SUPPRESSION OF MUSICAL NOISE IN ENHANCED SPEECH USING PRE-IMAGE ITERATIONS. Christina Leitner and Franz Pernkopf
|
|
|
- Caroline Hall
- 6 years ago
- Views:
Transcription
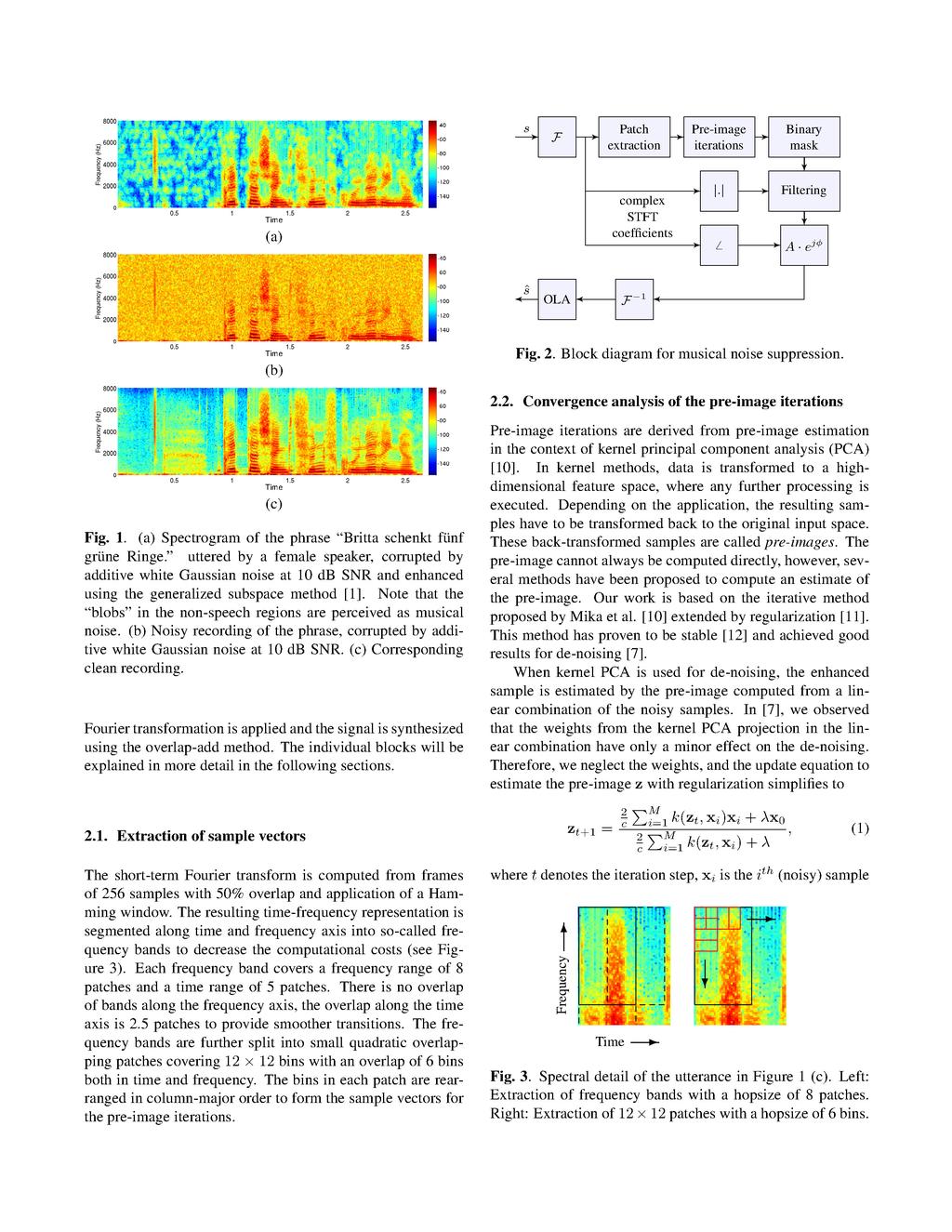
1 2th European Signal Processing Conference (EUSIPCO 212) Bucharest, Romania, August 27-31, 212 SUPPRESSION OF MUSICAL NOISE IN ENHANCED SPEECH USING PRE-IMAGE ITERATIONS Christina Leitner and Franz Pernkopf Signal Processing and Speech Communication Laboratory Graz University of Technology Inffeldgasse 16c, 81 Graz, Austria ABSTRACT In this paper, we present a post-processing method for musical noise suppression in enhanced speech recordings. The method uses pre-image iterations computed patch-wise on complex-valued spectral data of the enhanced signal to discriminate between speech and non-speech regions. From this knowledge, a binary mask is derived to suppress musical noise in the non-speech regions, where it is most disturbing. The method is evaluated using objective quality measures of the PEASS toolbox. These measures confirm that a suppression of artifacts and an increase in overall quality for several noise conditions is achieved. Index Terms Speech enhancement, musical noise suppression, pre-image problem 1. INTRODUCTION The occurrence of musical noise is a major problem in speech enhancement. Musical noise is caused by inaccuracies of the enhancement algorithm at hand, it originates from a random amplification of frequency bins that change quickly over time. Musical noise is perceived as twittering and can severely degrade the perceptual quality of enhanced speech recordings. If it is too prominent, it may even be more disturbing than the interference before enhancement. Figure 1 (a) shows the spectrogram of a speech recording with interfering white Gaussian noise at 1 db signal-to-noise ration () that has been enhanced by the generalized subspace method [1]. The blobs in the non-speech region of the spectrogram are perceived as musical noise. Much research has been carried out on how to avoid or suppress musical noise, either by modifying the enhancement method or by post-processing the enhanced utterances. In the context of spectral subtraction, spectral flooring [2] and oversubtraction [3] were introduced. For post-processing musical noise/speech classification of the spectral bins and subsequent manipulation [4], post-filtering [5] and smoothing of the weighting gains [6] were proposed. We gratefully acknowledge funding by the Austrian Science Fund (FWF) under the project number S161-N13. Recently, we showed how the knowledge gained from the convergence behaviour of pre-image iterations applied for speech de-noising [7] can be employed to suppress musical noise in enhanced speech recordings [8]. In this paper, we perform pre-image iterations on enhanced signals, in contrast to [8], where they were applied on the noisy signal. From the number of iterations until convergence a binary mask is derived that segments the signal into speech and non-speech regions. This mask is used to suppress musical noise in nonspeech regions. Experiments were performed on speech data corrupted by additive white Gaussian noise at, 5, 1, and 15 db. The resulting speech recordings were evaluated using the PEASS toolbox [9]. The provided quality measures show an increase in overall quality and a decrease of artifacts - this is consistent with the subjective impression from listening. This paper is organized as follows: Section 2 introduces pre-image iterations and for musical noise suppression. Section 3 presents the experimental setup, the evaluation and the results. Section 4 concludes the paper. 2. MUSICAL NOISE SUPPRESSION USING PRE-IMAGE ITERATIONS Pre-image iterations were originally proposed for speech denoising. In [8], we introduced pre-image iterations for suppression of musical noise in enhanced speech recordings, i.e., the pre-image iterations were executed on the noisy signal before enhancement, while in this paper they are computed on the enhanced signal. For speech enhancement any method such as subspace methods or spectral subtraction can be used. The block diagram in Figure 2 illustrates the implementation: First the short-term Fourier transform is computed for the enhanced signals. Then patches are extracted from the resulting time-frequency representation. The pre-image iterations are used to derive a binary mask for speech/non-speech discrimination, that is further refined by morphological operations from image processing. This mask is used to filter the magnitude of the input signal. The resulting magnitude values are recombined with the phase of the input signal, the inverse EURASIP, ISSN
2 346
 Binary mask after the threshold operation (2). (b) Smoothed mask after the closing operation. 2.3. Computation of the binary mask and filtering (i.e. one patch), x denotes the sample for which the preimage is computed, M is the number of samples, k(, ) denotes the kernel function and λ is the regularization parameter.")

 shows the number of iterations (encoded as color) computed from the noisy signal as in [8], when maximally 6 iterations are executed.")
3 (a) (a) (b) (b) Fig. 4. Number of iterations for each time-frequency bin, (a) computed from the noisy signal, (b) computed from the enhanced signal. Fig. 5. (a) Binary mask after the threshold operation (2). (b) Smoothed mask after the closing operation Computation of the binary mask and filtering (i.e. one patch), x denotes the sample for which the preimage is computed, M is the number of samples, k(, ) denotes the kernel function and λ is the regularization parameter. We use a Gaussian kernel k(x i,x j ) = exp( x i x j 2 /c), wherecis its variance. For the estimation of the pre-image, equation (1) is iterated until convergence ofz t+1. From the number of iterations until convergence, useful information about the properties of the underlying signal can be derived. This is illustrated in Figure 4, where the number of iterations for each patch is visualized according to its position in the time-frequency plane. Figure 4 (a) shows the number of iterations (encoded as color) computed from the noisy signal as in [8], when maximally 6 iterations are executed. Non-integer values result from averaging between overlapping patches. A comparison to the noisy signal and the clean signal in Figure 1 (b) and (c), respectively, shows that the regions corresponding to speech need fewer iterations until convergence than the regions corresponding to noise. The different convergence behaviour is caused by the similarity measure of the kernel, which returns different values for speech and noise regions. We exploit this observation by setting a threshold to compute a binary mask for suppressing musical noise in non-speech regions. In this paper, we compute the number of iterations from a signal enhanced by the generalized subspace method [1] (see Figure 4 (b)). Again, we can discriminate between different regions, however the relation between the number of iterations and the content of the signal is not as clear as in the former case. Empirically, we observed that few iterations correspond mainly to speech regions, an intermediate number of iterations corresponds mostly to noise, and more iterations again correspond to speech regions. For the discrimination between speech and non-speech we set two thresholds, such that the iteration map is segmented as shown in Figure 5 (a): Region 1, in red, covers areas mainly corresponding to speech, while region 2, in blue, covers speech and noise areas. The operation for obtaining the maskmfor each bin is { 1 if n < a or n > b m = (2) otherwise, where m = 1 if there is speech, n is the number of iterations for a specific bin in the map and a and b are the two threshold values. The values for the thresholds are derived from experiments (see Section 3). To distinguish between noise and speech, the parts of the blue region within speech areas have to be removed. This is realized with techniques from image processing, namely morphological filtering such as dilation and erosion. The consecutive execution of these operations results in the so-called closing operation [13] that closes the holes in Figure 5 (a). As structural element a disk of radius 1 is used. Figure 5 (b) Fig. 6. Speech utterance from Figure 1 after musical noise suppression with the mask from Figure 5 (b). White areas mark regions where no energy is left - this can be avoided by leaving a noise floor instead of setting the spectrogram bins to zero. 347
4 OPS TPS IPS APS db dB dB dB Fig. 7. Overall perceptual score (OPS), target perceptual score (TPS), interference perceptual score (IPS), and artifact perceptual score (APS) computed from the development set for different values of the upper threshold b in different conditions. For the final experiments the threshold maximizing the APS was chosen OPS db 5dB 1dB 15dB TPS Subsp. Post p. Post. n. db 5dB 1dB 15dB IPS db 5dB 1dB 15dB APS db 5dB 1dB 15dB Fig. 8. Evaluation of overall perceptual score (OPS), target perceptual score (TPS), interference perceptual score (IPS), and artifact perceptual score (APS) for the generalized subspace method (), the proposed post-processing method for musical noise suppression (Post-processed), and the post-processing method from [7] (Post-proc. noisy). shows the resulting contiguous mask, which is subsequently applied to filter the magnitude of the STFT of the signal. Figure 6 represents the spectrogram after musical noise suppression Resynthesis After filtering, the inverse Fourier transformation is applied using the phase from the input signal. Finally, the audio signal is synthesized using the weighted overlap-add method [14]. 3. EXPERIMENTS For the evaluation of the approach, we performed experiments on a database with recordings of 6 speakers, 3 male and 3 female. Each speaker read a list of 2 sentences, which makes 12 sentences in total. The recording was performed with a close-talking microphone and 16 k sampling frequency. We performed experiments with additive white Gaussian noise 1 at, 5, 1, and 15 db, where the kernel variance for the pre-image iterations was was set to 3, 2,.5, and.25, respectively, and the regularization parameter λ was set to.5. The database was split into a development and a test 1 For other noise types the generalized subspace method produced less musical noise, therefore post-processing is not necessary. set, where the development set contains one sentence of each speaker and the test set contains the remaining 114 sentences. In [9], new quality measures for signals estimated by audio source separation algorithms were proposed. They were designed using the outcome of subjective listening tests. These measures show an improved correlation with subjective scores compared to formerly used measures. The measures evaluate four aspects of the signal: the global quality (OPS - overall perceptual score), the preservation of the target signal (TPS - target perceptual score), the suppression of other signals (IPS - interference perceptual score) and the absence of additional artificial noise (APS - artifact perceptual score). The scores range from to 1, high values denote better quality. We use these measures, because they allow for evaluation of the amount of musical noise by looking at the APS. To achieve good musical noise suppression, an accurate estimation of the speech regions is needed. The two thresholds in (2) are set as follows: The lower thresholdais fixed to 1.5, as there are few iteration counts in this range and only the interior of the speech region is affected that is properly treated by the closing operation anyway. For the upper threshold b, several values were tested on the development set. The one providing the best tradeoff between OPS and APS was taken, ensuring good quality as well as good musical noise suppres- 348
5 sion. Figure 7 shows the results on the development set in four noise conditions when the threshold is varied from 3 to 5. The final values 4, 4, 4.25, and 4.5 were chosen for the noise conditions of, 5, 1, and 15 db, respectively. For these values, the APS is maximized and good artifact suppression, i.e. musical noise suppression, is achieved, while the overall quality is still in the upper range (or maximized as well). Figure 8 shows the results for the test set with the optimal threshold settings. The recordings with suppressed musical noise achieve a better overall quality (OPS) than the original enhanced recordings and than the post-processing described in [7] for all levels except of db. They also score better in terms of absence of artifacts (APS), which confirms that the musical noise is efficiently suppressed. Furthermore, our approach also achieves better interference suppression (IPS), however in terms of target preservation (TPS) it is slightly weaker than to the original subspace method. This can be explained by the fact, that speech components may be attenuated by the application of the mask. Listening to the processed utterances and inspection of the spectrograms (see Figure 6) confirm that there is less musical noise after post-processing while almost all speech components are preserved. 2 Only in the case of fricatives speech is attenuated due to the low energy - this is reflected by the score for target preservation. 4. CONCLUSION AND FUTURE WORK In this paper, we proposed a method for musical noise suppression that relies on the knowledge gained from pre-image iterations executed on spectral data. Properties of the underlying signal can be inferred from the number of iterations until convergence and the spectral data can be segmented into speech and non-speech regions. We smooth the segmentation by applying image processing techniques and use the resulting binary mask to suppress musical noise in non-speech regions. This method can be applied as post-processing for any speech enhancement algorithm. We applied the method on speech recordings corrupted by additive white Gaussian noise at different s which have been enhanced by the generalized subspace method. For evaluation, we used the objective quality measures of the PEASS toolbox, which allow for an evaluation regarding four aspects: overall quality, preservation of the target signal, suppression of interfering signals, and absence of additional artificial noise. In terms of overall quality we achieve an improvement in almost all conditions. The score measuring the absence of additional noise increases. This confirms the reduction of musical noise. These results are consistent with the subjectively perceived quality that increases due to the attenuation of disturbing musical noise. 2 Audio examples are provided on tugraz.at/people/chrisl/audio/eusipco REFERENCES [1] Y. Hu and P. C. Loizou, A generalized subspace approach for enhancing speech corrupted by colored noise, IEEE Transactions on Speech and Audio Processing, vol. 11, pp , 23. [2] S. F. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE Transactions on Acoustics, Speech and Signal Processing, vol. 27, no. 2, pp , [3] M. Berouti, M. Schwartz, and J. Makhoul, Enhancement of speech corrupted by acoustic noise, in ICASSP, 1979, pp [4] Z. Goh, K.-C. Tan, and T. G. Tan, Postprocessing method for suppressing musical noise generated by spectral subtraction, IEEE Transactions on Speech and Audio Processing, vol. 6, no. 3, pp , [5] M. Klein and P. Kabal, Signal subspace speech enhancement with perceptual post-filtering, in ICASSP, 22, vol. 1, pp [6] T. Esch and P. Vary, Efficient musical noise suppression for speech enhancement systems, in ICASSP 29, 29, pp [7] C. Leitner and F. Pernkopf, Speech enhancement using pre-image iterations, ICASSP, in Press, 212. [8] C. Leitner and F. Pernkopf, Musical noise suppression for speech enhancement using pre-image iterations, IWSSIP, 212. [9] V. Emiya, E. Vincent, N. Harlander, and V. Hohmann, Subjective and objective quality assessment of audio source separation, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp , 211. [1] S. Mika, B. Schölkopf, A. Smola, K.-R. Müller, Matthias Scholz, and Gunnar Rätsch, Kernel PCA and de-noising in feature spaces, Advances in Neural Information Processing Systems 11, pp , [11] Tl. J. Abrahamsen and L. K. Hansen, Input space regularization stabilizes pre-images for kernel PCA denoising, in MLSP, 29. [12] C. Leitner and F. Pernkopf, The pre-image problem and kernel PCA for speech enhancement, in Advances in Nonlinear Speech Processing, vol. 715 of Lecture Notes in Computer Science, pp [13] R. C. Gonzalez and R. E. Woods, Digital Image Processing, Pearson Prentice Hall, 28. [14] D. Griffin and J. Lim, Signal estimation from modified short-time Fourier transform, IEEE Transactions on Acoustics, Speech and Signal Processing, vol. 32, no. 2, pp ,
Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components
 Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components Miss Bhagat Nikita 1, Miss Chavan Prajakta 2, Miss Dhaigude Priyanka 3, Miss Ingole Nisha 4, Mr Ranaware Amarsinh
Speech Enhancement Based on Spectral Subtraction Involving Magnitude and Phase Components Miss Bhagat Nikita 1, Miss Chavan Prajakta 2, Miss Dhaigude Priyanka 3, Miss Ingole Nisha 4, Mr Ranaware Amarsinh
Acoustic Signal Processing Based on Deep Neural Networks
 Acoustic Signal Processing Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu, Yanhui Tu, Qing Wang, Tian Gao, Jun Du, LiRong Dai Outline
Acoustic Signal Processing Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu, Yanhui Tu, Qing Wang, Tian Gao, Jun Du, LiRong Dai Outline
Speech Enhancement Based on Deep Neural Networks
 Speech Enhancement Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu and Jun Du at USTC 1 Outline and Talk Agenda In Signal Processing Letter,
Speech Enhancement Based on Deep Neural Networks Chin-Hui Lee School of ECE, Georgia Tech chl@ece.gatech.edu Joint work with Yong Xu and Jun Du at USTC 1 Outline and Talk Agenda In Signal Processing Letter,
ADVANCES in NATURAL and APPLIED SCIENCES
 ADVANCES in NATURAL and APPLIED SCIENCES ISSN: 1995-0772 Published BYAENSI Publication EISSN: 1998-1090 http://www.aensiweb.com/anas 2016 December10(17):pages 275-280 Open Access Journal Improvements in
ADVANCES in NATURAL and APPLIED SCIENCES ISSN: 1995-0772 Published BYAENSI Publication EISSN: 1998-1090 http://www.aensiweb.com/anas 2016 December10(17):pages 275-280 Open Access Journal Improvements in
Adaptation of Classification Model for Improving Speech Intelligibility in Noise
 1: (Junyoung Jung et al.: Adaptation of Classification Model for Improving Speech Intelligibility in Noise) (Regular Paper) 23 4, 2018 7 (JBE Vol. 23, No. 4, July 2018) https://doi.org/10.5909/jbe.2018.23.4.511
1: (Junyoung Jung et al.: Adaptation of Classification Model for Improving Speech Intelligibility in Noise) (Regular Paper) 23 4, 2018 7 (JBE Vol. 23, No. 4, July 2018) https://doi.org/10.5909/jbe.2018.23.4.511
CHAPTER 1 INTRODUCTION
 CHAPTER 1 INTRODUCTION 1.1 BACKGROUND Speech is the most natural form of human communication. Speech has also become an important means of human-machine interaction and the advancement in technology has
CHAPTER 1 INTRODUCTION 1.1 BACKGROUND Speech is the most natural form of human communication. Speech has also become an important means of human-machine interaction and the advancement in technology has
Speech Enhancement Using Deep Neural Network
 Speech Enhancement Using Deep Neural Network Pallavi D. Bhamre 1, Hemangi H. Kulkarni 2 1 Post-graduate Student, Department of Electronics and Telecommunication, R. H. Sapat College of Engineering, Management
Speech Enhancement Using Deep Neural Network Pallavi D. Bhamre 1, Hemangi H. Kulkarni 2 1 Post-graduate Student, Department of Electronics and Telecommunication, R. H. Sapat College of Engineering, Management
Codebook driven short-term predictor parameter estimation for speech enhancement
 Codebook driven short-term predictor parameter estimation for speech enhancement Citation for published version (APA): Srinivasan, S., Samuelsson, J., & Kleijn, W. B. (2006). Codebook driven short-term
Codebook driven short-term predictor parameter estimation for speech enhancement Citation for published version (APA): Srinivasan, S., Samuelsson, J., & Kleijn, W. B. (2006). Codebook driven short-term
Advanced Audio Interface for Phonetic Speech. Recognition in a High Noise Environment
 DISTRIBUTION STATEMENT A Approved for Public Release Distribution Unlimited Advanced Audio Interface for Phonetic Speech Recognition in a High Noise Environment SBIR 99.1 TOPIC AF99-1Q3 PHASE I SUMMARY
DISTRIBUTION STATEMENT A Approved for Public Release Distribution Unlimited Advanced Audio Interface for Phonetic Speech Recognition in a High Noise Environment SBIR 99.1 TOPIC AF99-1Q3 PHASE I SUMMARY
Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise
 4 Special Issue Speech-Based Interfaces in Vehicles Research Report Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise Hiroyuki Hoshino Abstract This
4 Special Issue Speech-Based Interfaces in Vehicles Research Report Noise-Robust Speech Recognition in a Car Environment Based on the Acoustic Features of Car Interior Noise Hiroyuki Hoshino Abstract This
International Journal of Scientific & Engineering Research, Volume 5, Issue 3, March ISSN
 International Journal of Scientific & Engineering Research, Volume 5, Issue 3, March-214 1214 An Improved Spectral Subtraction Algorithm for Noise Reduction in Cochlear Implants Saeed Kermani 1, Marjan
International Journal of Scientific & Engineering Research, Volume 5, Issue 3, March-214 1214 An Improved Spectral Subtraction Algorithm for Noise Reduction in Cochlear Implants Saeed Kermani 1, Marjan
Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency
 Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency Tetsuya Shimamura and Fumiya Kato Graduate School of Science and Engineering Saitama University 255 Shimo-Okubo,
Combination of Bone-Conducted Speech with Air-Conducted Speech Changing Cut-Off Frequency Tetsuya Shimamura and Fumiya Kato Graduate School of Science and Engineering Saitama University 255 Shimo-Okubo,
ARCHETYPAL ANALYSIS FOR AUDIO DICTIONARY LEARNING. Aleksandr Diment, Tuomas Virtanen
 ARCHETYPAL ANALYSIS FOR AUDIO DICTIONARY LEARNING Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Department of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
ARCHETYPAL ANALYSIS FOR AUDIO DICTIONARY LEARNING Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Department of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Enhancement of Reverberant Speech Using LP Residual Signal
 IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 8, NO. 3, MAY 2000 267 Enhancement of Reverberant Speech Using LP Residual Signal B. Yegnanarayana, Senior Member, IEEE, and P. Satyanarayana Murthy
IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 8, NO. 3, MAY 2000 267 Enhancement of Reverberant Speech Using LP Residual Signal B. Yegnanarayana, Senior Member, IEEE, and P. Satyanarayana Murthy
Performance Comparison of Speech Enhancement Algorithms Using Different Parameters
 Performance Comparison of Speech Enhancement Algorithms Using Different Parameters Ambalika, Er. Sonia Saini Abstract In speech communication system, background noise degrades the information or speech
Performance Comparison of Speech Enhancement Algorithms Using Different Parameters Ambalika, Er. Sonia Saini Abstract In speech communication system, background noise degrades the information or speech
Recurrent lateral inhibitory spiking networks for speech enhancement
 Recurrent lateral inhibitory spiking networks for speech enhancement Julie Wall University of East London j.wall@uel.ac.uk Cornelius Glackin neil.glackin@intelligentvoice.com Nigel Cannings nigel.cannings@intelligentvoice.com
Recurrent lateral inhibitory spiking networks for speech enhancement Julie Wall University of East London j.wall@uel.ac.uk Cornelius Glackin neil.glackin@intelligentvoice.com Nigel Cannings nigel.cannings@intelligentvoice.com
PCA Enhanced Kalman Filter for ECG Denoising
 IOSR Journal of Electronics & Communication Engineering (IOSR-JECE) ISSN(e) : 2278-1684 ISSN(p) : 2320-334X, PP 06-13 www.iosrjournals.org PCA Enhanced Kalman Filter for ECG Denoising Febina Ikbal 1, Prof.M.Mathurakani
IOSR Journal of Electronics & Communication Engineering (IOSR-JECE) ISSN(e) : 2278-1684 ISSN(p) : 2320-334X, PP 06-13 www.iosrjournals.org PCA Enhanced Kalman Filter for ECG Denoising Febina Ikbal 1, Prof.M.Mathurakani
Speech Enhancement, Human Auditory system, Digital hearing aid, Noise maskers, Tone maskers, Signal to Noise ratio, Mean Square Error
 Volume 119 No. 18 2018, 2259-2272 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ SUBBAND APPROACH OF SPEECH ENHANCEMENT USING THE PROPERTIES OF HUMAN AUDITORY
Volume 119 No. 18 2018, 2259-2272 ISSN: 1314-3395 (on-line version) url: http://www.acadpubl.eu/hub/ http://www.acadpubl.eu/hub/ SUBBAND APPROACH OF SPEECH ENHANCEMENT USING THE PROPERTIES OF HUMAN AUDITORY
USING AUDITORY SALIENCY TO UNDERSTAND COMPLEX AUDITORY SCENES
 USING AUDITORY SALIENCY TO UNDERSTAND COMPLEX AUDITORY SCENES Varinthira Duangudom and David V Anderson School of Electrical and Computer Engineering, Georgia Institute of Technology Atlanta, GA 30332
USING AUDITORY SALIENCY TO UNDERSTAND COMPLEX AUDITORY SCENES Varinthira Duangudom and David V Anderson School of Electrical and Computer Engineering, Georgia Institute of Technology Atlanta, GA 30332
Noise Cancellation using Adaptive Filters Algorithms
 Noise Cancellation using Adaptive Filters Algorithms Suman, Poonam Beniwal Department of ECE, OITM, Hisar, bhariasuman13@gmail.com Abstract Active Noise Control (ANC) involves an electro acoustic or electromechanical
Noise Cancellation using Adaptive Filters Algorithms Suman, Poonam Beniwal Department of ECE, OITM, Hisar, bhariasuman13@gmail.com Abstract Active Noise Control (ANC) involves an electro acoustic or electromechanical
Using Source Models in Speech Separation
 Using Source Models in Speech Separation Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Using Source Models in Speech Separation Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Biomedical. Measurement and Design ELEC4623. Lectures 15 and 16 Statistical Algorithms for Automated Signal Detection and Analysis
 Biomedical Instrumentation, Measurement and Design ELEC4623 Lectures 15 and 16 Statistical Algorithms for Automated Signal Detection and Analysis Fiducial points Fiducial point A point (or line) on a scale
Biomedical Instrumentation, Measurement and Design ELEC4623 Lectures 15 and 16 Statistical Algorithms for Automated Signal Detection and Analysis Fiducial points Fiducial point A point (or line) on a scale
The importance of phase in speech enhancement
 Available online at www.sciencedirect.com Speech Communication 53 (2011) 465 494 www.elsevier.com/locate/specom The importance of phase in speech enhancement Kuldip Paliwal, Kamil Wójcicki, Benjamin Shannon
Available online at www.sciencedirect.com Speech Communication 53 (2011) 465 494 www.elsevier.com/locate/specom The importance of phase in speech enhancement Kuldip Paliwal, Kamil Wójcicki, Benjamin Shannon
FREQUENCY COMPRESSION AND FREQUENCY SHIFTING FOR THE HEARING IMPAIRED
 FREQUENCY COMPRESSION AND FREQUENCY SHIFTING FOR THE HEARING IMPAIRED Francisco J. Fraga, Alan M. Marotta National Institute of Telecommunications, Santa Rita do Sapucaí - MG, Brazil Abstract A considerable
FREQUENCY COMPRESSION AND FREQUENCY SHIFTING FOR THE HEARING IMPAIRED Francisco J. Fraga, Alan M. Marotta National Institute of Telecommunications, Santa Rita do Sapucaí - MG, Brazil Abstract A considerable
ReSound NoiseTracker II
 Abstract The main complaint of hearing instrument wearers continues to be hearing in noise. While directional microphone technology exploits spatial separation of signal from noise to improve listening
Abstract The main complaint of hearing instrument wearers continues to be hearing in noise. While directional microphone technology exploits spatial separation of signal from noise to improve listening
SPEECH recordings taken from realistic environments typically
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING 1 Coupled Dictionaries for Exemplar-based Speech Enhancement and Automatic Speech Recognition Deepak Baby, Student Member, IEEE, Tuomas Virtanen,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING 1 Coupled Dictionaries for Exemplar-based Speech Enhancement and Automatic Speech Recognition Deepak Baby, Student Member, IEEE, Tuomas Virtanen,
INTEGRATING THE COCHLEA S COMPRESSIVE NONLINEARITY IN THE BAYESIAN APPROACH FOR SPEECH ENHANCEMENT
 INTEGRATING THE COCHLEA S COMPRESSIVE NONLINEARITY IN THE BAYESIAN APPROACH FOR SPEECH ENHANCEMENT Eric Plourde and Benoît Champagne Department of Electrical and Computer Engineering, McGill University
INTEGRATING THE COCHLEA S COMPRESSIVE NONLINEARITY IN THE BAYESIAN APPROACH FOR SPEECH ENHANCEMENT Eric Plourde and Benoît Champagne Department of Electrical and Computer Engineering, McGill University
Perception Optimized Deep Denoising AutoEncoders for Speech Enhancement
 Perception Optimized Deep Denoising AutoEncoders for Speech Enhancement Prashanth Gurunath Shivakumar, Panayiotis Georgiou University of Southern California, Los Angeles, CA, USA pgurunat@uscedu, georgiou@sipiuscedu
Perception Optimized Deep Denoising AutoEncoders for Speech Enhancement Prashanth Gurunath Shivakumar, Panayiotis Georgiou University of Southern California, Los Angeles, CA, USA pgurunat@uscedu, georgiou@sipiuscedu
Pattern Playback in the '90s
 Pattern Playback in the '90s Malcolm Slaney Interval Research Corporation 180 l-c Page Mill Road, Palo Alto, CA 94304 malcolm@interval.com Abstract Deciding the appropriate representation to use for modeling
Pattern Playback in the '90s Malcolm Slaney Interval Research Corporation 180 l-c Page Mill Road, Palo Alto, CA 94304 malcolm@interval.com Abstract Deciding the appropriate representation to use for modeling
Development of novel algorithm by combining Wavelet based Enhanced Canny edge Detection and Adaptive Filtering Method for Human Emotion Recognition
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 12, Issue 9 (September 2016), PP.67-72 Development of novel algorithm by combining
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 12, Issue 9 (September 2016), PP.67-72 Development of novel algorithm by combining
A MATHEMATICAL ALGORITHM FOR ECG SIGNAL DENOISING USING WINDOW ANALYSIS
 Biomed Pap Med Fac Univ Palacky Olomouc Czech Repub. 7, 151(1):73 78. H. SadAbadi, M. Ghasemi, A. Ghaffari 73 A MATHEMATICAL ALGORITHM FOR ECG SIGNAL DENOISING USING WINDOW ANALYSIS Hamid SadAbadi a *,
Biomed Pap Med Fac Univ Palacky Olomouc Czech Repub. 7, 151(1):73 78. H. SadAbadi, M. Ghasemi, A. Ghaffari 73 A MATHEMATICAL ALGORITHM FOR ECG SIGNAL DENOISING USING WINDOW ANALYSIS Hamid SadAbadi a *,
Noise-Robust Speech Recognition Technologies in Mobile Environments
 Noise-Robust Speech Recognition echnologies in Mobile Environments Mobile environments are highly influenced by ambient noise, which may cause a significant deterioration of speech recognition performance.
Noise-Robust Speech Recognition echnologies in Mobile Environments Mobile environments are highly influenced by ambient noise, which may cause a significant deterioration of speech recognition performance.
Juan Carlos Tejero-Calado 1, Janet C. Rutledge 2, and Peggy B. Nelson 3
 PRESERVING SPECTRAL CONTRAST IN AMPLITUDE COMPRESSION FOR HEARING AIDS Juan Carlos Tejero-Calado 1, Janet C. Rutledge 2, and Peggy B. Nelson 3 1 University of Malaga, Campus de Teatinos-Complejo Tecnol
PRESERVING SPECTRAL CONTRAST IN AMPLITUDE COMPRESSION FOR HEARING AIDS Juan Carlos Tejero-Calado 1, Janet C. Rutledge 2, and Peggy B. Nelson 3 1 University of Malaga, Campus de Teatinos-Complejo Tecnol
Monitoring Cardiac Stress Using Features Extracted From S1 Heart Sounds
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 271-275 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com Monitoring Cardiac Stress Using Features Extracted From S1 Heart Sounds Biju V.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 271-275 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com Monitoring Cardiac Stress Using Features Extracted From S1 Heart Sounds Biju V.
Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions
 3 Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions Ryoichi Takashima, Tetsuya Takiguchi and Yasuo Ariki Graduate School of System Informatics, Kobe University,
3 Single-Channel Sound Source Localization Based on Discrimination of Acoustic Transfer Functions Ryoichi Takashima, Tetsuya Takiguchi and Yasuo Ariki Graduate School of System Informatics, Kobe University,
Edge Detection using Mathematical Morphology
 Edge Detection using Mathematical Morphology Neil Scott June 5, 2007 2 Outline Introduction to Mathematical Morphology The Structuring Element Basic and Composite Operations Morphological Edge Detection
Edge Detection using Mathematical Morphology Neil Scott June 5, 2007 2 Outline Introduction to Mathematical Morphology The Structuring Element Basic and Composite Operations Morphological Edge Detection
White Paper: micon Directivity and Directional Speech Enhancement
 White Paper: micon Directivity and Directional Speech Enhancement www.siemens.com Eghart Fischer, Henning Puder, Ph. D., Jens Hain Abstract: This paper describes a new, optimized directional processing
White Paper: micon Directivity and Directional Speech Enhancement www.siemens.com Eghart Fischer, Henning Puder, Ph. D., Jens Hain Abstract: This paper describes a new, optimized directional processing
Effects of Cochlear Hearing Loss on the Benefits of Ideal Binary Masking
 INTERSPEECH 2016 September 8 12, 2016, San Francisco, USA Effects of Cochlear Hearing Loss on the Benefits of Ideal Binary Masking Vahid Montazeri, Shaikat Hossain, Peter F. Assmann University of Texas
INTERSPEECH 2016 September 8 12, 2016, San Francisco, USA Effects of Cochlear Hearing Loss on the Benefits of Ideal Binary Masking Vahid Montazeri, Shaikat Hossain, Peter F. Assmann University of Texas
MRI Image Processing Operations for Brain Tumor Detection
 MRI Image Processing Operations for Brain Tumor Detection Prof. M.M. Bulhe 1, Shubhashini Pathak 2, Karan Parekh 3, Abhishek Jha 4 1Assistant Professor, Dept. of Electronics and Telecommunications Engineering,
MRI Image Processing Operations for Brain Tumor Detection Prof. M.M. Bulhe 1, Shubhashini Pathak 2, Karan Parekh 3, Abhishek Jha 4 1Assistant Professor, Dept. of Electronics and Telecommunications Engineering,
Frequency Tracking: LMS and RLS Applied to Speech Formant Estimation
 Aldebaro Klautau - http://speech.ucsd.edu/aldebaro - 2/3/. Page. Frequency Tracking: LMS and RLS Applied to Speech Formant Estimation ) Introduction Several speech processing algorithms assume the signal
Aldebaro Klautau - http://speech.ucsd.edu/aldebaro - 2/3/. Page. Frequency Tracking: LMS and RLS Applied to Speech Formant Estimation ) Introduction Several speech processing algorithms assume the signal
Speech Compression for Noise-Corrupted Thai Dialects
 American Journal of Applied Sciences 9 (3): 278-282, 2012 ISSN 1546-9239 2012 Science Publications Speech Compression for Noise-Corrupted Thai Dialects Suphattharachai Chomphan Department of Electrical
American Journal of Applied Sciences 9 (3): 278-282, 2012 ISSN 1546-9239 2012 Science Publications Speech Compression for Noise-Corrupted Thai Dialects Suphattharachai Chomphan Department of Electrical
Brain Tumor Segmentation of Noisy MRI Images using Anisotropic Diffusion Filter
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 7, July 2014, pg.744
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 7, July 2014, pg.744
Cancer Cells Detection using OTSU Threshold Algorithm
 Cancer Cells Detection using OTSU Threshold Algorithm Nalluri Sunny 1 Velagapudi Ramakrishna Siddhartha Engineering College Mithinti Srikanth 2 Velagapudi Ramakrishna Siddhartha Engineering College Kodali
Cancer Cells Detection using OTSU Threshold Algorithm Nalluri Sunny 1 Velagapudi Ramakrishna Siddhartha Engineering College Mithinti Srikanth 2 Velagapudi Ramakrishna Siddhartha Engineering College Kodali
Threshold Based Segmentation Technique for Mass Detection in Mammography
 Threshold Based Segmentation Technique for Mass Detection in Mammography Aziz Makandar *, Bhagirathi Halalli Department of Computer Science, Karnataka State Women s University, Vijayapura, Karnataka, India.
Threshold Based Segmentation Technique for Mass Detection in Mammography Aziz Makandar *, Bhagirathi Halalli Department of Computer Science, Karnataka State Women s University, Vijayapura, Karnataka, India.
Extraction of Blood Vessels and Recognition of Bifurcation Points in Retinal Fundus Image
 International Journal of Research Studies in Science, Engineering and Technology Volume 1, Issue 5, August 2014, PP 1-7 ISSN 2349-4751 (Print) & ISSN 2349-476X (Online) Extraction of Blood Vessels and
International Journal of Research Studies in Science, Engineering and Technology Volume 1, Issue 5, August 2014, PP 1-7 ISSN 2349-4751 (Print) & ISSN 2349-476X (Online) Extraction of Blood Vessels and
Identification of Sickle Cells using Digital Image Processing. Academic Year Annexure I
 Academic Year 2014-15 Annexure I 1. Project Title: Identification of Sickle Cells using Digital Image Processing TABLE OF CONTENTS 1.1 Abstract 1-1 1.2 Motivation 1-1 1.3 Objective 2-2 2.1 Block Diagram
Academic Year 2014-15 Annexure I 1. Project Title: Identification of Sickle Cells using Digital Image Processing TABLE OF CONTENTS 1.1 Abstract 1-1 1.2 Motivation 1-1 1.3 Objective 2-2 2.1 Block Diagram
Fig. 1 High level block diagram of the binary mask algorithm.[1]
![Fig. 1 High level block diagram of the binary mask algorithm.[1]](/thumbs/83/88394195.jpg "Fig. 1 High level block diagram of the binary mask algorithm.[1]") Implementation of Binary Mask Algorithm for Noise Reduction in Traffic Environment Ms. Ankita A. Kotecha 1, Prof. Y.A.Sadawarte 2 1 M-Tech Scholar, Department of Electronics Engineering, B. D. College
Implementation of Binary Mask Algorithm for Noise Reduction in Traffic Environment Ms. Ankita A. Kotecha 1, Prof. Y.A.Sadawarte 2 1 M-Tech Scholar, Department of Electronics Engineering, B. D. College
UvA-DARE (Digital Academic Repository) Perceptual evaluation of noise reduction in hearing aids Brons, I. Link to publication
 Perceptual evaluation of noise reduction in hearing aids Brons, I. Link to publication") UvA-DARE (Digital Academic Repository) Perceptual evaluation of noise reduction in hearing aids Brons, I. Link to publication Citation for published version (APA): Brons, I. (2013). Perceptual evaluation
UvA-DARE (Digital Academic Repository) Perceptual evaluation of noise reduction in hearing aids Brons, I. Link to publication Citation for published version (APA): Brons, I. (2013). Perceptual evaluation
ADVANCES in NATURAL and APPLIED SCIENCES
 ADVANCES in NATURAL and APPLIED SCIENCES ISSN: 1995-0772 Published BY AENSI Publication EISSN: 1998-1090 http://www.aensiweb.com/anas 2016 Special 10(14): pages 242-248 Open Access Journal Comparison ofthe
ADVANCES in NATURAL and APPLIED SCIENCES ISSN: 1995-0772 Published BY AENSI Publication EISSN: 1998-1090 http://www.aensiweb.com/anas 2016 Special 10(14): pages 242-248 Open Access Journal Comparison ofthe
Extraction of Unwanted Noise in Electrocardiogram (ECG) Signals Using Discrete Wavelet Transformation
 Signals Using Discrete Wavelet Transformation") Extraction of Unwanted Noise in Electrocardiogram (ECG) Signals Using Discrete Wavelet Transformation Er. Manpreet Kaur 1, Er. Gagandeep Kaur 2 M.Tech (CSE), RIMT Institute of Engineering & Technology,
Extraction of Unwanted Noise in Electrocardiogram (ECG) Signals Using Discrete Wavelet Transformation Er. Manpreet Kaur 1, Er. Gagandeep Kaur 2 M.Tech (CSE), RIMT Institute of Engineering & Technology,
Novel Speech Signal Enhancement Techniques for Tamil Speech Recognition using RLS Adaptive Filtering and Dual Tree Complex Wavelet Transform
 Web Site: wwwijettcsorg Email: editor@ijettcsorg Novel Speech Signal Enhancement Techniques for Tamil Speech Recognition using RLS Adaptive Filtering and Dual Tree Complex Wavelet Transform VimalaC 1,
Web Site: wwwijettcsorg Email: editor@ijettcsorg Novel Speech Signal Enhancement Techniques for Tamil Speech Recognition using RLS Adaptive Filtering and Dual Tree Complex Wavelet Transform VimalaC 1,
Application of Tree Structures of Fuzzy Classifier to Diabetes Disease Diagnosis
 , pp.143-147 http://dx.doi.org/10.14257/astl.2017.143.30 Application of Tree Structures of Fuzzy Classifier to Diabetes Disease Diagnosis Chang-Wook Han Department of Electrical Engineering, Dong-Eui University,
, pp.143-147 http://dx.doi.org/10.14257/astl.2017.143.30 Application of Tree Structures of Fuzzy Classifier to Diabetes Disease Diagnosis Chang-Wook Han Department of Electrical Engineering, Dong-Eui University,
The SRI System for the NIST OpenSAD 2015 Speech Activity Detection Evaluation
 INTERSPEECH 2016 September 8 12, 2016, San Francisco, USA The SRI System for the NIST OpenSAD 2015 Speech Activity Detection Evaluation Martin Graciarena 1, Luciana Ferrer 2, Vikramjit Mitra 1 1 SRI International,
INTERSPEECH 2016 September 8 12, 2016, San Francisco, USA The SRI System for the NIST OpenSAD 2015 Speech Activity Detection Evaluation Martin Graciarena 1, Luciana Ferrer 2, Vikramjit Mitra 1 1 SRI International,
Computational Auditory Scene Analysis: An overview and some observations. CASA survey. Other approaches
 CASA talk - Haskins/NUWC - Dan Ellis 1997oct24/5-1 The importance of auditory illusions for artificial listeners 1 Dan Ellis International Computer Science Institute, Berkeley CA
CASA talk - Haskins/NUWC - Dan Ellis 1997oct24/5-1 The importance of auditory illusions for artificial listeners 1 Dan Ellis International Computer Science Institute, Berkeley CA
GENERALIZATION OF SUPERVISED LEARNING FOR BINARY MASK ESTIMATION
 GENERALIZATION OF SUPERVISED LEARNING FOR BINARY MASK ESTIMATION Tobias May Technical University of Denmark Centre for Applied Hearing Research DK - 2800 Kgs. Lyngby, Denmark tobmay@elektro.dtu.dk Timo
GENERALIZATION OF SUPERVISED LEARNING FOR BINARY MASK ESTIMATION Tobias May Technical University of Denmark Centre for Applied Hearing Research DK - 2800 Kgs. Lyngby, Denmark tobmay@elektro.dtu.dk Timo
An Auditory System Modeling in Sound Source Localization
 An Auditory System Modeling in Sound Source Localization Yul Young Park The University of Texas at Austin EE381K Multidimensional Signal Processing May 18, 2005 Abstract Sound localization of the auditory
An Auditory System Modeling in Sound Source Localization Yul Young Park The University of Texas at Austin EE381K Multidimensional Signal Processing May 18, 2005 Abstract Sound localization of the auditory
Neural Network based Heart Arrhythmia Detection and Classification from ECG Signal
 Neural Network based Heart Arrhythmia Detection and Classification from ECG Signal 1 M. S. Aware, 2 V. V. Shete *Dept. of Electronics and Telecommunication, *MIT College Of Engineering, Pune Email: 1 mrunal_swapnil@yahoo.com,
Neural Network based Heart Arrhythmia Detection and Classification from ECG Signal 1 M. S. Aware, 2 V. V. Shete *Dept. of Electronics and Telecommunication, *MIT College Of Engineering, Pune Email: 1 mrunal_swapnil@yahoo.com,
Performance of Gaussian Mixture Models as a Classifier for Pathological Voice
 PAGE 65 Performance of Gaussian Mixture Models as a Classifier for Pathological Voice Jianglin Wang, Cheolwoo Jo SASPL, School of Mechatronics Changwon ational University Changwon, Gyeongnam 64-773, Republic
PAGE 65 Performance of Gaussian Mixture Models as a Classifier for Pathological Voice Jianglin Wang, Cheolwoo Jo SASPL, School of Mechatronics Changwon ational University Changwon, Gyeongnam 64-773, Republic
Chapter 4. MATLAB Implementation and Performance Evaluation of Transform Domain Methods
 MATLAB Implementation and Performance Evaluation of Transform Domain Methods 73 The simulation work is carried out to understand the functionality and behavior of all transform domain methods explained
MATLAB Implementation and Performance Evaluation of Transform Domain Methods 73 The simulation work is carried out to understand the functionality and behavior of all transform domain methods explained
Gray Scale Image Edge Detection and Reconstruction Using Stationary Wavelet Transform In High Density Noise Values
 Gray Scale Image Edge Detection and Reconstruction Using Stationary Wavelet Transform In High Density Noise Values N.Naveen Kumar 1, J.Kishore Kumar 2, A.Mallikarjuna 3, S.Ramakrishna 4 123 Research Scholar,
Gray Scale Image Edge Detection and Reconstruction Using Stationary Wavelet Transform In High Density Noise Values N.Naveen Kumar 1, J.Kishore Kumar 2, A.Mallikarjuna 3, S.Ramakrishna 4 123 Research Scholar,
Mammogram Analysis: Tumor Classification
 Mammogram Analysis: Tumor Classification Term Project Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is the
Mammogram Analysis: Tumor Classification Term Project Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is the
TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING
 134 TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING H.F.S.M.Fonseka 1, J.T.Jonathan 2, P.Sabeshan 3 and M.B.Dissanayaka 4 1 Department of Electrical And Electronic Engineering, Faculty
134 TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING H.F.S.M.Fonseka 1, J.T.Jonathan 2, P.Sabeshan 3 and M.B.Dissanayaka 4 1 Department of Electrical And Electronic Engineering, Faculty
Hearing Lectures. Acoustics of Speech and Hearing. Auditory Lighthouse. Facts about Timbre. Analysis of Complex Sounds
 Hearing Lectures Acoustics of Speech and Hearing Week 2-10 Hearing 3: Auditory Filtering 1. Loudness of sinusoids mainly (see Web tutorial for more) 2. Pitch of sinusoids mainly (see Web tutorial for more)
Hearing Lectures Acoustics of Speech and Hearing Week 2-10 Hearing 3: Auditory Filtering 1. Loudness of sinusoids mainly (see Web tutorial for more) 2. Pitch of sinusoids mainly (see Web tutorial for more)
Perceptual Effects of Nasal Cue Modification
 Send Orders for Reprints to reprints@benthamscience.ae The Open Electrical & Electronic Engineering Journal, 2015, 9, 399-407 399 Perceptual Effects of Nasal Cue Modification Open Access Fan Bai 1,2,*
Send Orders for Reprints to reprints@benthamscience.ae The Open Electrical & Electronic Engineering Journal, 2015, 9, 399-407 399 Perceptual Effects of Nasal Cue Modification Open Access Fan Bai 1,2,*
COMPUTERIZED SYSTEM DESIGN FOR THE DETECTION AND DIAGNOSIS OF LUNG NODULES IN CT IMAGES 1
 ISSN 258-8739 3 st August 28, Volume 3, Issue 2, JSEIS, CAOMEI Copyright 26-28 COMPUTERIZED SYSTEM DESIGN FOR THE DETECTION AND DIAGNOSIS OF LUNG NODULES IN CT IMAGES ALI ABDRHMAN UKASHA, 2 EMHMED SAAID
ISSN 258-8739 3 st August 28, Volume 3, Issue 2, JSEIS, CAOMEI Copyright 26-28 COMPUTERIZED SYSTEM DESIGN FOR THE DETECTION AND DIAGNOSIS OF LUNG NODULES IN CT IMAGES ALI ABDRHMAN UKASHA, 2 EMHMED SAAID
International Journal of Computational Science, Mathematics and Engineering Volume2, Issue6, June 2015 ISSN(online): Copyright-IJCSME
: Copyright-IJCSME") Various Edge Detection Methods In Image Processing Using Matlab K. Narayana Reddy 1, G. Nagalakshmi 2 12 Department of Computer Science and Engineering 1 M.Tech Student, SISTK, Puttur 2 HOD of CSE Department,
Various Edge Detection Methods In Image Processing Using Matlab K. Narayana Reddy 1, G. Nagalakshmi 2 12 Department of Computer Science and Engineering 1 M.Tech Student, SISTK, Puttur 2 HOD of CSE Department,
Binaural processing of complex stimuli
 Binaural processing of complex stimuli Outline for today Binaural detection experiments and models Speech as an important waveform Experiments on understanding speech in complex environments (Cocktail
Binaural processing of complex stimuli Outline for today Binaural detection experiments and models Speech as an important waveform Experiments on understanding speech in complex environments (Cocktail
Near-End Perception Enhancement using Dominant Frequency Extraction
 Near-End Perception Enhancement using Dominant Frequency Extraction Premananda B.S. 1,Manoj 2, Uma B.V. 3 1 Department of Telecommunication, R. V. College of Engineering, premanandabs@gmail.com 2 Department
Near-End Perception Enhancement using Dominant Frequency Extraction Premananda B.S. 1,Manoj 2, Uma B.V. 3 1 Department of Telecommunication, R. V. College of Engineering, premanandabs@gmail.com 2 Department
An active unpleasantness control system for indoor noise based on auditory masking
 An active unpleasantness control system for indoor noise based on auditory masking Daisuke Ikefuji, Masato Nakayama, Takanabu Nishiura and Yoich Yamashita Graduate School of Information Science and Engineering,
An active unpleasantness control system for indoor noise based on auditory masking Daisuke Ikefuji, Masato Nakayama, Takanabu Nishiura and Yoich Yamashita Graduate School of Information Science and Engineering,
MULTI-MODAL FETAL ECG EXTRACTION USING MULTI-KERNEL GAUSSIAN PROCESSES. Bharathi Surisetti and Richard M. Dansereau
 MULTI-MODAL FETAL ECG EXTRACTION USING MULTI-KERNEL GAUSSIAN PROCESSES Bharathi Surisetti and Richard M. Dansereau Carleton University, Department of Systems and Computer Engineering 25 Colonel By Dr.,
MULTI-MODAL FETAL ECG EXTRACTION USING MULTI-KERNEL GAUSSIAN PROCESSES Bharathi Surisetti and Richard M. Dansereau Carleton University, Department of Systems and Computer Engineering 25 Colonel By Dr.,
Mammogram Analysis: Tumor Classification
 Mammogram Analysis: Tumor Classification Literature Survey Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is
Mammogram Analysis: Tumor Classification Literature Survey Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is
FIR filter bank design for Audiogram Matching
 FIR filter bank design for Audiogram Matching Shobhit Kumar Nema, Mr. Amit Pathak,Professor M.Tech, Digital communication,srist,jabalpur,india, shobhit.nema@gmail.com Dept.of Electronics & communication,srist,jabalpur,india,
FIR filter bank design for Audiogram Matching Shobhit Kumar Nema, Mr. Amit Pathak,Professor M.Tech, Digital communication,srist,jabalpur,india, shobhit.nema@gmail.com Dept.of Electronics & communication,srist,jabalpur,india,
Edge Detection Techniques Based On Soft Computing
 International Journal for Science and Emerging ISSN No. (Online):2250-3641 Technologies with Latest Trends 7(1): 21-25 (2013) ISSN No. (Print): 2277-8136 Edge Detection Techniques Based On Soft Computing
International Journal for Science and Emerging ISSN No. (Online):2250-3641 Technologies with Latest Trends 7(1): 21-25 (2013) ISSN No. (Print): 2277-8136 Edge Detection Techniques Based On Soft Computing
Categorical Perception
 Categorical Perception Discrimination for some speech contrasts is poor within phonetic categories and good between categories. Unusual, not found for most perceptual contrasts. Influenced by task, expectations,
Categorical Perception Discrimination for some speech contrasts is poor within phonetic categories and good between categories. Unusual, not found for most perceptual contrasts. Influenced by task, expectations,
Speech quality evaluation of a sparse coding shrinkage noise reduction algorithm with normal hearing and hearing impaired listeners
 Accepted Manuscript Speech quality evaluation of a sparse coding shrinkage noise reduction algorithm with normal hearing and hearing impaired listeners Jinqiu Sang, Hongmei Hu, Chengshi Zheng, Guoping
Accepted Manuscript Speech quality evaluation of a sparse coding shrinkage noise reduction algorithm with normal hearing and hearing impaired listeners Jinqiu Sang, Hongmei Hu, Chengshi Zheng, Guoping
Fuzzy Based Early Detection of Myocardial Ischemia Using Wavelets
 Fuzzy Based Early Detection of Myocardial Ischemia Using Wavelets Jyoti Arya 1, Bhumika Gupta 2 P.G. Student, Department of Computer Science, GB Pant Engineering College, Ghurdauri, Pauri, India 1 Assistant
Fuzzy Based Early Detection of Myocardial Ischemia Using Wavelets Jyoti Arya 1, Bhumika Gupta 2 P.G. Student, Department of Computer Science, GB Pant Engineering College, Ghurdauri, Pauri, India 1 Assistant
I. INTRODUCTION. OMBARD EFFECT (LE), named after the French otorhino-laryngologist
, named after the French otorhino-laryngologist") IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 18, NO. 6, AUGUST 2010 1379 Unsupervised Equalization of Lombard Effect for Speech Recognition in Noisy Adverse Environments Hynek Bořil,
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 18, NO. 6, AUGUST 2010 1379 Unsupervised Equalization of Lombard Effect for Speech Recognition in Noisy Adverse Environments Hynek Bořil,
Research Article The Acoustic and Peceptual Effects of Series and Parallel Processing
 Hindawi Publishing Corporation EURASIP Journal on Advances in Signal Processing Volume 9, Article ID 6195, pages doi:1.1155/9/6195 Research Article The Acoustic and Peceptual Effects of Series and Parallel
Hindawi Publishing Corporation EURASIP Journal on Advances in Signal Processing Volume 9, Article ID 6195, pages doi:1.1155/9/6195 Research Article The Acoustic and Peceptual Effects of Series and Parallel
Assessment of Reliability of Hamilton-Tompkins Algorithm to ECG Parameter Detection
 Proceedings of the 2012 International Conference on Industrial Engineering and Operations Management Istanbul, Turkey, July 3 6, 2012 Assessment of Reliability of Hamilton-Tompkins Algorithm to ECG Parameter
Proceedings of the 2012 International Conference on Industrial Engineering and Operations Management Istanbul, Turkey, July 3 6, 2012 Assessment of Reliability of Hamilton-Tompkins Algorithm to ECG Parameter
Comparative Analysis of Vocal Characteristics in Speakers with Depression and High-Risk Suicide
 International Journal of Computer Theory and Engineering, Vol. 7, No. 6, December 205 Comparative Analysis of Vocal Characteristics in Speakers with Depression and High-Risk Suicide Thaweewong Akkaralaertsest
International Journal of Computer Theory and Engineering, Vol. 7, No. 6, December 205 Comparative Analysis of Vocal Characteristics in Speakers with Depression and High-Risk Suicide Thaweewong Akkaralaertsest
! Can hear whistle? ! Where are we on course map? ! What we did in lab last week. ! Psychoacoustics
 2/14/18 Can hear whistle? Lecture 5 Psychoacoustics Based on slides 2009--2018 DeHon, Koditschek Additional Material 2014 Farmer 1 2 There are sounds we cannot hear Depends on frequency Where are we on
2/14/18 Can hear whistle? Lecture 5 Psychoacoustics Based on slides 2009--2018 DeHon, Koditschek Additional Material 2014 Farmer 1 2 There are sounds we cannot hear Depends on frequency Where are we on
Speech recognition in noisy environments: A survey
 T-61.182 Robustness in Language and Speech Processing Speech recognition in noisy environments: A survey Yifan Gong presented by Tapani Raiko Feb 20, 2003 About the Paper Article published in Speech Communication
T-61.182 Robustness in Language and Speech Processing Speech recognition in noisy environments: A survey Yifan Gong presented by Tapani Raiko Feb 20, 2003 About the Paper Article published in Speech Communication
Robust Speech Detection for Noisy Environments
 Robust Speech Detection for Noisy Environments Óscar Varela, Rubén San-Segundo and Luis A. Hernández ABSTRACT This paper presents a robust voice activity detector (VAD) based on hidden Markov models (HMM)
Robust Speech Detection for Noisy Environments Óscar Varela, Rubén San-Segundo and Luis A. Hernández ABSTRACT This paper presents a robust voice activity detector (VAD) based on hidden Markov models (HMM)
BINAURAL DICHOTIC PRESENTATION FOR MODERATE BILATERAL SENSORINEURAL HEARING-IMPAIRED
 International Conference on Systemics, Cybernetics and Informatics, February 12 15, 2004 BINAURAL DICHOTIC PRESENTATION FOR MODERATE BILATERAL SENSORINEURAL HEARING-IMPAIRED Alice N. Cheeran Biomedical
International Conference on Systemics, Cybernetics and Informatics, February 12 15, 2004 BINAURAL DICHOTIC PRESENTATION FOR MODERATE BILATERAL SENSORINEURAL HEARING-IMPAIRED Alice N. Cheeran Biomedical
Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention
 Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention Tapani Raiko and Harri Valpola School of Science and Technology Aalto University (formerly Helsinki University of
Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention Tapani Raiko and Harri Valpola School of Science and Technology Aalto University (formerly Helsinki University of
THE data used in this project is provided. SEIZURE forecasting systems hold promise. Seizure Prediction from Intracranial EEG Recordings
 1 Seizure Prediction from Intracranial EEG Recordings Alex Fu, Spencer Gibbs, and Yuqi Liu 1 INTRODUCTION SEIZURE forecasting systems hold promise for improving the quality of life for patients with epilepsy.
1 Seizure Prediction from Intracranial EEG Recordings Alex Fu, Spencer Gibbs, and Yuqi Liu 1 INTRODUCTION SEIZURE forecasting systems hold promise for improving the quality of life for patients with epilepsy.
Measurement Denoising Using Kernel Adaptive Filters in the Smart Grid
 Measurement Denoising Using Kernel Adaptive Filters in the Smart Grid Presenter: Zhe Chen, Ph.D. Associate Professor, Associate Director Institute of Cyber-Physical Systems Engineering Northeastern University
Measurement Denoising Using Kernel Adaptive Filters in the Smart Grid Presenter: Zhe Chen, Ph.D. Associate Professor, Associate Director Institute of Cyber-Physical Systems Engineering Northeastern University
Using the Soundtrack to Classify Videos
 Using the Soundtrack to Classify Videos Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Using the Soundtrack to Classify Videos Dan Ellis Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA dpwe@ee.columbia.edu http://labrosa.ee.columbia.edu/
Lung Detection and Segmentation Using Marker Watershed and Laplacian Filtering
 International Journal of Biomedical Engineering and Clinical Science 2015; 1(2): 29-42 Published online October 20, 2015 (http://www.sciencepublishinggroup.com/j/ijbecs) doi: 10.11648/j.ijbecs.20150102.12
International Journal of Biomedical Engineering and Clinical Science 2015; 1(2): 29-42 Published online October 20, 2015 (http://www.sciencepublishinggroup.com/j/ijbecs) doi: 10.11648/j.ijbecs.20150102.12
Segmentation of Color Fundus Images of the Human Retina: Detection of the Optic Disc and the Vascular Tree Using Morphological Techniques
 Segmentation of Color Fundus Images of the Human Retina: Detection of the Optic Disc and the Vascular Tree Using Morphological Techniques Thomas Walter and Jean-Claude Klein Centre de Morphologie Mathématique,
Segmentation of Color Fundus Images of the Human Retina: Detection of the Optic Disc and the Vascular Tree Using Morphological Techniques Thomas Walter and Jean-Claude Klein Centre de Morphologie Mathématique,
Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility
 Downloaded from orbit.dtu.dk on: Sep 28, 208 Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility Kressner, Abigail Anne; May, Tobias; Malik Thaarup
Downloaded from orbit.dtu.dk on: Sep 28, 208 Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility Kressner, Abigail Anne; May, Tobias; Malik Thaarup
Analogization of Algorithms for Effective Extraction of Blood Vessels in Retinal Images
 Analogization of Algorithms for Effective Extraction of Blood Vessels in Retinal Images P.Latha Research Scholar, Department of Computer Science, Presidency College (Autonomous), Chennai-05, India. Abstract
Analogization of Algorithms for Effective Extraction of Blood Vessels in Retinal Images P.Latha Research Scholar, Department of Computer Science, Presidency College (Autonomous), Chennai-05, India. Abstract
International Journal of Innovative Research in Advanced Engineering (IJIRAE) Volume 1 Issue 10 (November 2014)
 Volume 1 Issue 10 (November 2014)") Technique for Suppression Random and Physiological Noise Components in Functional Magnetic Resonance Imaging Data Mawia Ahmed Hassan* Biomedical Engineering Department, Sudan University of Science & Technology,
Technique for Suppression Random and Physiological Noise Components in Functional Magnetic Resonance Imaging Data Mawia Ahmed Hassan* Biomedical Engineering Department, Sudan University of Science & Technology,
Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility
 Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility ABIGAIL ANNE KRESSNER,TOBIAS MAY, RASMUS MALIK THAARUP HØEGH, KRISTINE AAVILD JUHL, THOMAS BENTSEN,
Investigating the effects of noise-estimation errors in simulated cochlear implant speech intelligibility ABIGAIL ANNE KRESSNER,TOBIAS MAY, RASMUS MALIK THAARUP HØEGH, KRISTINE AAVILD JUHL, THOMAS BENTSEN,
Improving the Noise-Robustness of Mel-Frequency Cepstral Coefficients for Speech Processing
 ISCA Archive http://www.isca-speech.org/archive ITRW on Statistical and Perceptual Audio Processing Pittsburgh, PA, USA September 16, 2006 Improving the Noise-Robustness of Mel-Frequency Cepstral Coefficients
ISCA Archive http://www.isca-speech.org/archive ITRW on Statistical and Perceptual Audio Processing Pittsburgh, PA, USA September 16, 2006 Improving the Noise-Robustness of Mel-Frequency Cepstral Coefficients
Perceptual Evaluation of Signal Enhancement Strategies
 Perceptual Evaluation of Signal Enhancement Strategies Koen Eneman, Heleen Luts, Jan Wouters, Michael Büchler, Norbert Dillier, Wouter Dreschler, Matthias Froehlich, Giso Grimm, Niklas Harlander, Volker
Perceptual Evaluation of Signal Enhancement Strategies Koen Eneman, Heleen Luts, Jan Wouters, Michael Büchler, Norbert Dillier, Wouter Dreschler, Matthias Froehlich, Giso Grimm, Niklas Harlander, Volker
Twenty subjects (11 females) participated in this study. None of the subjects had
 participated in this study. None of the subjects had") SUPPLEMENTARY METHODS Subjects Twenty subjects (11 females) participated in this study. None of the subjects had previous exposure to a tone language. Subjects were divided into two groups based on musical
SUPPLEMENTARY METHODS Subjects Twenty subjects (11 females) participated in this study. None of the subjects had previous exposure to a tone language. Subjects were divided into two groups based on musical
Improved Intelligent Classification Technique Based On Support Vector Machines
 Improved Intelligent Classification Technique Based On Support Vector Machines V.Vani Asst.Professor,Department of Computer Science,JJ College of Arts and Science,Pudukkottai. Abstract:An abnormal growth
Improved Intelligent Classification Technique Based On Support Vector Machines V.Vani Asst.Professor,Department of Computer Science,JJ College of Arts and Science,Pudukkottai. Abstract:An abnormal growth
Using Speech Models for Separation
 Using Speech Models for Separation Dan Ellis Comprising the work of Michael Mandel and Ron Weiss Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY
Using Speech Models for Separation Dan Ellis Comprising the work of Michael Mandel and Ron Weiss Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY
Acoustic Sensing With Artificial Intelligence
 Acoustic Sensing With Artificial Intelligence Bowon Lee Department of Electronic Engineering Inha University Incheon, South Korea bowon.lee@inha.ac.kr bowon.lee@ieee.org NVIDIA Deep Learning Day Seoul,
Acoustic Sensing With Artificial Intelligence Bowon Lee Department of Electronic Engineering Inha University Incheon, South Korea bowon.lee@inha.ac.kr bowon.lee@ieee.org NVIDIA Deep Learning Day Seoul,