Broadband Wireless Access and Applications Center (BWAC) CUA Site Planning Workshop
|
|
|
- Frederica Morrison
- 5 years ago
- Views:
Transcription
 CUA Site Planning Workshop")

1 Broadband Wireless Access and Applications Center (BWAC) CUA Site Planning Workshop Lin-Ching Chang Department of Electrical Engineering and Computer Science School of Engineering





2 Work Experience 09/12-present, Associate Professor, EECS, CUA 09/07-08/12, Assistant Professor, EECS, CUA 09/03-08/07, IRTA Postdoctoral Fellow, NIH 03/03-08/03, Senior Software Programmer and Medical Image Analyst, NIH 03/99-02/03, Senior Software Engineer, 3Com Corporation 2





3 Research Experience Overview Pattern recognition Image processing Big-data analysis Medical informatics Parallel processing Telecommunication Medical Image Processing and Analysis Diffusion Tensor MRI Spectral Image Stack Decision map Generate raw images Source Images ICA Unmix Compute XCNR & Decision maps ICA Results Estimate Noise Denoised Images Noise standard deviations ROI Masks Microscopic Image Processing & Analysis Two-Photo Microscopy Imaging GPU Hardware Acceleration Solar Image Processing & Analysis Coronal Mass Ejections 3
4 Adapted HMM for Robust Speech Recognition
5 The Benefits of Effective Speech Recognition Benefits can vary based on industries Work processes become more efficient Save a great deal of labor Save a great deal of time Hand free computing - voice dictations from digital dictation devices Speech recognition is fun - nothing is more fascinating than the quick transformation of spoken words into readable text. However, Speech recognition has the chance to cause increased frustration for the users/customers 5
6 LVCSR Large Vocabulary Continuous Speech Recognition (LVCSR) ~20,000-64,000 words Speaker independent (vs. speaker-dependent) Continuous speech (vs isolated-word) 6
7 Word error rates Ballpark numbers; exact numbers depend very much on the specific corpus Task Vocabulary Error Rate% Digits WSJ read speech (clean) ~ WSJ read speech (clean) ~20, Broadcast news ~64, Conversational Telephone ~64, *WSJ: Wall Street Journal 7
8 HSR versus ASR Task Vocab ASR Hum SR Continuous digits WSJ clean 5K WSJ w/noise 5K SWBD 65K 20 4 Conclusions: Machines are about 5 times worse than humans Gap increases with noisy speech These numbers are rough, take with grain of salt Error Rate (%) *SWBD: Switchboard database human-to-human telephone conversations 8

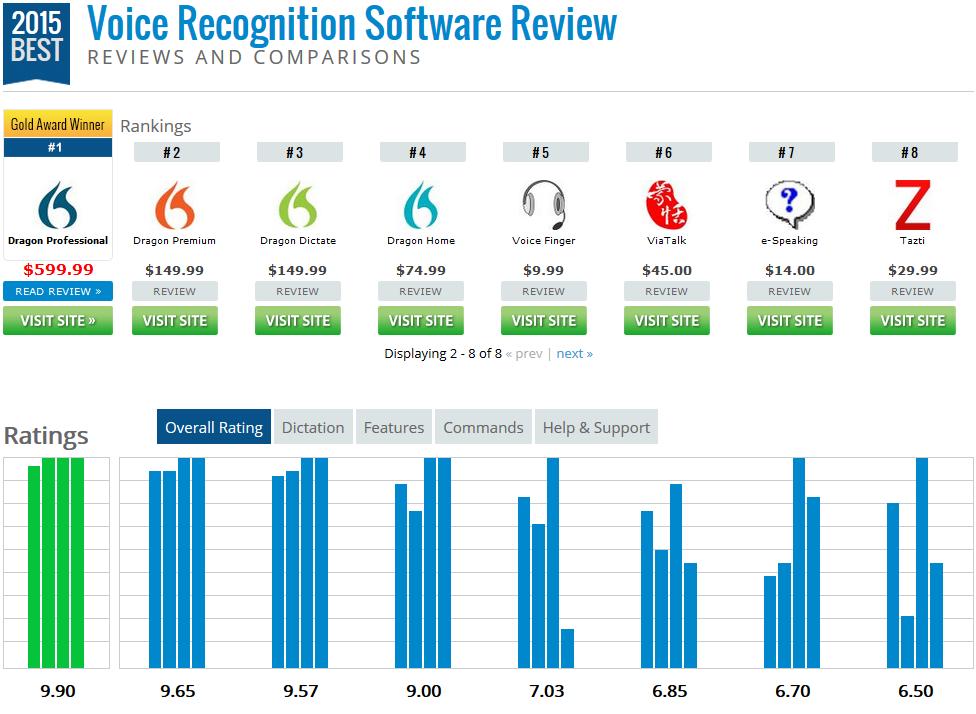
9 ASR Today 9

10 Accuracy ranged 60%~95% 10
11 Challenges in the Design of a SR System SR systems have to deal with a large number of challenges The speaker s voice is often accompanied by surrounding noise which makes their accurate recognition difficult. A speaker may speak a number of different words and all of these words have to be accurately recognized. Accent of speaking varies from person to person and this is a very big challenge A speaker may speak something very quickly and all of the words spoken have to be individually recognized accurately. 11







12 Types of SR Systems Speaker Dependent SR systems Work by learning the unique characteristics of a single person s voice and depend on the speaker for training. Speaker Independent SR systems Designed to recognize anyone s voice, so no training is involved. 12


13 SIRI and GOOGLE NOW Intelligent Personal Assistant developed by Apple. Google Now is an intelligent personal assistant developed by Google. Both use a combination of speaker- dependent and speaker- independent speech recognition systems 13
14 Applications Health Care - Medical documentation - Therapeutic use In-car Systems Military - High performance aircrafts - Air traffic control systems Telephony - Smart-phones - Customer Helpline Services Usage in Education People with Disabilities Daily Life 14
15 Speech Recognition for Healthcare Speech recognition drives efficiencies and cost savings in clinical documentation by turning clinician dictations into formatted documents -- automatically. Front-end speech recognition allows clinicians to dictate, self-edit and sign transcription-free, completed reports in one sitting directly into a PACS system or EHR. Background speech recognition clinician dictation into speech-recognized first drafts that medical language specialists (MLS) edit it later. 15
16 Speech Recognition for Healthcare Benefits Reduce document turnaround times Save on transcription costs - significantly Enhance patient care through increased clinical record accuracy, inclusiveness and access Dictate directly into the EHR with front-end speech recognition Accelerate EHR navigation within the EHR, saving physicians time Increase clinician satisfaction and EHR adoption Employ multiple dictation options including phone, dictation devices, and workstations Several studies shows speech recognition leads to imaging report errors Basma S1, Lord B, Jacks LM, Rizk M, Scaranelo AM., Error rates in breast imaging reports: comparison of automatic speech recognition and dictation transcription. AJR Am J Roentgenol Oct;197(4):
17 Common Error Types Word omission Word substitution Nonsense phrase Wrong word Punctuation error Incorrect measurement (mm/cm) Missing or added no Added word Verb tense Plural Spelling mistake Incomplete phrase Conclusion of their study Complex breast imaging reports generated with ASR were associated with higher error rates (3~8 times higher) than reports generated with conventional dictation transcription. Basma S1, Lord B, Jacks LM, Rizk M, Scaranelo AM., Error rates in breast imaging reports: comparison of automatic speech recognition and dictation transcription. AJR Am J Roentgenol Oct;197(4):
18 Hidden Markov Model (HMM) Markov models are excellent ways of abstracting simple concepts into a relatively easily computable form. Used in data compression to sound recognition. From this graph we can create sequences such as: N1 N2 N3 N1 N2 N2 N2 N3 N3 N3 N3 N3 N1 N1 N2 N2 N3 18

19 Hidden Markov Model (HMM) N1 N2 N3 = 0.4 X 0.8 X 0.5 = 0.16 N1 N2 N2 N2 N3 N3 N3 N3 N3 = 0.4 x 0.2 x 0.2 x 0.8 x 0.5 x 0.5 x 0.5 x 0.5 = N1 N1 N2 N2 N3 = 0.6 x 0.4 x 0.2 x 0.8 x 0.5 =
20 Hidden Markov Model (HMM) There are approximately 44 phonemes in English. Phoneme example: tomato This accommodates for pronunciations such as: t ow m aa t ow - British English t ah m ey t ow - American English t ah mey t a - Possibly pronunciation when speaking quickly 20

21 Hidden Markov Model (HMM) Language model example: With sentences such as: I like apple juice - Very probable I like tomato juice - Very improbable! I hate apple juice - Relatively improbable I hate tomato juice - Relatively probable 21
22 Robust Speech Recognition The study of building speech recognition that handle mismatch condition. Mismatch condition? The difference between training and operating (testing) environment. It exists. For example, Simpler example: sudden door slam when dictating a letter. In wireless environment, the background of the speaker can change. 22
23 Mismatch Conditions Why mismatch conditions are hard to deal with? There are so many causes of it. Additive noise (e.g. background noise such as air-conditioning) Channel noise (e.g. difference between microphones in training and testing conditions) Others : Lombard noise. Reflection of building. In general, noise can have Random amplitude, Random duration, Random occurrence, Random spectral characteristic. 23
24 Previous Works Parallel Model Combination (PMC) (Gales 1995) First collect some samples of noise in operating environment, Update acoustic model using the noise statistics, Work satisfactorily for stationary noise, General time-varying noise cannot be handled. Dealing with Short Time Noise (Chan 2002) HMM-based Skip poor frames Modified Viterbi Algorithm dealing with Impulsive Noise (Siu 2005) Joint decoding and detection during the Viterbi search Lost frames are replaced by interpolated neighboring frames 24
25 Proposed Work HMM-based approach Finding a state sequence with best robust likelihood Conventional approach: For every state sequence, consider all possible patterns of corruption of K frames among T frames. Our approach: incorporate some prior information to find possible K Replace dynamic programming approach to branch-and-bound approach Developing outlier detection algorithms Leverage my research experience in outlier detection in medical images Define the characteristics of outliers in a wireless environment Classification or ICA to separate the speaking with noise/outliers Skipping frames or replacing frames? Different strategies should be used to deal with different types of noise/outliers (mismatch conditions) 25
26 CONCLUSION Speech Recognition systems are an indispensable part of the ever-advancing field of human-computer interaction. Needs greater research to tackle various challenges. 26
27 Thank You! Questions? 27
CONSTRUCTING TELEPHONE ACOUSTIC MODELS FROM A HIGH-QUALITY SPEECH CORPUS
 CONSTRUCTING TELEPHONE ACOUSTIC MODELS FROM A HIGH-QUALITY SPEECH CORPUS Mitchel Weintraub and Leonardo Neumeyer SRI International Speech Research and Technology Program Menlo Park, CA, 94025 USA ABSTRACT
CONSTRUCTING TELEPHONE ACOUSTIC MODELS FROM A HIGH-QUALITY SPEECH CORPUS Mitchel Weintraub and Leonardo Neumeyer SRI International Speech Research and Technology Program Menlo Park, CA, 94025 USA ABSTRACT
Speech recognition in noisy environments: A survey
 T-61.182 Robustness in Language and Speech Processing Speech recognition in noisy environments: A survey Yifan Gong presented by Tapani Raiko Feb 20, 2003 About the Paper Article published in Speech Communication
T-61.182 Robustness in Language and Speech Processing Speech recognition in noisy environments: A survey Yifan Gong presented by Tapani Raiko Feb 20, 2003 About the Paper Article published in Speech Communication
Advanced Audio Interface for Phonetic Speech. Recognition in a High Noise Environment
 DISTRIBUTION STATEMENT A Approved for Public Release Distribution Unlimited Advanced Audio Interface for Phonetic Speech Recognition in a High Noise Environment SBIR 99.1 TOPIC AF99-1Q3 PHASE I SUMMARY
DISTRIBUTION STATEMENT A Approved for Public Release Distribution Unlimited Advanced Audio Interface for Phonetic Speech Recognition in a High Noise Environment SBIR 99.1 TOPIC AF99-1Q3 PHASE I SUMMARY
Noise-Robust Speech Recognition Technologies in Mobile Environments
 Noise-Robust Speech Recognition echnologies in Mobile Environments Mobile environments are highly influenced by ambient noise, which may cause a significant deterioration of speech recognition performance.
Noise-Robust Speech Recognition echnologies in Mobile Environments Mobile environments are highly influenced by ambient noise, which may cause a significant deterioration of speech recognition performance.
General Soundtrack Analysis
 General Soundtrack Analysis Dan Ellis oratory for Recognition and Organization of Speech and Audio () Electrical Engineering, Columbia University http://labrosa.ee.columbia.edu/
General Soundtrack Analysis Dan Ellis oratory for Recognition and Organization of Speech and Audio () Electrical Engineering, Columbia University http://labrosa.ee.columbia.edu/
Methods for Improving Readability of Speech Recognition Transcripts. John McCoey. Abstract
 Methods for Improving Readability of Speech Recognition Transcripts John McCoey Computing Research Department of Computing Sciences Villanova University, Villanova, Pa, 19085 john.mccoey@villanova.edu
Methods for Improving Readability of Speech Recognition Transcripts John McCoey Computing Research Department of Computing Sciences Villanova University, Villanova, Pa, 19085 john.mccoey@villanova.edu
Rina Patel, Brent Greenberg, Steven Montner, Alexandra Funaki, Christopher Straus, Steven Zangan, and Heber MacMahon
 Rina Patel, Brent Greenberg, Steven Montner, Alexandra Funaki, Christopher Straus, Steven Zangan, and Heber MacMahon Versions of voice recognition software have been used to generate radiology reports
Rina Patel, Brent Greenberg, Steven Montner, Alexandra Funaki, Christopher Straus, Steven Zangan, and Heber MacMahon Versions of voice recognition software have been used to generate radiology reports
Interact-AS. Use handwriting, typing and/or speech input. The most recently spoken phrase is shown in the top box
 Interact-AS One of the Many Communications Products from Auditory Sciences Use handwriting, typing and/or speech input The most recently spoken phrase is shown in the top box Use the Control Box to Turn
Interact-AS One of the Many Communications Products from Auditory Sciences Use handwriting, typing and/or speech input The most recently spoken phrase is shown in the top box Use the Control Box to Turn
SpeechZone 2. Author Tina Howard, Au.D., CCC-A, FAAA Senior Validation Specialist Unitron Favorite sound: wind chimes
 SpeechZone 2 Difficulty understanding speech in noisy environments is the biggest complaint for those with hearing loss. 1 In the real world, important speech doesn t always come from in front of the listener.
SpeechZone 2 Difficulty understanding speech in noisy environments is the biggest complaint for those with hearing loss. 1 In the real world, important speech doesn t always come from in front of the listener.
CHAPTER 1 INTRODUCTION
 CHAPTER 1 INTRODUCTION 1.1 BACKGROUND Speech is the most natural form of human communication. Speech has also become an important means of human-machine interaction and the advancement in technology has
CHAPTER 1 INTRODUCTION 1.1 BACKGROUND Speech is the most natural form of human communication. Speech has also become an important means of human-machine interaction and the advancement in technology has
A Smart Texting System For Android Mobile Users
 A Smart Texting System For Android Mobile Users Pawan D. Mishra Harshwardhan N. Deshpande Navneet A. Agrawal Final year I.T Final year I.T J.D.I.E.T Yavatmal. J.D.I.E.T Yavatmal. Final year I.T J.D.I.E.T
A Smart Texting System For Android Mobile Users Pawan D. Mishra Harshwardhan N. Deshpande Navneet A. Agrawal Final year I.T Final year I.T J.D.I.E.T Yavatmal. J.D.I.E.T Yavatmal. Final year I.T J.D.I.E.T
A Consumer-friendly Recap of the HLAA 2018 Research Symposium: Listening in Noise Webinar
 A Consumer-friendly Recap of the HLAA 2018 Research Symposium: Listening in Noise Webinar Perry C. Hanavan, AuD Augustana University Sioux Falls, SD August 15, 2018 Listening in Noise Cocktail Party Problem
A Consumer-friendly Recap of the HLAA 2018 Research Symposium: Listening in Noise Webinar Perry C. Hanavan, AuD Augustana University Sioux Falls, SD August 15, 2018 Listening in Noise Cocktail Party Problem
Acoustic Signal Processing Based on Deep Neural Networks
 Acoustic Signal Processing Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu, Yanhui Tu, Qing Wang, Tian Gao, Jun Du, LiRong Dai Outline
Acoustic Signal Processing Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu, Yanhui Tu, Qing Wang, Tian Gao, Jun Du, LiRong Dai Outline
Assistive Listening Technology: in the workplace and on campus
 Assistive Listening Technology: in the workplace and on campus Jeremy Brassington Tuesday, 11 July 2017 Why is it hard to hear in noisy rooms? Distance from sound source Background noise continuous and
Assistive Listening Technology: in the workplace and on campus Jeremy Brassington Tuesday, 11 July 2017 Why is it hard to hear in noisy rooms? Distance from sound source Background noise continuous and
Director of Testing and Disability Services Phone: (706) Fax: (706) E Mail:
 Fax: (706) E Mail:") Angie S. Baker Testing and Disability Services Director of Testing and Disability Services Phone: (706)737 1469 Fax: (706)729 2298 E Mail: tds@gru.edu Deafness is an invisible disability. It is easy for
Angie S. Baker Testing and Disability Services Director of Testing and Disability Services Phone: (706)737 1469 Fax: (706)729 2298 E Mail: tds@gru.edu Deafness is an invisible disability. It is easy for
Speech to Text Wireless Converter
 Speech to Text Wireless Converter Kailas Puri 1, Vivek Ajage 2, Satyam Mali 3, Akhil Wasnik 4, Amey Naik 5 And Guided by Dr. Prof. M. S. Panse 6 1,2,3,4,5,6 Department of Electrical Engineering, Veermata
Speech to Text Wireless Converter Kailas Puri 1, Vivek Ajage 2, Satyam Mali 3, Akhil Wasnik 4, Amey Naik 5 And Guided by Dr. Prof. M. S. Panse 6 1,2,3,4,5,6 Department of Electrical Engineering, Veermata
Lecture 9: Speech Recognition: Front Ends
 EE E682: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition: Front Ends 1 2 Recognizing Speech Feature Calculation Dan Ellis http://www.ee.columbia.edu/~dpwe/e682/
EE E682: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition: Front Ends 1 2 Recognizing Speech Feature Calculation Dan Ellis http://www.ee.columbia.edu/~dpwe/e682/
Captioning Your Video Using YouTube Online Accessibility Series
 Captioning Your Video Using YouTube This document will show you how to use YouTube to add captions to a video, making it accessible to individuals who are deaf or hard of hearing. In order to post videos
Captioning Your Video Using YouTube This document will show you how to use YouTube to add captions to a video, making it accessible to individuals who are deaf or hard of hearing. In order to post videos
Speech as HCI. HCI Lecture 11. Human Communication by Speech. Speech as HCI(cont. 2) Guest lecture: Speech Interfaces
 Guest lecture: Speech Interfaces") HCI Lecture 11 Guest lecture: Speech Interfaces Hiroshi Shimodaira Institute for Communicating and Collaborative Systems (ICCS) Centre for Speech Technology Research (CSTR) http://www.cstr.ed.ac.uk Thanks
HCI Lecture 11 Guest lecture: Speech Interfaces Hiroshi Shimodaira Institute for Communicating and Collaborative Systems (ICCS) Centre for Speech Technology Research (CSTR) http://www.cstr.ed.ac.uk Thanks
Robust Speech Detection for Noisy Environments
 Robust Speech Detection for Noisy Environments Óscar Varela, Rubén San-Segundo and Luis A. Hernández ABSTRACT This paper presents a robust voice activity detector (VAD) based on hidden Markov models (HMM)
Robust Speech Detection for Noisy Environments Óscar Varela, Rubén San-Segundo and Luis A. Hernández ABSTRACT This paper presents a robust voice activity detector (VAD) based on hidden Markov models (HMM)
Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise
 4 Special Issue Speech-Based Interfaces in Vehicles Research Report Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise Hiroyuki Hoshino Abstract This
4 Special Issue Speech-Based Interfaces in Vehicles Research Report Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise Hiroyuki Hoshino Abstract This
Telephone Based Automatic Voice Pathology Assessment.
 Telephone Based Automatic Voice Pathology Assessment. Rosalyn Moran 1, R. B. Reilly 1, P.D. Lacy 2 1 Department of Electronic and Electrical Engineering, University College Dublin, Ireland 2 Royal Victoria
Telephone Based Automatic Voice Pathology Assessment. Rosalyn Moran 1, R. B. Reilly 1, P.D. Lacy 2 1 Department of Electronic and Electrical Engineering, University College Dublin, Ireland 2 Royal Victoria
Assistive Technologies
 Revista Informatica Economică nr. 2(46)/2008 135 Assistive Technologies Ion SMEUREANU, Narcisa ISĂILĂ Academy of Economic Studies, Bucharest smeurean@ase.ro, isaila_narcisa@yahoo.com A special place into
Revista Informatica Economică nr. 2(46)/2008 135 Assistive Technologies Ion SMEUREANU, Narcisa ISĂILĂ Academy of Economic Studies, Bucharest smeurean@ase.ro, isaila_narcisa@yahoo.com A special place into
Real Time Sign Language Processing System
 Real Time Sign Language Processing System Dibyabiva Seth (&), Anindita Ghosh, Ariruna Dasgupta, and Asoke Nath Department of Computer Science, St. Xavier s College (Autonomous), Kolkata, India meetdseth@gmail.com,
Real Time Sign Language Processing System Dibyabiva Seth (&), Anindita Ghosh, Ariruna Dasgupta, and Asoke Nath Department of Computer Science, St. Xavier s College (Autonomous), Kolkata, India meetdseth@gmail.com,
THE LISTENING QUESTIONNAIRE TLQ For Parents and Teachers of Students Ages 7 through 17 Years
 THE LISTENING QUESTIONNAIRE TLQ For Parents and Teachers of Students Ages 7 through 17 Years Instructions: This questionnaire reviews a student s everyday listening skills. Language, attention, and auditory
THE LISTENING QUESTIONNAIRE TLQ For Parents and Teachers of Students Ages 7 through 17 Years Instructions: This questionnaire reviews a student s everyday listening skills. Language, attention, and auditory
HOW AI WILL IMPACT SUBTITLE PRODUCTION
 HOW AI WILL IMPACT SUBTITLE PRODUCTION 1 WHAT IS AI IN A BROADCAST CONTEXT? 2 What is AI in a Broadcast Context? I m sorry, Dave. I m afraid I can t do that. Image By Cryteria [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)],
HOW AI WILL IMPACT SUBTITLE PRODUCTION 1 WHAT IS AI IN A BROADCAST CONTEXT? 2 What is AI in a Broadcast Context? I m sorry, Dave. I m afraid I can t do that. Image By Cryteria [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)],
Open up to the world. A new paradigm in hearing care
 Open up to the world A new paradigm in hearing care The hearing aid industry has tunnel focus Technological limitations of current hearing aids have led to the use of tunnel directionality to make speech
Open up to the world A new paradigm in hearing care The hearing aid industry has tunnel focus Technological limitations of current hearing aids have led to the use of tunnel directionality to make speech
Appendix C Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses
 Appendix C Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses writes or types student responses into the Student Testing Site or onto a scorable test booklet or answer
Appendix C Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses writes or types student responses into the Student Testing Site or onto a scorable test booklet or answer
SPEECH TO TEXT CONVERTER USING GAUSSIAN MIXTURE MODEL(GMM)
") SPEECH TO TEXT CONVERTER USING GAUSSIAN MIXTURE MODEL(GMM) Virendra Chauhan 1, Shobhana Dwivedi 2, Pooja Karale 3, Prof. S.M. Potdar 4 1,2,3B.E. Student 4 Assitant Professor 1,2,3,4Department of Electronics
SPEECH TO TEXT CONVERTER USING GAUSSIAN MIXTURE MODEL(GMM) Virendra Chauhan 1, Shobhana Dwivedi 2, Pooja Karale 3, Prof. S.M. Potdar 4 1,2,3B.E. Student 4 Assitant Professor 1,2,3,4Department of Electronics
Discover the Accessibility Features of Smartphones! A Wireless Education Seminar for Consumers who are Deaf and Hard-of-Hearing
 Discover the Accessibility Features of Smartphones! A Wireless Education Seminar for Consumers who are Deaf and Hard-of-Hearing Who We Are Ben Lippincott Project Director Consumer and Industry Outreach
Discover the Accessibility Features of Smartphones! A Wireless Education Seminar for Consumers who are Deaf and Hard-of-Hearing Who We Are Ben Lippincott Project Director Consumer and Industry Outreach
Lecturer: T. J. Hazen. Handling variability in acoustic conditions. Computing and applying confidence scores
 Lecture # 20 Session 2003 Noise Robustness and Confidence Scoring Lecturer: T. J. Hazen Handling variability in acoustic conditions Channel compensation Background noise compensation Foreground noises
Lecture # 20 Session 2003 Noise Robustness and Confidence Scoring Lecturer: T. J. Hazen Handling variability in acoustic conditions Channel compensation Background noise compensation Foreground noises
Research Proposal on Emotion Recognition
 Research Proposal on Emotion Recognition Colin Grubb June 3, 2012 Abstract In this paper I will introduce my thesis question: To what extent can emotion recognition be improved by combining audio and visual
Research Proposal on Emotion Recognition Colin Grubb June 3, 2012 Abstract In this paper I will introduce my thesis question: To what extent can emotion recognition be improved by combining audio and visual
TRANSCRIBING AND CODING P.A.R.T. SESSION SESSION1: TRANSCRIBING
 TRANSCRIBING AND CODING P.A.R.T. SESSION SESSION1: TRANSCRIBING May 3 rd and 5th, 10 to 12 Library Classroom Prof. Tenley Conway Department of Geography Topics for the Two Sessions What Is transcription?
TRANSCRIBING AND CODING P.A.R.T. SESSION SESSION1: TRANSCRIBING May 3 rd and 5th, 10 to 12 Library Classroom Prof. Tenley Conway Department of Geography Topics for the Two Sessions What Is transcription?
User Guide V: 3.0, August 2017
 User Guide V: 3.0, August 2017 a product of FAQ 3 General Information 1.1 System Overview 5 1.2 User Permissions 6 1.3 Points of Contact 7 1.4 Acronyms and Definitions 8 System Summary 2.1 System Configuration
User Guide V: 3.0, August 2017 a product of FAQ 3 General Information 1.1 System Overview 5 1.2 User Permissions 6 1.3 Points of Contact 7 1.4 Acronyms and Definitions 8 System Summary 2.1 System Configuration
Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions
 3 Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions Ryoichi Takashima, Tetsuya Takiguchi and Yasuo Ariki Graduate School of System Informatics, Kobe University,
3 Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions Ryoichi Takashima, Tetsuya Takiguchi and Yasuo Ariki Graduate School of System Informatics, Kobe University,
International Journal of Engineering Research in Computer Science and Engineering (IJERCSE) Vol 5, Issue 3, March 2018 Gesture Glove
 Vol 5, Issue 3, March 2018 Gesture Glove") Gesture Glove [1] Kanere Pranali, [2] T.Sai Milind, [3] Patil Shweta, [4] Korol Dhanda, [5] Waqar Ahmad, [6] Rakhi Kalantri [1] Student, [2] Student, [3] Student, [4] Student, [5] Student, [6] Assistant
Gesture Glove [1] Kanere Pranali, [2] T.Sai Milind, [3] Patil Shweta, [4] Korol Dhanda, [5] Waqar Ahmad, [6] Rakhi Kalantri [1] Student, [2] Student, [3] Student, [4] Student, [5] Student, [6] Assistant
TODAY AND THE DEVELOPMENT
 STENOGRAPHY IN CHINA TODAY AND THE DEVELOPMENT Like the development elsewhere in the world, stenography in China has also taken a 2-steps path: from handwriting to mechanical; and from mechanical to electronic,
STENOGRAPHY IN CHINA TODAY AND THE DEVELOPMENT Like the development elsewhere in the world, stenography in China has also taken a 2-steps path: from handwriting to mechanical; and from mechanical to electronic,
Using Source Models in Speech Separation
 Using Source Models in Speech Separation Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Using Source Models in Speech Separation Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Sennheiser. ActiveGard Technology. Your investment in. Sound Safety WHITE PAPER
 Sennheiser ActiveGard Technology Your investment in Sound Safety WHITE PAPER INDEX Introduction 3 About ActiveGard 3 The regulatory background 4 Safety and wellbeing 5 In summary 5 2 Introduction Great
Sennheiser ActiveGard Technology Your investment in Sound Safety WHITE PAPER INDEX Introduction 3 About ActiveGard 3 The regulatory background 4 Safety and wellbeing 5 In summary 5 2 Introduction Great
C H A N N E L S A N D B A N D S A C T I V E N O I S E C O N T R O L 2
 C H A N N E L S A N D B A N D S Audibel hearing aids offer between 4 and 16 truly independent channels and bands. Channels are sections of the frequency spectrum that are processed independently by the
C H A N N E L S A N D B A N D S Audibel hearing aids offer between 4 and 16 truly independent channels and bands. Channels are sections of the frequency spectrum that are processed independently by the
Full Utilization of Closed-captions in Broadcast News Recognition
 Full Utilization of Closed-captions in Broadcast News Recognition Meng Meng, Wang Shijin, Liang Jiaen, Ding Peng, Xu Bo. Hi-Tech Innovation Center, Institute of Automation Chinese Academy of Sciences,
Full Utilization of Closed-captions in Broadcast News Recognition Meng Meng, Wang Shijin, Liang Jiaen, Ding Peng, Xu Bo. Hi-Tech Innovation Center, Institute of Automation Chinese Academy of Sciences,
The MIT Mobile Device Speaker Verification Corpus: Data Collection and Preliminary Experiments
 The MIT Mobile Device Speaker Verification Corpus: Data Collection and Preliminary Experiments Ram H. Woo, Alex Park, and Timothy J. Hazen MIT Computer Science and Artificial Intelligence Laboratory 32
The MIT Mobile Device Speaker Verification Corpus: Data Collection and Preliminary Experiments Ram H. Woo, Alex Park, and Timothy J. Hazen MIT Computer Science and Artificial Intelligence Laboratory 32
Virtual Sensors: Transforming the Way We Think About Accommodation Stevens Institute of Technology-Hoboken, New Jersey Katherine Grace August, Avi
 Virtual Sensors: Transforming the Way We Think About Accommodation Stevens Institute of Technology-Hoboken, New Jersey Katherine Grace August, Avi Hauser, Dave Nall Fatimah Shehadeh-Grant, Jennifer Chen,
Virtual Sensors: Transforming the Way We Think About Accommodation Stevens Institute of Technology-Hoboken, New Jersey Katherine Grace August, Avi Hauser, Dave Nall Fatimah Shehadeh-Grant, Jennifer Chen,
Children and hearing. General information on children s hearing and hearing loss.
 Children and hearing 7 General information on children s hearing and hearing loss. This is the seventh in a series of brochures from Widex on hearing and hearing-related matters. The importance of hearing
Children and hearing 7 General information on children s hearing and hearing loss. This is the seventh in a series of brochures from Widex on hearing and hearing-related matters. The importance of hearing
A new era in classroom amplification
 A new era in classroom amplification 2 Why soundfield matters For the best possible learning experience children must be able to hear the teacher s voice clearly in class, but unfortunately this is not
A new era in classroom amplification 2 Why soundfield matters For the best possible learning experience children must be able to hear the teacher s voice clearly in class, but unfortunately this is not
Roger at work. Bridging the understanding gap
 Roger at work Bridging the understanding gap Concentrate on excelling, not your hearing The modern workplace can be a complicated listening environment, with its challenging open-plan spaces, group meetings,
Roger at work Bridging the understanding gap Concentrate on excelling, not your hearing The modern workplace can be a complicated listening environment, with its challenging open-plan spaces, group meetings,
The Benefits and Challenges of Amplification in Classrooms.
 The Benefits and Challenges of Amplification in Classrooms. CEFPI October 2012 Julie Wiebusch & Mark Rogers CEFPI is a Registered Provider with The American Institute of Architects Continuing Education
The Benefits and Challenges of Amplification in Classrooms. CEFPI October 2012 Julie Wiebusch & Mark Rogers CEFPI is a Registered Provider with The American Institute of Architects Continuing Education
Accessible Computing Research for Users who are Deaf and Hard of Hearing (DHH)
") Accessible Computing Research for Users who are Deaf and Hard of Hearing (DHH) Matt Huenerfauth Raja Kushalnagar Rochester Institute of Technology DHH Auditory Issues Links Accents/Intonation Listening
Accessible Computing Research for Users who are Deaf and Hard of Hearing (DHH) Matt Huenerfauth Raja Kushalnagar Rochester Institute of Technology DHH Auditory Issues Links Accents/Intonation Listening
CSE 118/218 Final Presentation. Team 2 Dreams and Aspirations
 CSE 118/218 Final Presentation Team 2 Dreams and Aspirations Smart Hearing Hearing Impairment A major public health issue that is the third most common physical condition after arthritis and heart disease
CSE 118/218 Final Presentation Team 2 Dreams and Aspirations Smart Hearing Hearing Impairment A major public health issue that is the third most common physical condition after arthritis and heart disease
INTELLIGENT LIP READING SYSTEM FOR HEARING AND VOCAL IMPAIRMENT
 INTELLIGENT LIP READING SYSTEM FOR HEARING AND VOCAL IMPAIRMENT R.Nishitha 1, Dr K.Srinivasan 2, Dr V.Rukkumani 3 1 Student, 2 Professor and Head, 3 Associate Professor, Electronics and Instrumentation
INTELLIGENT LIP READING SYSTEM FOR HEARING AND VOCAL IMPAIRMENT R.Nishitha 1, Dr K.Srinivasan 2, Dr V.Rukkumani 3 1 Student, 2 Professor and Head, 3 Associate Professor, Electronics and Instrumentation
Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency
 Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency Tetsuya Shimamura and Fumiya Kato Graduate School of Science and Engineering Saitama University 255 Shimo-Okubo,
Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency Tetsuya Shimamura and Fumiya Kato Graduate School of Science and Engineering Saitama University 255 Shimo-Okubo,
Gender Based Emotion Recognition using Speech Signals: A Review
 50 Gender Based Emotion Recognition using Speech Signals: A Review Parvinder Kaur 1, Mandeep Kaur 2 1 Department of Electronics and Communication Engineering, Punjabi University, Patiala, India 2 Department
50 Gender Based Emotion Recognition using Speech Signals: A Review Parvinder Kaur 1, Mandeep Kaur 2 1 Department of Electronics and Communication Engineering, Punjabi University, Patiala, India 2 Department
Appendix C: Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses
 Appendix C: Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses Scribing a student s responses by an adult test administrator is a response accommodation that allows
Appendix C: Protocol for the Use of the Scribe Accommodation and for Transcribing Student Responses Scribing a student s responses by an adult test administrator is a response accommodation that allows
Sound Interfaces Engineering Interaction Technologies. Prof. Stefanie Mueller HCI Engineering Group
 Sound Interfaces 6.810 Engineering Interaction Technologies Prof. Stefanie Mueller HCI Engineering Group what is sound? if a tree falls in the forest and nobody is there does it make sound?
Sound Interfaces 6.810 Engineering Interaction Technologies Prof. Stefanie Mueller HCI Engineering Group what is sound? if a tree falls in the forest and nobody is there does it make sound?
Making Sure People with Communication Disabilities Get the Message
 Emergency Planning and Response for People with Disabilities Making Sure People with Communication Disabilities Get the Message A Checklist for Emergency Public Information Officers This document is part
Emergency Planning and Response for People with Disabilities Making Sure People with Communication Disabilities Get the Message A Checklist for Emergency Public Information Officers This document is part
Date: April 19, 2017 Name of Product: Cisco Spark Board Contact for more information:
 Date: April 19, 2017 Name of Product: Cisco Spark Board Contact for more information: accessibility@cisco.com Summary Table - Voluntary Product Accessibility Template Criteria Supporting Features Remarks
Date: April 19, 2017 Name of Product: Cisco Spark Board Contact for more information: accessibility@cisco.com Summary Table - Voluntary Product Accessibility Template Criteria Supporting Features Remarks
On-The-Fly Student Notes from Video Lecture. Using ASR
 On-The-Fly Student es from Video Lecture Using ASR Dipali Ramesh Peddawad 1 1computer Science and Engineering, Vishwakarma Institute Technology Maharashtra, India ---------------------------------------------------------------------***---------------------------------------------------------------------
On-The-Fly Student es from Video Lecture Using ASR Dipali Ramesh Peddawad 1 1computer Science and Engineering, Vishwakarma Institute Technology Maharashtra, India ---------------------------------------------------------------------***---------------------------------------------------------------------
easy read Your rights under THE accessible InformatioN STandard
 easy read Your rights under THE accessible InformatioN STandard Your Rights Under The Accessible Information Standard 2 Introduction In June 2015 NHS introduced the Accessible Information Standard (AIS)
easy read Your rights under THE accessible InformatioN STandard Your Rights Under The Accessible Information Standard 2 Introduction In June 2015 NHS introduced the Accessible Information Standard (AIS)
A Sleeping Monitor for Snoring Detection
 EECS 395/495 - mhealth McCormick School of Engineering A Sleeping Monitor for Snoring Detection By Hongwei Cheng, Qian Wang, Tae Hun Kim Abstract Several studies have shown that snoring is the first symptom
EECS 395/495 - mhealth McCormick School of Engineering A Sleeping Monitor for Snoring Detection By Hongwei Cheng, Qian Wang, Tae Hun Kim Abstract Several studies have shown that snoring is the first symptom
Speech and Sound Use in a Remote Monitoring System for Health Care
 Speech and Sound Use in a Remote System for Health Care M. Vacher J.-F. Serignat S. Chaillol D. Istrate V. Popescu CLIPS-IMAG, Team GEOD Joseph Fourier University of Grenoble - CNRS (France) Text, Speech
Speech and Sound Use in a Remote System for Health Care M. Vacher J.-F. Serignat S. Chaillol D. Istrate V. Popescu CLIPS-IMAG, Team GEOD Joseph Fourier University of Grenoble - CNRS (France) Text, Speech
DRAFT. 7 Steps to Better Communication. When a loved one has hearing loss. How does hearing loss affect communication?
 UW MEDICINE PATIENT EDUCATION 7 Steps to Better Communication When a loved one has hearing loss This handout gives practical tips to help people communicate better in spite of hearing loss. How does hearing
UW MEDICINE PATIENT EDUCATION 7 Steps to Better Communication When a loved one has hearing loss This handout gives practical tips to help people communicate better in spite of hearing loss. How does hearing
COMPUTER PLAY IN EDUCATIONAL THERAPY FOR CHILDREN WITH STUTTERING PROBLEM: HARDWARE SETUP AND INTERVENTION
 034 - Proceeding of the Global Summit on Education (GSE2013) COMPUTER PLAY IN EDUCATIONAL THERAPY FOR CHILDREN WITH STUTTERING PROBLEM: HARDWARE SETUP AND INTERVENTION ABSTRACT Nur Azah Hamzaid, Ammar
034 - Proceeding of the Global Summit on Education (GSE2013) COMPUTER PLAY IN EDUCATIONAL THERAPY FOR CHILDREN WITH STUTTERING PROBLEM: HARDWARE SETUP AND INTERVENTION ABSTRACT Nur Azah Hamzaid, Ammar
SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
 CPC - G10L - 2017.08 G10L SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING processing of speech or voice signals in general (G10L 25/00);
CPC - G10L - 2017.08 G10L SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING processing of speech or voice signals in general (G10L 25/00);
Speed - Accuracy - Exploration. Pathfinder SL
 Speed - Accuracy - Exploration Pathfinder SL 98000 Speed. Accuracy. Exploration. Pathfinder SL represents the evolution of over 40 years of technology, design, algorithm development and experience in the
Speed - Accuracy - Exploration Pathfinder SL 98000 Speed. Accuracy. Exploration. Pathfinder SL represents the evolution of over 40 years of technology, design, algorithm development and experience in the
Online Speaker Adaptation of an Acoustic Model using Face Recognition
 Online Speaker Adaptation of an Acoustic Model using Face Recognition Pavel Campr 1, Aleš Pražák 2, Josef V. Psutka 2, and Josef Psutka 2 1 Center for Machine Perception, Department of Cybernetics, Faculty
Online Speaker Adaptation of an Acoustic Model using Face Recognition Pavel Campr 1, Aleš Pražák 2, Josef V. Psutka 2, and Josef Psutka 2 1 Center for Machine Perception, Department of Cybernetics, Faculty
TOPICS IN AMPLIFICATION
 August 2011 Directional modalities Directional Microphone Technology in Oasis 14.0 and Applications for Use Directional microphones are among the most important features found on hearing instruments today.
August 2011 Directional modalities Directional Microphone Technology in Oasis 14.0 and Applications for Use Directional microphones are among the most important features found on hearing instruments today.
Effects of speaker's and listener's environments on speech intelligibili annoyance. Author(s)Kubo, Rieko; Morikawa, Daisuke; Akag
Kubo, Rieko; Morikawa, Daisuke; Akag") JAIST Reposi https://dspace.j Title Effects of speaker's and listener's environments on speech intelligibili annoyance Author(s)Kubo, Rieko; Morikawa, Daisuke; Akag Citation Inter-noise 2016: 171-176 Issue
JAIST Reposi https://dspace.j Title Effects of speaker's and listener's environments on speech intelligibili annoyance Author(s)Kubo, Rieko; Morikawa, Daisuke; Akag Citation Inter-noise 2016: 171-176 Issue
how we hear. Better understanding of hearing loss The diagram above illustrates the steps involved.
 How we hear Better understanding of hearing loss begins by understanding how we hear. The diagram above illustrates the steps involved. 1. Sound waves are collected by the outer ear and channeled along
How we hear Better understanding of hearing loss begins by understanding how we hear. The diagram above illustrates the steps involved. 1. Sound waves are collected by the outer ear and channeled along
Speaker Independent Isolated Word Speech to Text Conversion Using Auto Spectral Subtraction for Punjabi Language
 International Journal of Scientific and Research Publications, Volume 7, Issue 7, July 2017 469 Speaker Independent Isolated Word Speech to Text Conversion Using Auto Spectral Subtraction for Punjabi Language
International Journal of Scientific and Research Publications, Volume 7, Issue 7, July 2017 469 Speaker Independent Isolated Word Speech to Text Conversion Using Auto Spectral Subtraction for Punjabi Language
An Examination of Speech In Noise and its Effect on Understandability for Natural and Synthetic Speech. Brian Langner and Alan W Black CMU-LTI
 An Examination of Speech In Noise and its Effect on Understandability for Natural and Synthetic Speech Brian Langner and Alan W Black CMU-LTI-4-187 FINAL Language Technologies Institute School of Computer
An Examination of Speech In Noise and its Effect on Understandability for Natural and Synthetic Speech Brian Langner and Alan W Black CMU-LTI-4-187 FINAL Language Technologies Institute School of Computer
IMPROVING THE PATIENT EXPERIENCE IN NOISE: FAST-ACTING SINGLE-MICROPHONE NOISE REDUCTION
 IMPROVING THE PATIENT EXPERIENCE IN NOISE: FAST-ACTING SINGLE-MICROPHONE NOISE REDUCTION Jason A. Galster, Ph.D. & Justyn Pisa, Au.D. Background Hearing impaired listeners experience their greatest auditory
IMPROVING THE PATIENT EXPERIENCE IN NOISE: FAST-ACTING SINGLE-MICROPHONE NOISE REDUCTION Jason A. Galster, Ph.D. & Justyn Pisa, Au.D. Background Hearing impaired listeners experience their greatest auditory
Fig. 1 High level block diagram of the binary mask algorithm.[1]
![Fig. 1 High level block diagram of the binary mask algorithm.[1]](/thumbs/83/88394195.jpg "Fig. 1 High level block diagram of the binary mask algorithm.[1]") Implementation of Binary Mask Algorithm for Noise Reduction in Traffic Environment Ms. Ankita A. Kotecha 1, Prof. Y.A.Sadawarte 2 1 M-Tech Scholar, Department of Electronics Engineering, B. D. College
Implementation of Binary Mask Algorithm for Noise Reduction in Traffic Environment Ms. Ankita A. Kotecha 1, Prof. Y.A.Sadawarte 2 1 M-Tech Scholar, Department of Electronics Engineering, B. D. College
Putting the focus on conversations
 Putting the focus on conversations A three-part whitepaper series Moving to a new technology platform presents hearing instrument manufacturers with opportunities to make changes that positively impact
Putting the focus on conversations A three-part whitepaper series Moving to a new technology platform presents hearing instrument manufacturers with opportunities to make changes that positively impact
VIRTUAL ASSISTANT FOR DEAF AND DUMB
 VIRTUAL ASSISTANT FOR DEAF AND DUMB Sumanti Saini, Shivani Chaudhry, Sapna, 1,2,3 Final year student, CSE, IMSEC Ghaziabad, U.P., India ABSTRACT For the Deaf and Dumb community, the use of Information
VIRTUAL ASSISTANT FOR DEAF AND DUMB Sumanti Saini, Shivani Chaudhry, Sapna, 1,2,3 Final year student, CSE, IMSEC Ghaziabad, U.P., India ABSTRACT For the Deaf and Dumb community, the use of Information
Communications Accessibility with Avaya IP Office
 Accessibility with Avaya IP Office Voluntary Product Accessibility Template (VPAT) 1194.23, Telecommunications Products Avaya IP Office is an all-in-one solution specially designed to meet the communications
Accessibility with Avaya IP Office Voluntary Product Accessibility Template (VPAT) 1194.23, Telecommunications Products Avaya IP Office is an all-in-one solution specially designed to meet the communications
ENZO 3D First fitting with ReSound Smart Fit 1.1
 ENZO 3D First fitting with ReSound Smart Fit 1.1 This fitting guide gives an overview of how to fit ReSound ENZO 3D wireless hearing instruments with ReSound Smart Fit 1.1. A ReSound ENZO 3D 998 wireless
ENZO 3D First fitting with ReSound Smart Fit 1.1 This fitting guide gives an overview of how to fit ReSound ENZO 3D wireless hearing instruments with ReSound Smart Fit 1.1. A ReSound ENZO 3D 998 wireless
Avaya Model 9611G H.323 Deskphone
 Avaya Model 9611G H.323 Deskphone Voluntary Product Accessibility Template (VPAT) The statements in this document apply to Avaya Model 9611G Deskphones only when they are configured with Avaya one-x Deskphone
Avaya Model 9611G H.323 Deskphone Voluntary Product Accessibility Template (VPAT) The statements in this document apply to Avaya Model 9611G Deskphones only when they are configured with Avaya one-x Deskphone
icommunicator, Leading Speech-to-Text-To-Sign Language Software System, Announces Version 5.0
 For Immediate Release: William G. Daddi Daddi Brand Communications (P) 212-404-6619 (M) 917-620-3717 Bill@daddibrand.com icommunicator, Leading Speech-to-Text-To-Sign Language Software System, Announces
For Immediate Release: William G. Daddi Daddi Brand Communications (P) 212-404-6619 (M) 917-620-3717 Bill@daddibrand.com icommunicator, Leading Speech-to-Text-To-Sign Language Software System, Announces
easy read Your rights under THE accessible InformatioN STandard
 easy read Your rights under THE accessible InformatioN STandard Your Rights Under The Accessible Information Standard 2 1 Introduction In July 2015, NHS England published the Accessible Information Standard
easy read Your rights under THE accessible InformatioN STandard Your Rights Under The Accessible Information Standard 2 1 Introduction In July 2015, NHS England published the Accessible Information Standard
Production of Stop Consonants by Children with Cochlear Implants & Children with Normal Hearing. Danielle Revai University of Wisconsin - Madison
 Production of Stop Consonants by Children with Cochlear Implants & Children with Normal Hearing Danielle Revai University of Wisconsin - Madison Normal Hearing (NH) Who: Individuals with no HL What: Acoustic
Production of Stop Consonants by Children with Cochlear Implants & Children with Normal Hearing Danielle Revai University of Wisconsin - Madison Normal Hearing (NH) Who: Individuals with no HL What: Acoustic
Cued Speech and Cochlear Implants: Powerful Partners. Jane Smith Communication Specialist Montgomery County Public Schools
 Cued Speech and Cochlear Implants: Powerful Partners Jane Smith Communication Specialist Montgomery County Public Schools Jane_B_Smith@mcpsmd.org Agenda: Welcome and remarks Cochlear implants how they
Cued Speech and Cochlear Implants: Powerful Partners Jane Smith Communication Specialist Montgomery County Public Schools Jane_B_Smith@mcpsmd.org Agenda: Welcome and remarks Cochlear implants how they
Your Guide to Hearing
 Your Guide to Hearing INFORMATION YOU NEED TO MAKE A SOUND DECISION CONTENTS Signs of hearing loss Hearing instrument technology Balanced hearing - one ear or two? Hearing instrument styles Adjusting to
Your Guide to Hearing INFORMATION YOU NEED TO MAKE A SOUND DECISION CONTENTS Signs of hearing loss Hearing instrument technology Balanced hearing - one ear or two? Hearing instrument styles Adjusting to
Overview 6/27/16. Rationale for Real-time Text in the Classroom. What is Real-Time Text?
 Access to Mainstream Classroom Instruction Through Real-Time Text Michael Stinson, Rochester Institute of Technology National Technical Institute for the Deaf Presentation at Best Practice in Mainstream
Access to Mainstream Classroom Instruction Through Real-Time Text Michael Stinson, Rochester Institute of Technology National Technical Institute for the Deaf Presentation at Best Practice in Mainstream
Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components
 Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components Miss Bhagat Nikita 1, Miss Chavan Prajakta 2, Miss Dhaigude Priyanka 3, Miss Ingole Nisha 4, Mr Ranaware Amarsinh
Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components Miss Bhagat Nikita 1, Miss Chavan Prajakta 2, Miss Dhaigude Priyanka 3, Miss Ingole Nisha 4, Mr Ranaware Amarsinh
VITHEA: On-line word naming therapy in Portuguese for aphasic patients exploiting automatic speech recognition
 VITHEA: On-line word naming therapy in Portuguese for aphasic patients exploiting automatic speech recognition Anna Pompili, Pedro Fialho and Alberto Abad L 2 F - Spoken Language Systems Lab, INESC-ID
VITHEA: On-line word naming therapy in Portuguese for aphasic patients exploiting automatic speech recognition Anna Pompili, Pedro Fialho and Alberto Abad L 2 F - Spoken Language Systems Lab, INESC-ID
HearPhones. hearing enhancement solution for modern life. As simple as wearing glasses. Revision 3.1 October 2015
 HearPhones hearing enhancement solution for modern life As simple as wearing glasses Revision 3.1 October 2015 HearPhones glasses for hearing impaired What differs life of people with poor eyesight from
HearPhones hearing enhancement solution for modern life As simple as wearing glasses Revision 3.1 October 2015 HearPhones glasses for hearing impaired What differs life of people with poor eyesight from
Voluntary Product Accessibility Template (VPAT)
") (VPAT) Date: Product Name: Product Version Number: Organization Name: Submitter Name: Submitter Telephone: APPENDIX A: Suggested Language Guide Summary Table Section 1194.21 Software Applications and Operating
(VPAT) Date: Product Name: Product Version Number: Organization Name: Submitter Name: Submitter Telephone: APPENDIX A: Suggested Language Guide Summary Table Section 1194.21 Software Applications and Operating
A PUBLIC DOMAIN SPEECH-TO-TEXT SYSTEM
 A PUBLIC DOMAIN SPEECH-TO-TEXT SYSTEM M. Ordowski+, N. Deshmukh*, A. Ganapathiraju*, J. Hamaker*, and J. Picone* *Institute for Signal and Information Processing Department for Electrical and Computer
A PUBLIC DOMAIN SPEECH-TO-TEXT SYSTEM M. Ordowski+, N. Deshmukh*, A. Ganapathiraju*, J. Hamaker*, and J. Picone* *Institute for Signal and Information Processing Department for Electrical and Computer
The Perfect Dictator
 The Perfect Dictator There is a growing acceptance that dictation can improve efficiency and allow individuals more time to spend on valuable activities, but there is perhaps a misconception that it s
The Perfect Dictator There is a growing acceptance that dictation can improve efficiency and allow individuals more time to spend on valuable activities, but there is perhaps a misconception that it s
Recognition & Organization of Speech & Audio
 Recognition & Organization of Speech & Audio Dan Ellis http://labrosa.ee.columbia.edu/ Outline 1 2 3 Introducing Projects in speech, music & audio Summary overview - Dan Ellis 21-9-28-1 1 Sound organization
Recognition & Organization of Speech & Audio Dan Ellis http://labrosa.ee.columbia.edu/ Outline 1 2 3 Introducing Projects in speech, music & audio Summary overview - Dan Ellis 21-9-28-1 1 Sound organization
Speech Enhancement Based on Deep Neural Networks
 Speech Enhancement Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu and Jun Du at USTC 1 Outline and Talk Agenda In Signal Processing Letter,
Speech Enhancement Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu and Jun Du at USTC 1 Outline and Talk Agenda In Signal Processing Letter,
Robust Neural Encoding of Speech in Human Auditory Cortex
 Robust Neural Encoding of Speech in Human Auditory Cortex Nai Ding, Jonathan Z. Simon Electrical Engineering / Biology University of Maryland, College Park Auditory Processing in Natural Scenes How is
Robust Neural Encoding of Speech in Human Auditory Cortex Nai Ding, Jonathan Z. Simon Electrical Engineering / Biology University of Maryland, College Park Auditory Processing in Natural Scenes How is
Summary Table Voluntary Product Accessibility Template. Supports. Please refer to. Supports. Please refer to
 Date Aug-07 Name of product SMART Board 600 series interactive whiteboard SMART Board 640, 660 and 680 interactive whiteboards address Section 508 standards as set forth below Contact for more information
Date Aug-07 Name of product SMART Board 600 series interactive whiteboard SMART Board 640, 660 and 680 interactive whiteboards address Section 508 standards as set forth below Contact for more information
Analysis of Emotion Recognition using Facial Expressions, Speech and Multimodal Information
 Analysis of Emotion Recognition using Facial Expressions, Speech and Multimodal Information C. Busso, Z. Deng, S. Yildirim, M. Bulut, C. M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, S. Narayanan Emotion
Analysis of Emotion Recognition using Facial Expressions, Speech and Multimodal Information C. Busso, Z. Deng, S. Yildirim, M. Bulut, C. M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, S. Narayanan Emotion
This is a guide for volunteers in UTS HELPS Buddy Program. UTS.EDU.AU/CURRENT-STUDENTS/SUPPORT/HELPS/
 VOLUNTEER GUIDE This is a guide for volunteers in UTS HELPS Buddy Program. UTS.EDU.AU/CURRENT-STUDENTS/SUPPORT/HELPS/ CONTENTS 1 2 3 4 5 Introduction: Your role as a Buddy Getting started Helping with
VOLUNTEER GUIDE This is a guide for volunteers in UTS HELPS Buddy Program. UTS.EDU.AU/CURRENT-STUDENTS/SUPPORT/HELPS/ CONTENTS 1 2 3 4 5 Introduction: Your role as a Buddy Getting started Helping with
Adaptation of Classification Model for Improving Speech Intelligibility in Noise
 1: (Junyoung Jung et al.: Adaptation of Classification Model for Improving Speech Intelligibility in Noise) (Regular Paper) 23 4, 2018 7 (JBE Vol. 23, No. 4, July 2018) https://doi.org/10.5909/jbe.2018.23.4.511
1: (Junyoung Jung et al.: Adaptation of Classification Model for Improving Speech Intelligibility in Noise) (Regular Paper) 23 4, 2018 7 (JBE Vol. 23, No. 4, July 2018) https://doi.org/10.5909/jbe.2018.23.4.511
Houghton Mifflin Harcourt Avancemos!, Level correlated to the
 Houghton Mifflin Harcourt Avancemos!, Level 4 2018 correlated to the READING 1. Read closely to determine what the text says explicitly and to make logical inferences from it; cite specific textual evidence
Houghton Mifflin Harcourt Avancemos!, Level 4 2018 correlated to the READING 1. Read closely to determine what the text says explicitly and to make logical inferences from it; cite specific textual evidence
Communication. Jess Walsh
 Communication Jess Walsh Introduction. Douglas Bank is a home for young adults with severe learning disabilities. Good communication is important for the service users because it s easy to understand the
Communication Jess Walsh Introduction. Douglas Bank is a home for young adults with severe learning disabilities. Good communication is important for the service users because it s easy to understand the
ITU-T. FG AVA TR Version 1.0 (10/2013) Part 3: Using audiovisual media A taxonomy of participation
 Part 3: Using audiovisual media A taxonomy of participation") International Telecommunication Union ITU-T TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU FG AVA TR Version 1.0 (10/2013) Focus Group on Audiovisual Media Accessibility Technical Report Part 3: Using
International Telecommunication Union ITU-T TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU FG AVA TR Version 1.0 (10/2013) Focus Group on Audiovisual Media Accessibility Technical Report Part 3: Using
Note: This document describes normal operational functionality. It does not include maintenance and troubleshooting procedures.
 Date: 18 Nov 2013 Voluntary Accessibility Template (VPAT) This Voluntary Product Accessibility Template (VPAT) describes accessibility of Polycom s C100 and CX100 family against the criteria described
Date: 18 Nov 2013 Voluntary Accessibility Template (VPAT) This Voluntary Product Accessibility Template (VPAT) describes accessibility of Polycom s C100 and CX100 family against the criteria described