CONSTRAINED SEMI-SUPERVISED LEARNING ATTRIBUTES USING ATTRIBUTES AND COMPARATIVE
|
|
|
- Matilda Smith
- 5 years ago
- Views:
Transcription





1 CONSTRAINED SEMI-SUPERVISED LEARNING USING ATTRIBUTES AND COMPARATIVE ATTRIBUTES Abhinav Shrivastava, Saurabh Singh, Abhinav Gupta The Robotics Institute Carnegie Mellon University

![and Parikh, ECCV 2012]](/docs-images/87/97366157/images/2-2.jpg "[Vijayanarasimhan and")
![Grauman, CVPR 2011] [Kapoor](/docs-images/87/97366157/images/2-3.jpg "et al.")
![, ICCV 2007] [von [Qi et Ahn](/docs-images/87/97366157/images/2-4.jpg "al., and CVPR Dabbish, 2008]")
![[Joshi 2004], et [Russell al.](/docs-images/87/97366157/images/2-5.jpg ", CVPR et 2009] al.")
2 SUPERVISION BIG-DATA ACTIVE LEARNING SUPERVISED [Prakash and Parikh, ECCV 2012] [Vijayanarasimhan and Grauman, CVPR 2011] [Kapoor et al., ICCV 2007] [von [Qi et Ahn al., and CVPR Dabbish, 2008] [Joshi 2004], et [Russell al., CVPR et 2009] al., IJCV [Siddiquie 2009] and Gupta, CVPR 2010] 2




3 SUPERVISION UNSUPERVISED ACTIVE LEARNING SUPERVISED [Russell et al., CVPR 2006] [Kang et al., ICCV 2011] 3
4 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED [Zhu, TR, 2005], [Chunsheng Fang, Slides, 2009] 4
5 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED BOOTSTRAPPING Labeled Seed Examples Train Models Unlabeled Data Select Candidates Amphitheatre Amphitheatre Add to Labeled Set [Efron and Tibshirani, 1993] 5
6 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED BOOTSTRAPPING Labeled Seed Examples Retrain Models Unlabeled Data Select Candidates Amphitheatre Amphitheatre Add to Labeled Set [Curran et al., PACL 2007] 6




7 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED BOOTSTRAPPING Labeled Seed Examples Retrain Models Unlabeled Data Select Candidates Amphitheatre Amphitheatre Add to Labeled Set 25 th Iteration [Curran et al., PACL 2007] 7

8 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED BOOTSTRAPPING Labeled Seed Examples Retrain Models Unlabeled Data Select Candidates Amphitheatre Amphitheatre + Auditorium Add to Labeled Set 25 th Iteration Semantic Drift [Curran et al., PACL 2007] 8

9 UNSUPERVISED SUPERVISION SEMI-SUPERVISED ACTIVE LEARNING SUPERVISED GRAPH-BASED METHODS [Ebert et al., ECCV 2010] [Fergus et al., NIPS 2009] 9
10 OUR APPROACH Amphitheatre Amphitheatre Auditorium Auditorium [Carlson et al., NAACL HLT Workshop on SSL for NLP 2009] 10
11 Amphitheatre OUR APPROACH Joint Learning Amphitheatre Auditorium Auditorium Share Data [Carlson et al., NAACL HLT Workshop on SSL for NLP 2009] 11

![al., CVPR 2009] BINARY](/docs-images/87/97366157/images/12-1.jpg "ATTRIBUTES (BA) Conference")
12 [Farhadi et al., CVPR 2009] [Lampert et al., CVPR 2009] BINARY ATTRIBUTES (BA) Conference Room Banquet Hall


13 BINARY ATTRIBUTES (BA) Amphitheatre Auditorium [Farhadi et al., CVPR 2009] [Lampert et al., CVPR 2009] 13
14 BINARY ATTRIBUTES (BA) Tables and Chairs Large Seating Capacity Conference Room Indoor Banquet Hall Amphitheatre Man-made Auditorium [Patterson and Hays, CVPR 2012]
15 Auditorium 15

16 Auditorium 16



17 Auditorium 17
18 SHARING VIA DISSIMILARITY Amphitheatre Auditorium Has Larger Circular Structures [Parikh and Grauman, ICCV 2011] [Gupta and Davis, ECCV 2008] 18


19 Amphitheatre Auditorium? 19
20 Amphitheatre Auditorium 20

21 Amphitheatre Auditorium 21
22 DISSIMILARITY COMPARATIVE ATTRIBUTES Has Larger Circular Structures [Parikh and Grauman, ICCV 2011] [Gupta and Davis, ECCV 2008] 22
23 DISSIMILARITY COMPARATIVE ATTRIBUTES Has Larger Circular Structures Features GIST RGB (Tiny Image) Line Histogram of: Length Orientation LAB histogram [Parikh and Grauman, ICCV 2011] [Gupta and Davis, ECCV 2008] [Hays and Efros, SIGGRAPH 2007] [Oliva and Torralba, 2006] [Torralba et al., PAMI, 2008] 23
24 DISSIMILARITY COMPARATIVE ATTRIBUTES Has Larger Circular Structures Classifier Boosted Decision Tree [Hoiem et al., IJCV 2007] Has Larger Circular Structures or [Parikh and Grauman, ICCV 2011] [Gupta and Davis, ECCV 2008] 24
25 COMPARATIVE ATTRIBUTES Is More Open Amphitheatre > Barn Amphitheatre > Conference Room Desert > Barn Has Taller Structures Church (Outdoor) > Cemetery Barn > Cemetery [Parikh and Grauman, ICCV 2011] [Gupta and Davis, ECCV 2008] 25
26 Labeled Seed Examples Amphitheatre Selected Candidates Bootstrapping Amphitheatre Auditorium Auditorium 26
27 Labeled Seed Examples Amphitheatre Bootstrapping Amphitheatre Selected Candidates Our Approach (Constrained Bootstrapping) Amphitheatre Attributes Indoor Has Seat Rows Auditorium Auditorium Comparative Attributes Auditorium Has Larger Circular Structures 27

28 more space larger structures indoor has grass Bedroom Banquet bedroom banquet hall Scene Classifiers Unlabeled Data Labeled Data Attribute Classifiers has more space has larger structures Training Pairwise Data Comparative Attribute Classifiers [Gupta and Davis, ECCV 2008] Conference Room Banquet Hall Promoted Instances 28










29 Iteration 40 Iteration 1 Seed Examples Conference Room Introspection 29








30 Our Approach BA Constraints Bootstrapping Seed Images Amphitheatre 30







31 Our Approach BA Constraints Bootstrapping Seed Images Bridge 31
32 EXPERIMENTAL EVALUATION 32
33 CONTROL EXPERIMENTS # Images (SUN Database) 15 Scene Classes 2 (seed) Black-box Binary Attributes (BA) 25 (separate) Black-box Comparative Attributes (CA) 25 (separate) Unlabeled Dataset 18,000 (Distractors) (9,500) Test Set 50 SUN Database : [Xiao et al., CVPR 2010] 33
34 CONTROL EXPERIMENTS 34
35 CONTROL EXPERIMENTS 35

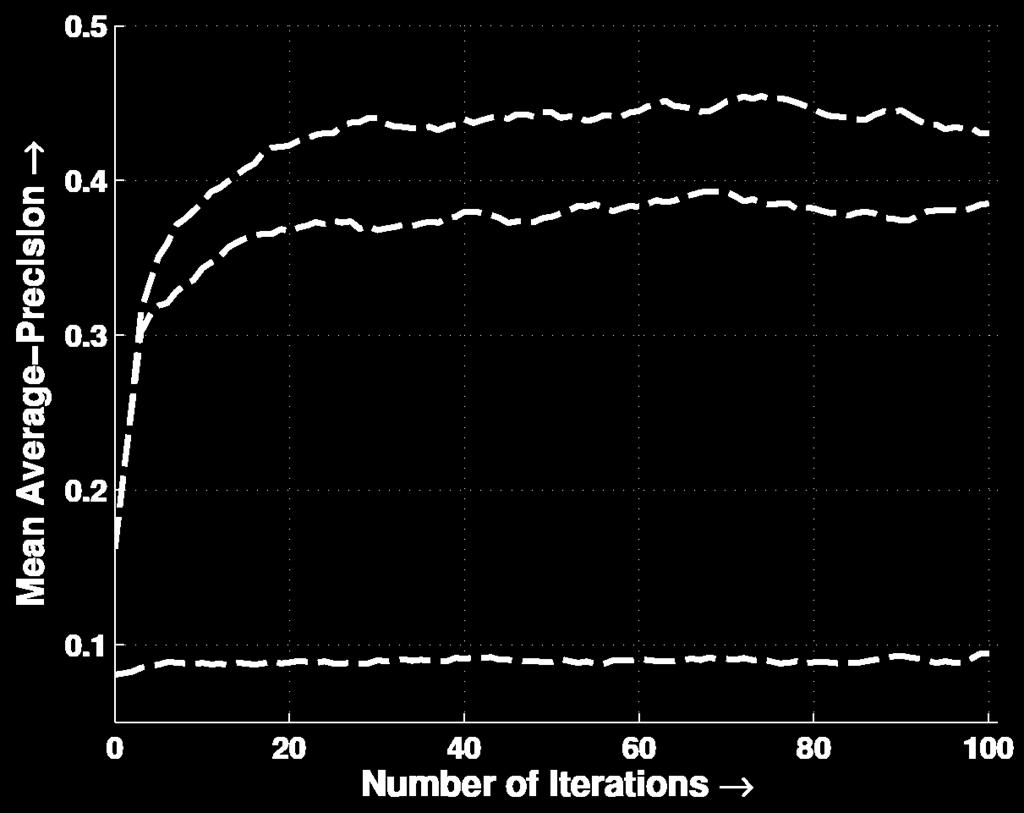
36 CONTROL EXPERIMENTS 36
37 CONTROL EXPERIMENTS 37
38 \\ CONTROL EXPERIMENTS 38
39 \\ CONTROL EXPERIMENTS Eigen Functions: [Fergus et al., NIPS 2009] 39

















40 Iterations Seed Images Banquet Hall
41 CONTROL EXPERIMENTS # Images (SUN Database) 15 Scene Classes 2 (seed) Black-box Binary Attributes (BA) 25 (separate) Black-box Comparative Attributes (CA) 25 (separate) Unlabeled Dataset 18,000 (Distractors) (9,500) Test Set 50 SUN Database : [Xiao et al., CVPR 2010] 41
42 CO-TRAINING (SMALL SCALE) # Images (SUN Database) 15 Scene Classes 2 (seed) Black-box Binary Attributes (BA) Black-box Comparative Attributes (CA) 15x2 (seed) 15x2 (seed) Unlabeled Dataset 18,000 (Distractors) (9,500) Test Set 50 SUN Database : [Xiao et al., CVPR 2010] 42






















43 Our Approach Iteration-60 Iteration-1 Bootstrapping Iteration-60 Iteration-1 Seed Images Bedroom 43

44 SCENE CLASSIFICATION Eigen Functions: [Fergus et al., NIPS 2009] 44
45 CO-TRAINING (LARGE SCALE) 15 Scene Categories 25 Seed images / category Unlabeled Set 1Million (SUN Database + ImageNet) >95% distractors Improve 12 out of 15 scene classifiers SUN Database: [Xiao et al., CVPR 2010] ImageNet: [Deng et al., CVPR 2009] 45


46 CONCLUSION Sharing via Dissimilarities Amphitheatre Auditorium Has Larger Circular Structures Constrained Bootstrapping Labeled Seed Examples Amphitheatre Bootstrapping Amphitheatre Constrained Bootstrapping Amphitheatre Auditorium Auditorium Auditorium 46
47 more space larger structures indoor has grass Bedroom Banquet bedroom banquet hall Scene Classifiers Unlabeled Data Labeled Data Attribute Classifiers has more space has larger structures Training Pairwise Data Comparative Attribute Classifiers Conference Room Banquet Hall Promoted Instances 47
Putting Context into. Vision. September 15, Derek Hoiem
 Putting Context into Vision Derek Hoiem September 15, 2004 Questions to Answer What is context? How is context used in human vision? How is context currently used in computer vision? Conclusions Context
Putting Context into Vision Derek Hoiem September 15, 2004 Questions to Answer What is context? How is context used in human vision? How is context currently used in computer vision? Conclusions Context
Assigning Relative Importance to Scene Elements
 Assigning Relative Importance to Scene Elements Igor L. O Bastos, William Robson Schwartz Smart Surveillance Interest Group, Department of Computer Science Universidade Federal de Minas Gerais, Minas Gerais,
Assigning Relative Importance to Scene Elements Igor L. O Bastos, William Robson Schwartz Smart Surveillance Interest Group, Department of Computer Science Universidade Federal de Minas Gerais, Minas Gerais,
Power SVM: Generalization with Exemplar Classification Uncertainty
 Power SVM: Generalization with Exemplar Classification Uncertainty Weiyu Zhang Stella X. Yu Shang-Hua Teng University of Pennsylvania UC Berkeley / ICSI University of Southern California zhweiyu@seas.upenn.edu
Power SVM: Generalization with Exemplar Classification Uncertainty Weiyu Zhang Stella X. Yu Shang-Hua Teng University of Pennsylvania UC Berkeley / ICSI University of Southern California zhweiyu@seas.upenn.edu
Domain Generalization and Adaptation using Low Rank Exemplar Classifiers
 Domain Generalization and Adaptation using Low Rank Exemplar Classifiers 报告人 : 李文 苏黎世联邦理工学院计算机视觉实验室 李文 苏黎世联邦理工学院 9/20/2017 1 Outline Problems Domain Adaptation and Domain Generalization Low Rank Exemplar
Domain Generalization and Adaptation using Low Rank Exemplar Classifiers 报告人 : 李文 苏黎世联邦理工学院计算机视觉实验室 李文 苏黎世联邦理工学院 9/20/2017 1 Outline Problems Domain Adaptation and Domain Generalization Low Rank Exemplar
Object Recognition: Conceptual Issues. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman
 Object Recognition: Conceptual Issues Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman Issues in recognition The statistical viewpoint Generative vs. discriminative methods
Object Recognition: Conceptual Issues Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman Issues in recognition The statistical viewpoint Generative vs. discriminative methods
Action Recognition. Computer Vision Jia-Bin Huang, Virginia Tech. Many slides from D. Hoiem
 Action Recognition Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem This section: advanced topics Convolutional neural networks in vision Action recognition Vision and Language 3D
Action Recognition Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem This section: advanced topics Convolutional neural networks in vision Action recognition Vision and Language 3D
Comparative object similarity for improved recognition with few or no examples
 Comparative object similarity for improved recognition with few or no examples Gang Wang David Forsyth 2 Derek Hoiem 2 Dept. of Electrical and Computer Engineering 2 Dept. of Computer Science University
Comparative object similarity for improved recognition with few or no examples Gang Wang David Forsyth 2 Derek Hoiem 2 Dept. of Electrical and Computer Engineering 2 Dept. of Computer Science University
arxiv: v1 [cs.cv] 16 Jun 2012
![arxiv: v1 [cs.cv] 16 Jun 2012](/thumbs/74/70143056.jpg "arxiv: v1 [cs.cv] 16 Jun 2012") How important are Deformable Parts in the Deformable Parts Model? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Carnegie Mellon University arxiv:1206.3714v1 [cs.cv] 16 Jun 2012 Abstract. The main
How important are Deformable Parts in the Deformable Parts Model? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Carnegie Mellon University arxiv:1206.3714v1 [cs.cv] 16 Jun 2012 Abstract. The main
Reading Between The Lines: Object Localization Using Implicit Cues from Image Tags
 Reading Between The Lines: Object Localization Using Implicit Cues from Image Tags Sung Ju Hwang and Kristen Grauman Department of Computer Science University of Texas at Austin {sjhwang,grauman}@cs.utexas.edu
Reading Between The Lines: Object Localization Using Implicit Cues from Image Tags Sung Ju Hwang and Kristen Grauman Department of Computer Science University of Texas at Austin {sjhwang,grauman}@cs.utexas.edu
Object Detectors Emerge in Deep Scene CNNs
 Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Toward a Taxonomy and Computational Models of Abnormalities in Images
 Toward a Taxonomy and Computational Models of Abnormalities in Images Babak Saleh Dept. of Computer Science Rutgers University New Jersey, USA Ahmed Elgammal Dept. of Computer Science Rutgers University
Toward a Taxonomy and Computational Models of Abnormalities in Images Babak Saleh Dept. of Computer Science Rutgers University New Jersey, USA Ahmed Elgammal Dept. of Computer Science Rutgers University
Attentional Masking for Pre-trained Deep Networks
 Attentional Masking for Pre-trained Deep Networks IROS 2017 Marcus Wallenberg and Per-Erik Forssén Computer Vision Laboratory Department of Electrical Engineering Linköping University 2014 2017 Per-Erik
Attentional Masking for Pre-trained Deep Networks IROS 2017 Marcus Wallenberg and Per-Erik Forssén Computer Vision Laboratory Department of Electrical Engineering Linköping University 2014 2017 Per-Erik
2. Related Work. 1 Throughout this paper we refer to rank as a real-valued score.
 Relative Attributes Devi Parih Toyota Technological Institute Chicago (TTIC) dparih@ttic.edu Kristen Grauman University of Texas at Austin grauman@cs.utexas.edu Abstract Human-nameable visual attributes
Relative Attributes Devi Parih Toyota Technological Institute Chicago (TTIC) dparih@ttic.edu Kristen Grauman University of Texas at Austin grauman@cs.utexas.edu Abstract Human-nameable visual attributes
CS4495 Computer Vision Introduction to Recognition. Aaron Bobick School of Interactive Computing
 CS4495 Computer Vision Introduction to Recognition Aaron Bobick School of Interactive Computing What does recognition involve? Source: Fei Fei Li, Rob Fergus, Antonio Torralba. Verification: is that
CS4495 Computer Vision Introduction to Recognition Aaron Bobick School of Interactive Computing What does recognition involve? Source: Fei Fei Li, Rob Fergus, Antonio Torralba. Verification: is that
Family Member Identification from Photo Collections
 2015 IEEE Winter Conference on Applications of Computer Vision Family Member Identification from Photo Collections Qieyun Dai 1,2 Peter Carr 2 Leonid Sigal 2 Derek Hoiem 1 1 University of Illinois at Urbana-Champaign
2015 IEEE Winter Conference on Applications of Computer Vision Family Member Identification from Photo Collections Qieyun Dai 1,2 Peter Carr 2 Leonid Sigal 2 Derek Hoiem 1 1 University of Illinois at Urbana-Champaign
Deep Networks and Beyond. Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University
 Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Describing Clothing by Semantic Attributes
 Describing Clothing by Semantic Attributes Huizhong Chen 1, Andrew Gallagher 2,3, and Bernd Girod 1 Department of Electrical Engineering, Stanford University, Stanford, California 1 Kodak Research Laboratories,
Describing Clothing by Semantic Attributes Huizhong Chen 1, Andrew Gallagher 2,3, and Bernd Girod 1 Department of Electrical Engineering, Stanford University, Stanford, California 1 Kodak Research Laboratories,
Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling
 AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
Active Deformable Part Models Inference
 Active Deformable Part Models Inference Menglong Zhu Nikolay Atanasov George J. Pappas Kostas Daniilidis GRASP Laboratory, University of Pennsylvania 3330 Walnut Street, Philadelphia, PA 19104, USA Abstract.
Active Deformable Part Models Inference Menglong Zhu Nikolay Atanasov George J. Pappas Kostas Daniilidis GRASP Laboratory, University of Pennsylvania 3330 Walnut Street, Philadelphia, PA 19104, USA Abstract.
Generic object recognition May 17 th, 2018
 Generic object recognition May 17 th, 2018 Yong Jae Lee UC Davis Visual words Map high dimensional descriptors to tokens/words by quantizing the feature space Quantize via clustering, let cluster centers
Generic object recognition May 17 th, 2018 Yong Jae Lee UC Davis Visual words Map high dimensional descriptors to tokens/words by quantizing the feature space Quantize via clustering, let cluster centers
GIANT: Geo-Informative Attributes for Location Recognition and Exploration
 GIANT: Geo-Informative Attributes for Location Recognition and Exploration Quan Fang, Jitao Sang, Changsheng Xu Institute of Automation, Chinese Academy of Sciences October 23, 2013 Where is this? La Sagrada
GIANT: Geo-Informative Attributes for Location Recognition and Exploration Quan Fang, Jitao Sang, Changsheng Xu Institute of Automation, Chinese Academy of Sciences October 23, 2013 Where is this? La Sagrada
Learning visual biases from human imagination
 Learning visual biases from human imagination Carl Vondrick Hamed Pirsiavash Aude Oliva Antonio Torralba Massachusetts Institute of Technology University of Maryland, Baltimore County {vondrick,oliva,torralba}@mit.edu
Learning visual biases from human imagination Carl Vondrick Hamed Pirsiavash Aude Oliva Antonio Torralba Massachusetts Institute of Technology University of Maryland, Baltimore County {vondrick,oliva,torralba}@mit.edu
Analyzing Semantic Segmentation Using Hybrid Human-Machine CRFs
 2013 IEEE Conference on Computer Vision and Pattern Recognition Analyzing Semantic Segmentation Using Hybrid Human-Machine CRFs Roozbeh Mottaghi UCLA roozbehm@cs.ucla.edu Sanja Fidler, Jian Yao, Raquel
2013 IEEE Conference on Computer Vision and Pattern Recognition Analyzing Semantic Segmentation Using Hybrid Human-Machine CRFs Roozbeh Mottaghi UCLA roozbehm@cs.ucla.edu Sanja Fidler, Jian Yao, Raquel
Towards image captioning and evaluation. Vikash Sehwag, Qasim Nadeem
 Towards image captioning and evaluation Vikash Sehwag, Qasim Nadeem Overview Why automatic image captioning? Overview of two caption evaluation metrics Paper: Captioning with Nearest-Neighbor approaches
Towards image captioning and evaluation Vikash Sehwag, Qasim Nadeem Overview Why automatic image captioning? Overview of two caption evaluation metrics Paper: Captioning with Nearest-Neighbor approaches
Medical Image Analysis
 Medical Image Analysis 1 Co-trained convolutional neural networks for automated detection of prostate cancer in multiparametric MRI, 2017, Medical Image Analysis 2 Graph-based prostate extraction in t2-weighted
Medical Image Analysis 1 Co-trained convolutional neural networks for automated detection of prostate cancer in multiparametric MRI, 2017, Medical Image Analysis 2 Graph-based prostate extraction in t2-weighted
Part 1: Bag-of-words models. by Li Fei-Fei (Princeton)
") Part 1: Bag-of-words models by Li Fei-Fei (Princeton) Object Bag of words Analogy to documents Of all the sensory impressions proceeding to the brain, the visual experiences are the dominant ones. Our
Part 1: Bag-of-words models by Li Fei-Fei (Princeton) Object Bag of words Analogy to documents Of all the sensory impressions proceeding to the brain, the visual experiences are the dominant ones. Our
Krista A. Ehinger. Centre for Vision Research, York University
 Krista A. Ehinger Centre for Vision Research York University 4700 Keele St, Toronto, ON M3J 1P3 Canada Phone: 647-676-5533 Email: kehinger@yorku.ca Website: www.kehinger.com Education 2007-2013 Ph.D. in
Krista A. Ehinger Centre for Vision Research York University 4700 Keele St, Toronto, ON M3J 1P3 Canada Phone: 647-676-5533 Email: kehinger@yorku.ca Website: www.kehinger.com Education 2007-2013 Ph.D. in
Complementary Computing for Visual Tasks: Meshing Computer Vision with Human Visual Processing
 Complementary Computing for Visual Tasks: Meshing Computer Vision with Human Visual Processing Ashish Kapoor, Desney Tan, Pradeep Shenoy and Eric Horvitz Microsoft Research, Redmond, WA 98052, USA University
Complementary Computing for Visual Tasks: Meshing Computer Vision with Human Visual Processing Ashish Kapoor, Desney Tan, Pradeep Shenoy and Eric Horvitz Microsoft Research, Redmond, WA 98052, USA University
When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment
 When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment Honglin Zheng1, Tianlang Chen2, Jiebo Luo3 Department of Computer Science University of Rochester, Rochester,
When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment Honglin Zheng1, Tianlang Chen2, Jiebo Luo3 Department of Computer Science University of Rochester, Rochester,
arxiv: v1 [cs.cv] 21 Nov 2018
![arxiv: v1 [cs.cv] 21 Nov 2018](/thumbs/93/113462225.jpg "arxiv: v1 [cs.cv] 21 Nov 2018") Rethinking ImageNet Pre-training Kaiming He Ross Girshick Piotr Dollár Facebook AI Research (FAIR) arxiv:1811.8883v1 [cs.cv] 21 Nov 218 Abstract We report competitive results on object detection and instance
Rethinking ImageNet Pre-training Kaiming He Ross Girshick Piotr Dollár Facebook AI Research (FAIR) arxiv:1811.8883v1 [cs.cv] 21 Nov 218 Abstract We report competitive results on object detection and instance
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION
 MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
The Attraction of Visual Attention to Texts in Real-World Scenes
 The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
Neuro-Inspired Statistical. Rensselaer Polytechnic Institute National Science Foundation
 Neuro-Inspired Statistical Pi Prior Model lfor Robust Visual Inference Qiang Ji Rensselaer Polytechnic Institute National Science Foundation 1 Status of Computer Vision CV has been an active area for over
Neuro-Inspired Statistical Pi Prior Model lfor Robust Visual Inference Qiang Ji Rensselaer Polytechnic Institute National Science Foundation 1 Status of Computer Vision CV has been an active area for over
Improved object categorization and detection using comparative object similarity
 Improved object categorization and detection using comparative object similarity Gang Wang, Member, IEEE, David Forsyth, Fellow, IEEE, Derek Hoiem, Member, IEEE Abstract Due to the intrinsic long-tailed
Improved object categorization and detection using comparative object similarity Gang Wang, Member, IEEE, David Forsyth, Fellow, IEEE, Derek Hoiem, Member, IEEE Abstract Due to the intrinsic long-tailed
The Visual World as Seen by Neurons and Machines. Aaron Walsman, Akanksha Saran
 The Visual World as Seen by Neurons and Machines Aaron Walsman, Akanksha Saran PPA dataset What does the data encode? Clustering Exemplars clustered together Very few clusters had same category images
The Visual World as Seen by Neurons and Machines Aaron Walsman, Akanksha Saran PPA dataset What does the data encode? Clustering Exemplars clustered together Very few clusters had same category images
arxiv: v1 [cs.cv] 1 Aug 2018
![arxiv: v1 [cs.cv] 1 Aug 2018](/thumbs/93/113443481.jpg "arxiv: v1 [cs.cv] 1 Aug 2018") arxiv:88.257v [cs.cv] Aug 8 Subitizing with Variational Autoencoders Rijnder Wever, Tom F.H. Runia University of Amsterdam, Intelligent Sensory Information Systems Abstract. Numerosity, the number of objects
arxiv:88.257v [cs.cv] Aug 8 Subitizing with Variational Autoencoders Rijnder Wever, Tom F.H. Runia University of Amsterdam, Intelligent Sensory Information Systems Abstract. Numerosity, the number of objects
Leveraging Cognitive Context for Object Recognition
 Leveraging Cognitive Context for Object Recognition Wallace Lawson, Laura Hiatt, J. Gregory Trafton Naval Research Laboratory Washington, DC USA Abstract Contextual information can greatly improve both
Leveraging Cognitive Context for Object Recognition Wallace Lawson, Laura Hiatt, J. Gregory Trafton Naval Research Laboratory Washington, DC USA Abstract Contextual information can greatly improve both
Group Behavior Analysis and Its Applications
 Group Behavior Analysis and Its Applications CVPR 2015 Tutorial Lecturers: Hyun Soo Park (University of Pennsylvania) Wongun Choi (NEC America Laboratory) Schedule 08:30am-08:50am 08:50am-09:50am 09:50am-10:10am
Group Behavior Analysis and Its Applications CVPR 2015 Tutorial Lecturers: Hyun Soo Park (University of Pennsylvania) Wongun Choi (NEC America Laboratory) Schedule 08:30am-08:50am 08:50am-09:50am 09:50am-10:10am
Efficient Boosted Exemplar-based Face Detection
 Efficient Boosted Exemplar-based Face Detection Haoxiang Li, Zhe Lin, Jonathan Brandt, Xiaohui Shen, Gang Hua Stevens Institute of Technology Hoboken, NJ 07030 {hli18, ghua}@stevens.edu Adobe Research
Efficient Boosted Exemplar-based Face Detection Haoxiang Li, Zhe Lin, Jonathan Brandt, Xiaohui Shen, Gang Hua Stevens Institute of Technology Hoboken, NJ 07030 {hli18, ghua}@stevens.edu Adobe Research
Estimating scene typicality from human ratings and image features
 Estimating scene typicality from human ratings and image features Krista A. Ehinger (kehinger@mit.edu) Department of Brain & Cognitive Sciences, MIT, 77 Massachusetts Ave. Jianxiong Xiao (jxiao@csail.mit.edu)
Estimating scene typicality from human ratings and image features Krista A. Ehinger (kehinger@mit.edu) Department of Brain & Cognitive Sciences, MIT, 77 Massachusetts Ave. Jianxiong Xiao (jxiao@csail.mit.edu)
The Role of Context Selection in Object Detection
 YU et al.: THE ROLE OF COTEXT SELECTIO I OBJECT DETECTIO 1 The Role of Context Selection in Object Detection Ruichi (Rich) Yu 1 richyu@cs.umd.edu Xi (Stephen) Chen 2 chnxi@microsoft.com Vlad I. Morariu
YU et al.: THE ROLE OF COTEXT SELECTIO I OBJECT DETECTIO 1 The Role of Context Selection in Object Detection Ruichi (Rich) Yu 1 richyu@cs.umd.edu Xi (Stephen) Chen 2 chnxi@microsoft.com Vlad I. Morariu
The University of Tokyo, NVAIL Partner Yoshitaka Ushiku
 Recognize, Describe, and Generate: Introduction of Recent Work at MIL The University of Tokyo, NVAIL Partner Yoshitaka Ushiku MIL: Machine Intelligence Laboratory Beyond Human Intelligence Based on Cyber-Physical
Recognize, Describe, and Generate: Introduction of Recent Work at MIL The University of Tokyo, NVAIL Partner Yoshitaka Ushiku MIL: Machine Intelligence Laboratory Beyond Human Intelligence Based on Cyber-Physical
Nonparametric Method for Data-driven Image Captioning
 Nonparametric Method for Data-driven Image Captioning Rebecca Mason and Eugene Charniak Brown Laboratory for Linguistic Information Processing (BLLIP) Brown University, Providence, RI 02912 {rebecca,ec}@cs.brown.edu
Nonparametric Method for Data-driven Image Captioning Rebecca Mason and Eugene Charniak Brown Laboratory for Linguistic Information Processing (BLLIP) Brown University, Providence, RI 02912 {rebecca,ec}@cs.brown.edu
Image Description with a Goal: Building Efficient Discriminating Expressions for Images
 Image Description with a Goal: Building Efficient Discriminating Expressions for Images Amir Sadovnik Cornell University Yi-I Chiu National Cheng Kung University Noah Snavely Cornell University as2373@cornell.edu
Image Description with a Goal: Building Efficient Discriminating Expressions for Images Amir Sadovnik Cornell University Yi-I Chiu National Cheng Kung University Noah Snavely Cornell University as2373@cornell.edu
Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics
 Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics Bora Celikkale a, Aykut Erdem a, Erkut Erdem a, a Department of Computer Engineering, Hacettepe University,
Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics Bora Celikkale a, Aykut Erdem a, Erkut Erdem a, a Department of Computer Engineering, Hacettepe University,
Recognizing Jumbled Images: The Role of Local and Global Information in Image Classification
 Recognizing Jumbled Images: The Role of Local and Global Information in Image Classification Devi Parikh Toyota Technological Institute, Chicago (TTIC) dparikh@ttic.edu Abstract The performance of current
Recognizing Jumbled Images: The Role of Local and Global Information in Image Classification Devi Parikh Toyota Technological Institute, Chicago (TTIC) dparikh@ttic.edu Abstract The performance of current
Scenes Categorization based on Appears Objects Probability
 2016 IEEE 6th International Conference on System Engineering and Technology (ICSET) Oktober 3-4, 2016 Bandung Indonesia Scenes Categorization based on Appears Objects Probability Marzuki 1, Egi Muhamad
2016 IEEE 6th International Conference on System Engineering and Technology (ICSET) Oktober 3-4, 2016 Bandung Indonesia Scenes Categorization based on Appears Objects Probability Marzuki 1, Egi Muhamad
A Study on Automatic Age Estimation using a Large Database
 A Study on Automatic Age Estimation using a Large Database Guodong Guo WVU Guowang Mu NCCU Yun Fu BBN Technologies Charles Dyer UW-Madison Thomas Huang UIUC Abstract In this paper we study some problems
A Study on Automatic Age Estimation using a Large Database Guodong Guo WVU Guowang Mu NCCU Yun Fu BBN Technologies Charles Dyer UW-Madison Thomas Huang UIUC Abstract In this paper we study some problems
Recognizing Scenes by Simulating Implied Social Interaction Networks
 Recognizing Scenes by Simulating Implied Social Interaction Networks MaryAnne Fields and Craig Lennon Army Research Laboratory, Aberdeen, MD, USA Christian Lebiere and Michael Martin Carnegie Mellon University,
Recognizing Scenes by Simulating Implied Social Interaction Networks MaryAnne Fields and Craig Lennon Army Research Laboratory, Aberdeen, MD, USA Christian Lebiere and Michael Martin Carnegie Mellon University,
Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge
 Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge Ryota Hinami 1,2, Tao Mei 3, and Shin ichi Satoh 2,1 1 The University of Tokyo, 2 National Institute of Infomatics,
Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge Ryota Hinami 1,2, Tao Mei 3, and Shin ichi Satoh 2,1 1 The University of Tokyo, 2 National Institute of Infomatics,
Region Proposals. Jan Hosang, Rodrigo Benenson, Piotr Dollar, Bernt Schiele
 Region Proposals Jan Hosang, Rodrigo Benenson, Piotr Dollar, Bernt Schiele Who has read a proposal paper? 2 Who has read a proposal paper? Who knows what Average Recall is? 2 Who has read a proposal paper?
Region Proposals Jan Hosang, Rodrigo Benenson, Piotr Dollar, Bernt Schiele Who has read a proposal paper? 2 Who has read a proposal paper? Who knows what Average Recall is? 2 Who has read a proposal paper?
Understanding Image Impressiveness Inspired by Instantaneous Human Perceptual Cues
 Understanding Image Impressiveness Inspired by Instantaneous Human Perceptual Cues Jufeng Yang 1, Y a n Sun 1, Jie Liang 1, Yong-Liang Yang 2, Ming-Ming Cheng 1 1 College of Computer and Control Engineering
Understanding Image Impressiveness Inspired by Instantaneous Human Perceptual Cues Jufeng Yang 1, Y a n Sun 1, Jie Liang 1, Yong-Liang Yang 2, Ming-Ming Cheng 1 1 College of Computer and Control Engineering
Hierarchical Convolutional Features for Visual Tracking
 Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Vision: Over Ov view Alan Yuille
 Vision: Overview Alan Yuille Why is Vision Hard? Complexity and Ambiguity of Images. Range of Vision Tasks. More 10x10 images 256^100 = 6.7 x 10 ^240 than the total number of images seen by all humans
Vision: Overview Alan Yuille Why is Vision Hard? Complexity and Ambiguity of Images. Range of Vision Tasks. More 10x10 images 256^100 = 6.7 x 10 ^240 than the total number of images seen by all humans
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik UC Berkeley Tech Report @ http://arxiv.org/abs/1311.2524! Detection
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik UC Berkeley Tech Report @ http://arxiv.org/abs/1311.2524! Detection
Natural Language Processing - A Survey MSR UW Summer Institute
 Natural Language Processing - A Survey Talk @ MSR UW Summer Institute 2016 - Margaret Mitchell Cognition Group Microsoft Research Yejin Choi Computer Science & Engineering Accessibility in the Past Reading
Natural Language Processing - A Survey Talk @ MSR UW Summer Institute 2016 - Margaret Mitchell Cognition Group Microsoft Research Yejin Choi Computer Science & Engineering Accessibility in the Past Reading
Learning to Disambiguate by Asking Discriminative Questions Supplementary Material
 Learning to Disambiguate by Asking Discriminative Questions Supplementary Material Yining Li 1 Chen Huang 2 Xiaoou Tang 1 Chen Change Loy 1 1 Department of Information Engineering, The Chinese University
Learning to Disambiguate by Asking Discriminative Questions Supplementary Material Yining Li 1 Chen Huang 2 Xiaoou Tang 1 Chen Change Loy 1 1 Department of Information Engineering, The Chinese University
Fine-Grained Image Classification Using Color Exemplar Classifiers
 Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, and Qingming Huang 1,4 1 School of Computer and Control Engineering,
Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, and Qingming Huang 1,4 1 School of Computer and Control Engineering,
Convolutional Neural Networks (CNN)
") Convolutional Neural Networks (CNN) Algorithm and Some Applications in Computer Vision Luo Hengliang Institute of Automation June 10, 2014 Luo Hengliang (Institute of Automation) Convolutional Neural Networks
Convolutional Neural Networks (CNN) Algorithm and Some Applications in Computer Vision Luo Hengliang Institute of Automation June 10, 2014 Luo Hengliang (Institute of Automation) Convolutional Neural Networks
Fine-Grained Image Classification Using Color Exemplar Classifiers
 Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, Qingming Huang 1, 4 1 School of Computer and Control Engineering,
Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, Qingming Huang 1, 4 1 School of Computer and Control Engineering,
LSTD: A Low-Shot Transfer Detector for Object Detection
 LSTD: A Low-Shot Transfer Detector for Object Detection Hao Chen 1,2, Yali Wang 1, Guoyou Wang 2, Yu Qiao 1,3 1 Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, China 2 Huazhong
LSTD: A Low-Shot Transfer Detector for Object Detection Hao Chen 1,2, Yali Wang 1, Guoyou Wang 2, Yu Qiao 1,3 1 Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, China 2 Huazhong
Lecture 11 Visual recognition
 Lecture 11 Visual recognition Descriptors (wrapping up) An introduction to recognition Image classification Silvio Savarese Lecture 11-12-Feb-14 The big picture Feature Detection e.g. DoG Feature Description
Lecture 11 Visual recognition Descriptors (wrapping up) An introduction to recognition Image classification Silvio Savarese Lecture 11-12-Feb-14 The big picture Feature Detection e.g. DoG Feature Description
Shu Kong. Department of Computer Science, UC Irvine
 Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
Multi-attention Guided Activation Propagation in CNNs
 Multi-attention Guided Activation Propagation in CNNs Xiangteng He and Yuxin Peng (B) Institute of Computer Science and Technology, Peking University, Beijing, China pengyuxin@pku.edu.cn Abstract. CNNs
Multi-attention Guided Activation Propagation in CNNs Xiangteng He and Yuxin Peng (B) Institute of Computer Science and Technology, Peking University, Beijing, China pengyuxin@pku.edu.cn Abstract. CNNs
Supplementary Material: Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning
 Supplementary Material: Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning Soravit Changpinyo U. of Southern California Los Angeles, CA schangpi@usc.edu Wei-Lun Chao U. of Southern California
Supplementary Material: Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning Soravit Changpinyo U. of Southern California Los Angeles, CA schangpi@usc.edu Wei-Lun Chao U. of Southern California
Differential Attention for Visual Question Answering
 Differential Attention for Visual Question Answering Badri Patro and Vinay P. Namboodiri IIT Kanpur { badri,vinaypn }@iitk.ac.in Abstract In this paper we aim to answer questions based on images when provided
Differential Attention for Visual Question Answering Badri Patro and Vinay P. Namboodiri IIT Kanpur { badri,vinaypn }@iitk.ac.in Abstract In this paper we aim to answer questions based on images when provided
Efficient Salient Region Detection with Soft Image Abstraction
 Efficient Salient Region Detection with Soft Image Abstraction Ming-Ming Cheng Jonathan Warrell Wen-Yan Lin Shuai Zheng Vibhav Vineet Nigel Crook Vision Group, Oxford Brookes University Abstract Detecting
Efficient Salient Region Detection with Soft Image Abstraction Ming-Ming Cheng Jonathan Warrell Wen-Yan Lin Shuai Zheng Vibhav Vineet Nigel Crook Vision Group, Oxford Brookes University Abstract Detecting
Shu Kong. Department of Computer Science, UC Irvine
 Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge and philosophy 4. Fine-grained classification with
Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge and philosophy 4. Fine-grained classification with
Using human brain activity to guide machine learning
 www.nature.com/scientificreports Received: 16 March 2017 Accepted: 2 August 2017 Published: xx xx xxxx OPEN Using human brain activity to guide machine learning Ruth C. Fong 1,3, Walter J. Scheirer 2,3
www.nature.com/scientificreports Received: 16 March 2017 Accepted: 2 August 2017 Published: xx xx xxxx OPEN Using human brain activity to guide machine learning Ruth C. Fong 1,3, Walter J. Scheirer 2,3
Vision, Language, Reasoning
 CS 2770: Computer Vision Vision, Language, Reasoning Prof. Adriana Kovashka University of Pittsburgh March 5, 2019 Plan for this lecture Image captioning Tool: Recurrent neural networks Captioning for
CS 2770: Computer Vision Vision, Language, Reasoning Prof. Adriana Kovashka University of Pittsburgh March 5, 2019 Plan for this lecture Image captioning Tool: Recurrent neural networks Captioning for
Exemplar-Driven Top-Down Saliency Detection via Deep Association
 Exemplar-Driven Top-Down Saliency Detection via Deep Association Shengfeng He 1, Rynson W.H. Lau 1, and Qingxiong Yang 2 1 Department of Computer Science, City University of Hong Kong 2 School of Information
Exemplar-Driven Top-Down Saliency Detection via Deep Association Shengfeng He 1, Rynson W.H. Lau 1, and Qingxiong Yang 2 1 Department of Computer Science, City University of Hong Kong 2 School of Information
Predicting the location of interactees in novel human-object interactions
 In Proceedings of the Asian Conference on Computer Vision (ACCV), 2014. Predicting the location of interactees in novel human-object interactions Chao-Yeh Chen and Kristen Grauman University of Texas at
In Proceedings of the Asian Conference on Computer Vision (ACCV), 2014. Predicting the location of interactees in novel human-object interactions Chao-Yeh Chen and Kristen Grauman University of Texas at
Learning Saliency Maps for Object Categorization
 Learning Saliency Maps for Object Categorization Frank Moosmann, Diane Larlus, Frederic Jurie INRIA Rhône-Alpes - GRAVIR - CNRS, {Frank.Moosmann,Diane.Larlus,Frederic.Jurie}@inrialpes.de http://lear.inrialpes.fr
Learning Saliency Maps for Object Categorization Frank Moosmann, Diane Larlus, Frederic Jurie INRIA Rhône-Alpes - GRAVIR - CNRS, {Frank.Moosmann,Diane.Larlus,Frederic.Jurie}@inrialpes.de http://lear.inrialpes.fr
Computational Cognitive Science
 Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning
 Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning Soravit Changpinyo U. of Southern California Los Angeles, CA schangpi@usc.edu Wei-Lun Chao U. of Southern California Los Angeles, CA
Predicting Visual Exemplars of Unseen Classes for Zero-Shot Learning Soravit Changpinyo U. of Southern California Los Angeles, CA schangpi@usc.edu Wei-Lun Chao U. of Southern California Los Angeles, CA
Discovering Important People and Objects for Egocentric Video Summarization
 Discovering Important People and Objects for Egocentric Video Summarization Yong Jae Lee, Joydeep Ghosh, and Kristen Grauman University of Texas at Austin yjlee0222@utexas.edu, joydeep@ece.utexas.edu,
Discovering Important People and Objects for Egocentric Video Summarization Yong Jae Lee, Joydeep Ghosh, and Kristen Grauman University of Texas at Austin yjlee0222@utexas.edu, joydeep@ece.utexas.edu,
IN this paper we examine the role of shape prototypes in
 On the Role of Shape Prototypes in Hierarchical Models of Vision Michael D. Thomure, Melanie Mitchell, and Garrett T. Kenyon To appear in Proceedings of the International Joint Conference on Neural Networks
On the Role of Shape Prototypes in Hierarchical Models of Vision Michael D. Thomure, Melanie Mitchell, and Garrett T. Kenyon To appear in Proceedings of the International Joint Conference on Neural Networks
Hierarchical Local Binary Pattern for Branch Retinal Vein Occlusion Recognition
 Hierarchical Local Binary Pattern for Branch Retinal Vein Occlusion Recognition Zenghai Chen 1, Hui Zhang 2, Zheru Chi 1, and Hong Fu 1,3 1 Department of Electronic and Information Engineering, The Hong
Hierarchical Local Binary Pattern for Branch Retinal Vein Occlusion Recognition Zenghai Chen 1, Hui Zhang 2, Zheru Chi 1, and Hong Fu 1,3 1 Department of Electronic and Information Engineering, The Hong
Brute-Force Facial Landmark Analysis With A 140,000-Way Classifier
 Brute-Force Facial Landmark Analysis With A 4,-Way Classifier Mengtian Li Laszlo Jeni Deva Ramanan The Robotics Institute, Carnegie Mellon University {mtli, laszlojeni, deva}@cmu.edu Abstract We propose
Brute-Force Facial Landmark Analysis With A 4,-Way Classifier Mengtian Li Laszlo Jeni Deva Ramanan The Robotics Institute, Carnegie Mellon University {mtli, laszlojeni, deva}@cmu.edu Abstract We propose
Inferring Analogous Attributes
 Inferring Analogous Attributes Chao-Yeh Chen and Kristen Grauman University of Texas at Austin chaoyeh@cs.utexas.edu, grauman@cs.utexas.edu Abstract The appearance of an attribute can vary considerably
Inferring Analogous Attributes Chao-Yeh Chen and Kristen Grauman University of Texas at Austin chaoyeh@cs.utexas.edu, grauman@cs.utexas.edu Abstract The appearance of an attribute can vary considerably
8:30 BREAKFAST 10:20 COFFEE BREAK - POSTERS
 MIT Camp mpus us, Buil ildi ding 46-6-30 02, 43 Vas assar St reet et, Ca mbri ridg dge, MA 0213 9 http tp:/ ://s /sun uns. s.mit.ed edu 8:30 BREAKFAST BUILDING SCENE REPRESENTATIONS: COMPUTER VISION 9:00
MIT Camp mpus us, Buil ildi ding 46-6-30 02, 43 Vas assar St reet et, Ca mbri ridg dge, MA 0213 9 http tp:/ ://s /sun uns. s.mit.ed edu 8:30 BREAKFAST BUILDING SCENE REPRESENTATIONS: COMPUTER VISION 9:00
Acquiring Visual Classifiers from Human Imagination
 Acquiring Visual Classifiers from Human Imagination Carl Vondrick, Hamed Pirsiavash, Aude Oliva, Antonio Torralba Massachusetts Institute of Technology {vondrick,hpirsiav,oliva,torralba}@mit.edu White
Acquiring Visual Classifiers from Human Imagination Carl Vondrick, Hamed Pirsiavash, Aude Oliva, Antonio Torralba Massachusetts Institute of Technology {vondrick,hpirsiav,oliva,torralba}@mit.edu White
Saliency aggregation: Does unity make strength?
 Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
Exploration Strategies for Incremental Learning of Object-Based Visual Saliency
 5th International Conference on Development and Learning and on Epigenetic Robotics Aug 3-6, 205. Providence, RI USA Exploration Strategies for Incremental Learning of Object-Based Visual Saliency Céline
5th International Conference on Development and Learning and on Epigenetic Robotics Aug 3-6, 205. Providence, RI USA Exploration Strategies for Incremental Learning of Object-Based Visual Saliency Céline
What is and What is not a Salient Object? Learning Salient Object Detector by Ensembling Linear Exemplar Regressors
 What is and What is not a Salient Object? Learning Salient Object Detector by Ensembling Linear Exemplar Regressors Changqun Xia 1, Jia Li 1,2, Xiaowu Chen 1, Anlin Zheng 1, Yu Zhang 1 1 State Key Laboratory
What is and What is not a Salient Object? Learning Salient Object Detector by Ensembling Linear Exemplar Regressors Changqun Xia 1, Jia Li 1,2, Xiaowu Chen 1, Anlin Zheng 1, Yu Zhang 1 1 State Key Laboratory
DEEP CONVOLUTIONAL ACTIVATION FEATURES FOR LARGE SCALE BRAIN TUMOR HISTOPATHOLOGY IMAGE CLASSIFICATION AND SEGMENTATION
 DEEP CONVOLUTIONAL ACTIVATION FEATURES FOR LARGE SCALE BRAIN TUMOR HISTOPATHOLOGY IMAGE CLASSIFICATION AND SEGMENTATION Yan Xu1,2, Zhipeng Jia2,, Yuqing Ai2,, Fang Zhang2,, Maode Lai4, Eric I-Chao Chang2
DEEP CONVOLUTIONAL ACTIVATION FEATURES FOR LARGE SCALE BRAIN TUMOR HISTOPATHOLOGY IMAGE CLASSIFICATION AND SEGMENTATION Yan Xu1,2, Zhipeng Jia2,, Yuqing Ai2,, Fang Zhang2,, Maode Lai4, Eric I-Chao Chang2
Face Gender Classification on Consumer Images in a Multiethnic Environment
 Face Gender Classification on Consumer Images in a Multiethnic Environment Wei Gao and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn
Face Gender Classification on Consumer Images in a Multiethnic Environment Wei Gao and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn
Recognising Human-Object Interaction via Exemplar based Modelling
 2013 IEEE International Conference on Computer Vision Recognising Human-Object Interaction via Exemplar based Modelling Jian-Fang Hu, Wei-Shi Zheng, Jianhuang Lai, Shaogang Gong, and Tao Xiang School of
2013 IEEE International Conference on Computer Vision Recognising Human-Object Interaction via Exemplar based Modelling Jian-Fang Hu, Wei-Shi Zheng, Jianhuang Lai, Shaogang Gong, and Tao Xiang School of
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION. {zzwang, ruihuang, lwan,
 EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
Evaluation of the Impetuses of Scan Path in Real Scene Searching
 Evaluation of the Impetuses of Scan Path in Real Scene Searching Chen Chi, Laiyun Qing,Jun Miao, Xilin Chen Graduate University of Chinese Academy of Science,Beijing 0009, China. Key Laboratory of Intelligent
Evaluation of the Impetuses of Scan Path in Real Scene Searching Chen Chi, Laiyun Qing,Jun Miao, Xilin Chen Graduate University of Chinese Academy of Science,Beijing 0009, China. Key Laboratory of Intelligent
Automatic Semantic Face Recognition
 Automatic Semantic Face Recognition Nawaf Yousef Almudhahka Mark S. Nixon University of Southampton Southampton, United Kingdom {nya1g14,msn,jsh2}@ecs.soton.ac.uk Jonathon S. Hare Abstract Recent expansion
Automatic Semantic Face Recognition Nawaf Yousef Almudhahka Mark S. Nixon University of Southampton Southampton, United Kingdom {nya1g14,msn,jsh2}@ecs.soton.ac.uk Jonathon S. Hare Abstract Recent expansion
Understanding Image Virality
 Understanding Image Virality Arturo Deza UC Santa Barbara deza@dyns.ucsb.edu Devi Parikh Virginia Tech parikh@vt.edu Abstract Virality of online content on social networking websites is an important but
Understanding Image Virality Arturo Deza UC Santa Barbara deza@dyns.ucsb.edu Devi Parikh Virginia Tech parikh@vt.edu Abstract Virality of online content on social networking websites is an important but
Where should saliency models look next?
 Where should saliency models look next? Zoya Bylinskii 1, Adrià Recasens 1, Ali Borji 2, Aude Oliva 1, Antonio Torralba 1, and Frédo Durand 1 1 Computer Science and Artificial Intelligence Laboratory Massachusetts
Where should saliency models look next? Zoya Bylinskii 1, Adrià Recasens 1, Ali Borji 2, Aude Oliva 1, Antonio Torralba 1, and Frédo Durand 1 1 Computer Science and Artificial Intelligence Laboratory Massachusetts
Object-Centric Anomaly Detection by Attribute-Based Reasoning
 2013 IEEE Conference on Computer Vision and Pattern Recognition Object-Centric Anomaly Detection by Attribute-Based Reasoning Babak Saleh Rutgers University babaks@cs.rutgers.edu Ali Farhadi University
2013 IEEE Conference on Computer Vision and Pattern Recognition Object-Centric Anomaly Detection by Attribute-Based Reasoning Babak Saleh Rutgers University babaks@cs.rutgers.edu Ali Farhadi University
What Helps Where And Why? Semantic Relatedness for Knowledge Transfer
 What Helps Where And Why? Semantic Relatedness for Knowledge Transfer Marcus Rohrbach 1,2 Michael Stark 1,2 György Szarvas 1 Iryna Gurevych 1 Bernt Schiele 1,2 1 Department of Computer Science, TU Darmstadt
What Helps Where And Why? Semantic Relatedness for Knowledge Transfer Marcus Rohrbach 1,2 Michael Stark 1,2 György Szarvas 1 Iryna Gurevych 1 Bernt Schiele 1,2 1 Department of Computer Science, TU Darmstadt
Just Noticeable Differences in Visual Attributes
 Just Noticeable Differences in Visual Attributes Aron Yu University of Texas at Austin aron.yu@utexas.edu Kristen Grauman University of Texas at Austin grauman@cs.utexas.edu Abstract We explore the problem
Just Noticeable Differences in Visual Attributes Aron Yu University of Texas at Austin aron.yu@utexas.edu Kristen Grauman University of Texas at Austin grauman@cs.utexas.edu Abstract We explore the problem
Learned Region Sparsity and Diversity Also Predict Visual Attention
 Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Effects of varying presentation time on long-term recognition memory for scenes: Verbatim and gist representations
 Mem Cogn (2017) 45:390 403 DOI 10.3758/s13421-016-0672-1 Effects of varying presentation time on long-term recognition memory for scenes: Verbatim and gist representations Fahad N. Ahmad 1 & Morris Moscovitch
Mem Cogn (2017) 45:390 403 DOI 10.3758/s13421-016-0672-1 Effects of varying presentation time on long-term recognition memory for scenes: Verbatim and gist representations Fahad N. Ahmad 1 & Morris Moscovitch
Natural Scene Categorization: from Humans to Computers
 Natural Scene Categorization: from Humans to Computers Li Fei-Fei Beckman Institute, ECE, Psychology http://visionlab.ece.uiuc.edu #1: natural scene categorization entails little attention (Rufin VanRullen,
Natural Scene Categorization: from Humans to Computers Li Fei-Fei Beckman Institute, ECE, Psychology http://visionlab.ece.uiuc.edu #1: natural scene categorization entails little attention (Rufin VanRullen,