributed
414 Digital Healthcare Empowering Europeans R. Cornet et al. (Eds.) 2015 European Federation for Medical Informatics (EFMI). This article is published online with Open Access by IOS Press and distributed
Building a Diseases Symptoms Ontology for Medical Diagnosis: An Integrative Approach
 Building a Diseases Symptoms Ontology for Medical Diagnosis: An Integrative Approach Osama Mohammed, Rachid Benlamri and Simon Fong* Department of Software Engineering, Lakehead University, Ontario, Canada
Building a Diseases Symptoms Ontology for Medical Diagnosis: An Integrative Approach Osama Mohammed, Rachid Benlamri and Simon Fong* Department of Software Engineering, Lakehead University, Ontario, Canada
Clinical Event Detection with Hybrid Neural Architecture
 Clinical Event Detection with Hybrid Neural Architecture Adyasha Maharana Biomedical and Health Informatics University of Washington, Seattle adyasha@uw.edu Meliha Yetisgen Biomedical and Health Informatics
Clinical Event Detection with Hybrid Neural Architecture Adyasha Maharana Biomedical and Health Informatics University of Washington, Seattle adyasha@uw.edu Meliha Yetisgen Biomedical and Health Informatics
Introduction to the Partners Biobank Portal. December 2016
 Introduction to the Partners Biobank Portal December 2016 Agenda About the Partners Biobank About the Biobank Portal Data Types in the Biobank Sample types DNA. Plasma and Serum Consent Genomic Data Health
Introduction to the Partners Biobank Portal December 2016 Agenda About the Partners Biobank About the Biobank Portal Data Types in the Biobank Sample types DNA. Plasma and Serum Consent Genomic Data Health
Problem-Oriented Patient Record Summary: An Early Report on a Watson Application
 Problem-Oriented Patient Record Summary: An Early Report on a Watson Application Murthy Devarakonda, Dongyang Zhang, Ching-Huei Tsou, Mihaela Bornea IBM Research and Watson Group Yorktown Heights, NY Abstract
Problem-Oriented Patient Record Summary: An Early Report on a Watson Application Murthy Devarakonda, Dongyang Zhang, Ching-Huei Tsou, Mihaela Bornea IBM Research and Watson Group Yorktown Heights, NY Abstract
Making the Best Use of Textual ED Data for Syndromic Surveillance
 Making the Best Use of Textual ED Data for Syndromic Surveillance Debbie Travers, PhD, RN, FAEN, CEN Associate Professor, Health Care Systems & Emergency Medicine Faculty, Carolina Health Informatics Program
Making the Best Use of Textual ED Data for Syndromic Surveillance Debbie Travers, PhD, RN, FAEN, CEN Associate Professor, Health Care Systems & Emergency Medicine Faculty, Carolina Health Informatics Program
COMPARISON OF BREAST CANCER STAGING IN NATURAL LANGUAGE TEXT AND SNOMED ANNOTATED TEXT
 Volume 116 No. 21 2017, 243-249 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu COMPARISON OF BREAST CANCER STAGING IN NATURAL LANGUAGE TEXT AND SNOMED
Volume 116 No. 21 2017, 243-249 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu COMPARISON OF BREAST CANCER STAGING IN NATURAL LANGUAGE TEXT AND SNOMED
Applied Machine Learning, Lecture 11: Ethical and legal considerations; domain effects and domain adaptation
 Applied Machine Learning, Lecture 11: Ethical and legal considerations; domain effects and domain adaptation Richard Johansson including some slides borrowed from Barbara Plank overview introduction bias
Applied Machine Learning, Lecture 11: Ethical and legal considerations; domain effects and domain adaptation Richard Johansson including some slides borrowed from Barbara Plank overview introduction bias
Shades of Certainty Working with Swedish Medical Records and the Stockholm EPR Corpus
 Shades of Certainty Working with Swedish Medical Records and the Stockholm EPR Corpus Sumithra VELUPILLAI, Ph.D. Oslo, May 30 th 2012 Health Care Analytics and Modeling, Dept. of Computer and Systems Sciences
Shades of Certainty Working with Swedish Medical Records and the Stockholm EPR Corpus Sumithra VELUPILLAI, Ph.D. Oslo, May 30 th 2012 Health Care Analytics and Modeling, Dept. of Computer and Systems Sciences
Hypothesis-Driven Research
 Hypothesis-Driven Research Research types Descriptive science: observe, describe and categorize the facts Discovery science: measure variables to decide general patterns based on inductive reasoning Hypothesis-driven
Hypothesis-Driven Research Research types Descriptive science: observe, describe and categorize the facts Discovery science: measure variables to decide general patterns based on inductive reasoning Hypothesis-driven
From Guidelines To Decision Support A Systematic and Replicable Approach To Guideline Knowledge Transformation
 From Guidelines To Decision Support A Systematic and Replicable Approach To Guideline Knowledge Transformation GLIDES PROJECT GuideLines Into DEcision Support sponsored by the Agency for HealthCare Research
From Guidelines To Decision Support A Systematic and Replicable Approach To Guideline Knowledge Transformation GLIDES PROJECT GuideLines Into DEcision Support sponsored by the Agency for HealthCare Research
A Descriptive Delta for Identifying Changes in SNOMED CT
 A Descriptive Delta for Identifying Changes in SNOMED CT Christopher Ochs, Yehoshua Perl, Gai Elhanan Department of Computer Science New Jersey Institute of Technology Newark, NJ, USA {cro3, perl, elhanan}@njit.edu
A Descriptive Delta for Identifying Changes in SNOMED CT Christopher Ochs, Yehoshua Perl, Gai Elhanan Department of Computer Science New Jersey Institute of Technology Newark, NJ, USA {cro3, perl, elhanan}@njit.edu
A Method for Analyzing Commonalities in Clinical Trial Target Populations
 A Method for Analyzing Commonalities in Clinical Trial Target Populations Zhe (Henry) He 1, Simona Carini 2, Tianyong Hao 1, Ida Sim 2, and Chunhua Weng 1 1 Department of Biomedical Informatics, Columbia
A Method for Analyzing Commonalities in Clinical Trial Target Populations Zhe (Henry) He 1, Simona Carini 2, Tianyong Hao 1, Ida Sim 2, and Chunhua Weng 1 1 Department of Biomedical Informatics, Columbia
Automatic abstraction of imaging observations with their characteristics from mammography reports
 Journal of the American Medical Informatics Association Advance Access published November 13, 2014 Research and applications Automatic abstraction of imaging observations with their characteristics from
Journal of the American Medical Informatics Association Advance Access published November 13, 2014 Research and applications Automatic abstraction of imaging observations with their characteristics from
The Unreasonable Effectiveness of Data Clinical
 The Unreasonable Effectiveness of Data Clinical Peter Szolovits MIT Computer Science and Artificial Intelligence Lab Professor of Computer Science and Engineering Professor of Health Sciences and Technology,
The Unreasonable Effectiveness of Data Clinical Peter Szolovits MIT Computer Science and Artificial Intelligence Lab Professor of Computer Science and Engineering Professor of Health Sciences and Technology,
CYSTIC FIBROSIS. The condition:
 CYSTIC FIBROSIS Both antenatal and neonatal screening for CF have been considered. Antenatal screening aims to identify fetuses affected by CF so that parents can be offered an informed choice as to whether
CYSTIC FIBROSIS Both antenatal and neonatal screening for CF have been considered. Antenatal screening aims to identify fetuses affected by CF so that parents can be offered an informed choice as to whether
A review of approaches to identifying patient phenotype cohorts using electronic health records
 A review of approaches to identifying patient phenotype cohorts using electronic health records Shivade, Raghavan, Fosler-Lussier, Embi, Elhadad, Johnson, Lai Chaitanya Shivade JAMIA Journal Club March
A review of approaches to identifying patient phenotype cohorts using electronic health records Shivade, Raghavan, Fosler-Lussier, Embi, Elhadad, Johnson, Lai Chaitanya Shivade JAMIA Journal Club March
Open Research Online The Open University s repository of research publications and other research outputs
 Open Research Online The Open University s repository of research publications and other research outputs Toward Emotionally Accessible Massive Open Online Courses (MOOCs) Conference or Workshop Item How
Open Research Online The Open University s repository of research publications and other research outputs Toward Emotionally Accessible Massive Open Online Courses (MOOCs) Conference or Workshop Item How
PROPOSED WORK PROGRAMME FOR THE CLEARING-HOUSE MECHANISM IN SUPPORT OF THE STRATEGIC PLAN FOR BIODIVERSITY Note by the Executive Secretary
 CBD Distr. GENERAL UNEP/CBD/COP/11/31 30 July 2012 ORIGINAL: ENGLISH CONFERENCE OF THE PARTIES TO THE CONVENTION ON BIOLOGICAL DIVERSITY Eleventh meeting Hyderabad, India, 8 19 October 2012 Item 3.2 of
CBD Distr. GENERAL UNEP/CBD/COP/11/31 30 July 2012 ORIGINAL: ENGLISH CONFERENCE OF THE PARTIES TO THE CONVENTION ON BIOLOGICAL DIVERSITY Eleventh meeting Hyderabad, India, 8 19 October 2012 Item 3.2 of
Innovative Risk and Quality Solutions for Value-Based Care. Company Overview
 Innovative Risk and Quality Solutions for Value-Based Care Company Overview Meet Talix Talix provides risk and quality solutions to help providers, payers and accountable care organizations address the
Innovative Risk and Quality Solutions for Value-Based Care Company Overview Meet Talix Talix provides risk and quality solutions to help providers, payers and accountable care organizations address the
Holt McDougal Avancemos!, Level correlated to the. Crosswalk Alignment of the National Standards for Learning Languages
 Holt McDougal Avancemos!, Level 1 2013 correlated to the Crosswalk Alignment of the National Standards for Learning Languages READING 1. Read closely to determine what the text says explicitly and to make
Holt McDougal Avancemos!, Level 1 2013 correlated to the Crosswalk Alignment of the National Standards for Learning Languages READING 1. Read closely to determine what the text says explicitly and to make
Measuring the quality of colonoscopy: Where are we now and where are we going?
 Measuring the quality of colonoscopy: Where are we now and where are we going? Timothy D. Imler, MD Division of Gastroenterology and Hepatology, Indiana University School of Medicine, Indianapolis, Indiana
Measuring the quality of colonoscopy: Where are we now and where are we going? Timothy D. Imler, MD Division of Gastroenterology and Hepatology, Indiana University School of Medicine, Indianapolis, Indiana
Curriculum Vitae. Degree and date to be conferred: Masters in Computer Science, 2013.
 i Curriculum Vitae Name: Deepal Dhariwal. Degree and date to be conferred: Masters in Computer Science, 2013. Secondary education: Dr. Kalmadi Shamarao High School, Pune, 2005 Fergusson College, Pune 2007
i Curriculum Vitae Name: Deepal Dhariwal. Degree and date to be conferred: Masters in Computer Science, 2013. Secondary education: Dr. Kalmadi Shamarao High School, Pune, 2005 Fergusson College, Pune 2007
Holt McDougal Avancemos!, Level correlated to the. Crosswalk Alignment of the National Standards for Learning Languages
 Holt McDougal Avancemos!, Level 2 2013 correlated to the Crosswalk Alignment of the National Standards for Learning Languages with the Common Core State Standards READING 1. Read closely to determine what
Holt McDougal Avancemos!, Level 2 2013 correlated to the Crosswalk Alignment of the National Standards for Learning Languages with the Common Core State Standards READING 1. Read closely to determine what
The Cochrane Collaboration
 The Cochrane Collaboration Version and date: V1, 29 October 2012 Guideline notes for consumer referees You have been invited to provide consumer comments on a Cochrane Review or Cochrane Protocol. This
The Cochrane Collaboration Version and date: V1, 29 October 2012 Guideline notes for consumer referees You have been invited to provide consumer comments on a Cochrane Review or Cochrane Protocol. This
Identifying Deviations from Usual Medical Care using a Statistical Approach
 Identifying Deviations from Usual Medical Care using a Statistical Approach Shyam Visweswaran, MD, PhD 1, James Mezger, MD, MS 2, Gilles Clermont, MD, MSc 3, Milos Hauskrecht, PhD 4, Gregory F. Cooper,
Identifying Deviations from Usual Medical Care using a Statistical Approach Shyam Visweswaran, MD, PhD 1, James Mezger, MD, MS 2, Gilles Clermont, MD, MSc 3, Milos Hauskrecht, PhD 4, Gregory F. Cooper,
Factuality Levels of Diagnoses in Swedish Clinical Text
 User Centred Networked Health Care A. Moen et al. (Eds.) IOS Press, 2011 2011 European Federation for Medical Informatics. All rights reserved. doi:10.3233/978-1-60750-806-9-559 559 Factuality Levels of
User Centred Networked Health Care A. Moen et al. (Eds.) IOS Press, 2011 2011 European Federation for Medical Informatics. All rights reserved. doi:10.3233/978-1-60750-806-9-559 559 Factuality Levels of
Extending the GuideLine Implementability Appraisal (GLIA) instrument to identify problems in control flow
 instrument to identify problems in control flow") Extending the GuideLine Implementability Appraisal (GLIA) instrument to identify problems in control flow Mor Peleg, Ph.D., Jeffrey R. Garber, M.D., F.A.C.P., F.A.C.E. Department of Management Information
Extending the GuideLine Implementability Appraisal (GLIA) instrument to identify problems in control flow Mor Peleg, Ph.D., Jeffrey R. Garber, M.D., F.A.C.P., F.A.C.E. Department of Management Information
Loose Tweets: An Analysis of Privacy Leaks on Twitter
 Loose Tweets: An Analysis of Privacy Leaks on Twitter Huina Mao, Xin Shuai, Apu Kapadia WPES 2011 Presented by Luam C. Totti on May 9, 2012 Motivation 65 million tweets every day. How many contain sensitive
Loose Tweets: An Analysis of Privacy Leaks on Twitter Huina Mao, Xin Shuai, Apu Kapadia WPES 2011 Presented by Luam C. Totti on May 9, 2012 Motivation 65 million tweets every day. How many contain sensitive
Expert System Profile
 Expert System Profile GENERAL Domain: Medical Main General Function: Diagnosis System Name: INTERNIST-I/ CADUCEUS (or INTERNIST-II) Dates: 1970 s 1980 s Researchers: Ph.D. Harry Pople, M.D. Jack D. Myers
Expert System Profile GENERAL Domain: Medical Main General Function: Diagnosis System Name: INTERNIST-I/ CADUCEUS (or INTERNIST-II) Dates: 1970 s 1980 s Researchers: Ph.D. Harry Pople, M.D. Jack D. Myers