Prefrontal cortex and decision making in a mixedstrategy
|
|
|
- Gertrude Glenn
- 6 years ago
- Views:
Transcription
1 Prefrontal cortex and decision making in a mixedstrategy game Dominic J Barraclough, Michelle L Conroy & Daeyeol Lee In a multi-agent environment, where the outcomes of one s actions change dynamically because they are related to the behavior of other beings, it becomes difficult to make an optimal decision about how to act. Although game theory provides normative solutions for decision making in groups, how such decision-making strategies are altered by experience is poorly understood. These adaptive processes might resemble reinforcement learning algorithms, which provide a general framework for finding optimal strategies in a dynamic environment. Here we investigated the role of prefrontal cortex (PFC) in dynamic decision making in monkeys. As in reinforcement learning, the animal s choice during a competitive game was biased by its choice and reward history, as well as by the strategies of its opponent. Furthermore, neurons in the dorsolateral prefrontal cortex (DLPFC) encoded the animal s past decisions and payoffs, as well as the conjunction between the two, providing signals necessary to update the estimates of expected reward. Thus, PFC might have a key role in optimizing decision-making strategies. Decision making refers to an evaluative process of selecting a particular action from a set of alternatives. When the mapping between a particular action and its outcome or utility is fixed, the decision to select the action with maximum utility can be considered optimal or rational. However, animals face more difficult problems in a multiagent environment, in which the outcome of one s decision can be influenced by the decisions of other animals. Game theory provides a mathematical framework to analyze decision making in a group of agents 1 4.A game is defined by a set of actions available to each player, and a payoff matrix that specifies the reward or penalty for each player as a function of decisions made by all players. A solution or equilibrium in game theory refers to a set of strategies selected by a group of rational players 1,5,6.Nash has proved that any n-player competitive game has at least one equilibrium in which no players can benefit by changing their strategies individually 5.These equilibrium strategies often take the form of a mixed strategy, which is defined as a probability density function over the alternative actions available to each player. This requires players to choose randomly among alternative choices, as in the game of rock-paper-scissors during which choosing one of the alternatives (e.g., paper) exclusively allows the opponent to exploit such a biased choice (with scissors). Many studies have shown that people frequently deviate from the predictions of game theory 7 21.Although the magnitudes of such deviations are often small, they have important implications regarding the validity of assumptions in game theory, such as the rationality of human decision-makers In addition, strategies of human decision-makers change with their experience These adaptive processes might be based on reinforcement learning algorithms 28, which can be used to approximate optimal decision-making strategies in a dynamic environment. In the present study, we analyzed the performance of monkeys playing a zero-sum game against a computer opponent to determine how closely their behaviors match the predictions of game theory and whether reinforcement learning algorithms can account for any deviations from such predictions. In addition, neural activity was recorded from the DLPFC to investigate its role during strategic decision making in a multi-agent environment. The results showed that the animal s choice behavior during a competitive game could be accounted for by a reinforcement learning algorithm. Individual prefrontal neurons often modulated their activity according to the choice of the animal in the previous trial, the outcome of that choice, and the conjunction between the choice and its outcome. This suggests that the PFC may be involved in updating the animal s decision-making strategy based on a reinforcement learning algorithm. RESULTS Behavioral performance Two rhesus monkeys played a game analogous to matching pennies against a computer in an oculomotor free-choice task (Fig. 1a; Methods). The animal was rewarded when it selected the same target as the computer that was programmed to minimize the animal s reward by exploiting the statistical bias in the animal s choice behavior. Accordingly, the optimal strategy for the animal was to choose the targets randomly with equal probabilities, which corresponds to the Nash equilibrium in the matching pennies game. To determine how the animal s decisions were influenced by the strategy of the opponent, we manipulated the amount of information that was used by the computer opponent (see Methods). In algorithm 0, the computer selected its targets randomly with equal probabilities, regardless of the animal s choice patterns. In algorithm 1, the com- Department of Brain and Cognitive Sciences, Center for Visual Science, University of Rochester, Rochester, New York 14627, USA. Correspondence should be addressed to D.L. (dlee@cvs.rochester.edu). Published online 7 March 2004; doi: /nn VOLUME 7 NUMBER 4 APRIL 2004 NATURE NEUROSCIENCE

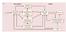
2 puter analyzed only the animal s choice history, but not its reward history. In algorithm 2, both choice and reward histories were analyzed. In both algorithms 1 and 2, the computer chose its target randomly if it did not find any systematic bias in the animal s choice behavior. Therefore, a reward rate near 0.5 indicates that the animal s performance was optimal. Indeed, the animal s reward rate was close to 0.5 for all algorithms, indicating that the animal s performance was nearly optimal. In algorithm 0, the reward rate was fixed at 0.5 regardless of the animal s behavior, and therefore there was no incentive for the animal to choose the targets with equal probabilities. In fact, both animals chose the right-hand target more frequently (P = 0.70 and 0.90 and n = 5,327 and 1,669 trials, for the two animals, respectively) than the Table 1 Parameters for the reinforcement learning model. Algorithm Monkey α C (0.130, 0.220) (0.619, 0.704) ( 0.597, 0.512) E (0.143, 0.198) (0.903, 0.979) ( 1.104, 1.024) 2 C (0.983, 0.988) (0.028, 0.039) (0.012, 0.021) E (0.801, 0.851) (0.171, 0.218) ( 0.169, 0.118) α, discount factor; 1 and 2, changes in the value function associated with rewarded and unrewarded targets selected by the animal, respectively. The numbers in parentheses indicate 99.9% confidence intervals. Figure 1 Task and behavioral performance. (a) Free-choice task and payoff matrix for the animal during the competitive game (1, reward; 0, no reward). (b) Recording sites in PFC. Frontal eye field (gray area in the inset) was defined by electrical stimulation 50. (c) Frequency histograms for the probability of choosing the right-hand target in algorithms 1 and 2. (d) Probability of the win-stay-lose-switch (WSLS) strategy (abscissa) versus probability of reward (ordinate). (e) Difference in the value functions for the two targets estimated from a reinforcement learning model (abscissa) versus the probability of choosing the target at the right (ordinate). Error bars indicate standard error of the mean (s.e.m.). Histograms show the frequency of trials versus the difference in the value functions. Solid line, prediction of the reinforcement learning model. In all panels, dark and light symbols indicate the results from the two animals, respectively. left-hand target. For the remaining two algorithms, the probability of choosing the righthand target was much closer to 0.5 (Fig. 1c), which corresponds to the Nash equilibrium of the matching pennies game. In addition, the probability of choosing a given target was relatively unaffected by the animal s choice in the previous trial. For example, the probability that the animal would select the same target as in the previous trial was also close to 0.5 (P = 0.51 ± 0.06 and 0.50 ± 0.04 and n = 120,254 and 74,113 trials, for algorithms 1 and 2, respectively). In contrast, the animal s choice was strongly influenced by the computer s choice in the previous trial, especially in algorithm 1. In the game of matching pennies, the strategy to choose the same target selected by the opponent in the previous trial can be referred to as a win-stay-lose-switch (WSLS) strategy, as this is equivalent to choosing the same target as in the previous trial if that choice was rewarded and choosing the opposite target otherwise. The probability of the WSLS strategy in algorithm 1 (0.73 ± 0.14) was significantly higher than that in algorithm 2 (0.53 ± 0.06; P < ; Fig. 1d). Although the tendency for the WSLS strategy in algorithm 2 was only slightly above chance, this bias was still statistically significant (P <10 5 ). Similarly, average mutual information between the sequence of animal s choice and reward in three successive trials and the animal s choice in the following trial decreased from (± 0.205) bits for algorithm 1 to (± 0.035) bits for algorithm 2. Reinforcement learning model Using a reinforcement learning model 19 21,28,29,we tested whether the animal s decision was systematically influenced by the cumulative effects of reward history. In this model, a decision was based on the difference between the value functions (that is, expected reward) for the two targets. Denoting the value functions of the two targets (L and R) at trial t as V t (L) and V t (R), the probability of choosing each target is given by the logit transformation of the difference between the value functions 30.In other words, logit P(R) log P(R)/(1 P(R)) = V t (R) V t (L). NATURE NEUROSCIENCE VOLUME 7 NUMBER 4 APRIL
3 The value function, V t (x), for target x, was updated after each trial according to the following: V t+1 (x) = αv t (x) + t (x), Figure 2 Effects of relative expected reward (i.e., difference in value functions) and its trial-to-trial changes on the activity of prefrontal neurons. (a) Percentage of neurons with significant correlation (t-test, P < 0.05) between their activity and the difference in the value functions for the two targets (VD = V τ (R) V τ (L)) estimated for the current (τ = t) and previous (τ = t 1) trials, or between the activity and the changes in the value functions between the two successive trials (VD change = t 1 (R) t 1 (L)). (b) Correlation coefficient between the VD change and the activity in a given neuron (ordinate), plotted against correlation coefficient between the VD in the previous trial (i.e., V t 1 (R) V t 1 (L)) and the activity of the same neuron (abscissa). Black (gray) symbols indicate the neurons in which both (either) correlation coefficients were significantly different from 0 (t-test, P < 0.05). The numbers in each panel correspond to Spearman s rank correlation coefficient (r) and its level of significance (P). where α is a discount factor, and t (x) denotes the change in the value function determined by the animal s decision and its outcome. In the current model, t (x) = 1 if the animal selects the target x and is rewarded, t (x) = 2 if the animal selects the target x and is not rewarded, and t (x) = 0 if the animal does not select the target x. We introduced a separate parameter for the unrewarded target ( 2 ) because the probability of choosing the same target after losing a reward was significantly different from the probability of switching to the other target for all animals and for both algorithms 1 and 2. Maximum likelihood estimates 31 of the model parameters (Table 1) showed that a frequent use of the WSLS strategy during algorithm 1 was reflected in a relatively small discount factor (α < 0.2), a large positive 1 (> 0.6) and a large negative 2 (< 0.5) in both animals. For algorithm 1, this led to a largely bimodal distribution for the difference in the value functions (Fig. 1e). In contrast, the magnitude of changes in value function during algorithm 2 was smaller, indicating that the outcome of previous choices only weakly influenced the subsequent choice of the animal. In addition, the discount factor for algorithm 2 was relatively large (α > 0.8). This suggests that the animal s choice was systematically influenced by the combined effects of previous reward history even in algorithm 2. The combination of model parameters for algorithm 2 produced an approximately normal distribution for the difference in value functions (Fig. 1e). This implies that for most trials, the difference in the value functions of the two targets was relatively small, making it difficult to predict the animal s choice reliably. These results suggest that during a competitive game, the monkeys might have approximated the optimal decision-making strategy using a reinforcement learning algorithm. Prefrontal activity during a competitive game The value functions in the above reinforcement learning model were updated according to the animal s decisions and the outcomes of those decisions. To determine whether such signals are encoded in the activity of individual neurons in PFC, we recorded single-neuron activity in the DLPFC while the animal played the same free-choice task. During the neurophysiological recording, the computer selected its target according to algorithm 2. A total of 132 neurons were examined during a minimum of 128 free-choice trials (mean = 583 trials; Fig. 1b). As a control, each neuron was also examined during 128 trials of a visual search task in Figure 3 Percentages of neurons encoding signals related to the animal s decision. White bars show the percentage of neurons (n = 132) with significant main and interaction effects in a three-way ANOVA (P R C). Light gray bars show the same information for the neurons with >256 free-choice trials, which was tested for stationarity in free-choice trials (n = 112). Dark gray bars show the percentage of neurons with significant effects in the three-way ANOVA that also varied with the task (search vs. choice) in a four-way ANOVA (Task P R C). This analysis was performed only for the neurons with >256 free-choice trials for comparison with the control analysis to test stationarity. Black histograms show the percentage of neurons with significant effects in the three-way ANOVA that also have significant non-stationarity in a control 4-way ANOVA across the two successive blocks of 128 free-choice trials. 406 VOLUME 7 NUMBER 4 APRIL 2004 NATURE NEUROSCIENCE

4 the previous trial exerted a significant influence on the activity before and during the fore-period, as well as during the delay period (3-way ANOVA, P < 0.001). In addition, activity during the movement period was still influenced by the animal s choice in the previous trial and its outcome, as well as by their interactions with the animal s choice in the current trial. To determine whether any of these effects could be attributed to systematic variability in eye movements, the above analysis was repeated using the residuals from a regression model in which the neural activity related to a set of eye movement parameters was factored out (Methods). The results were nearly identical, with the only difference found in the loss of significance for the effect of the current choice. During the fore-period, 35% of neurons showed a significant effect of the animal s choice in the previous trial on the residuals from the same regression model. It is possible that the animal s choice in the previous trial influenced the activity of this neuron during the next trial through systematic changes in unidentified sensorimotor events, such as licking or eye movements during the inter-trial interval, that were not experimentally controlled. This was tested by comparing the activity of the same neuron in the search and free-choice trials. For the neuron shown in Figure 4, activity during search trials was significantly affected by the position of the target in the previous trial only during the fore-period, and this effect was opposite to and significantly different from that found in the free-choice trials (4-way ANOVA, P < 10 5 ). The raster plots show that this change occurred within a few trials after the animal switched from search to free-choice trials (Fig. 4). These results suggest that the effect of the animal s choice in the previous trial on the activity of this neuron did not merely reflect nonspecific sensorimotor events. In 17% of the neurons that showed a significant effect of the animal s previous choice during the fore-period, there was also a significant interaction between the task type (search vs. free-choice) and the animal s choice in the previous trial (Fig. 3). This indicates that signals related to the animal s past choice were actively maintained in the PFC according to the type of decision. It is unlikely that this was entirely due to an ongoing drift in the background activity (i.e., non-stationarity), as the control analysis performed on two successive blocks of free-choice trials did not produce a single case with the same effect during the fore-period (Fig. 3). During the fore-period, 39% of neurons showed a significant effect of the reward in the previous trial. For example, the activity of the neuwhich the animal s decision was guided by sensory stimuli (Methods). During the free-choice trials, activity in some prefrontal neurons was influenced by the difference in the value functions for the two targets (that is, V(R) V(L)), although the effects in individual neurons were relatively small (Fig. 2). This was not entirely due to the animal s choice and its outcome in the previous trial, as the value functions estimated for the previous trial produced similar results (Fig. 2a). If individual PFC neurons are involved in the temporal integration of value functions according to the reinforcement learning model described above, differences in the value functions (i.e., V(x)) and their changes (i.e., (x)) would similarly influence the activity of PFC neurons. Interestingly, such patterns were found for the delay and movement periods, but not for the fore-period (Methods; Fig. 2b). These results suggest that some prefrontal neurons might be involved in temporally integrating the signals related to previous choice and its outcome to update value functions. To examine how the activity of individual PFC neurons is influenced by the animal s choices and their outcomes, we analyzed neural activity by three-way ANOVA with the animal s choice and reward in the previous trial and its choice in the current trial as main factors. For 39% of PFC neurons, the activity during the fore-period was influenced by the animal s choice in the previous trial (Fig. 3). For example, in the neuron illustrated in Figure 4, the animal s choice in Figure 4 Example neuron showing a significant effect of the animal s choice in the previous trial. Top, spike density functions averaged according to the animal s choice (L and R) and reward (+, reward;, no reward) in the previous trial and the choice in the current trial. A dotted vertical line indicates the onset of the fore-period, and the two solid lines the beginning and end of the delay period. Bottom, raster plots showing the activity of the same neuron sorted according to the same three factors during the search (gray background) and free-choice (white background) trials. NATURE NEUROSCIENCE VOLUME 7 NUMBER 4 APRIL
5 Figure 5 Example neuron showing a significant effect of the reward in the previous trial. Same format as in Figure 4. ron in Figure 5 was higher throughout the entire trial after the animal was not rewarded in the previous trial, compared to when the animal was rewarded. This effect was nearly unchanged when we removed the eye-movement related activity in a regression analysis, both in this single-neuron example and for the population as a whole. Overall, 37% of neurons showed the effect of the previous reward when the analysis was performed on the residuals from the regression model. The possibility that this effect was entirely due to uncontrolled sensorimotor events is also unlikely, as a substantial proportion of these neurons (21%) also showed a significant interaction between the task type and the previous reward during the fore-period (Fig. 3). To update the value functions in a reinforcement learning model, signals related to the animal s choice and its outcome must be combined, because each variable alone does not specify how the value function of a particular target should be changed. Similarly, activity of the neurons in the PFC was often influenced by the conjunction of these two variables. In the neuron in Figure 6, for example, there was a gradual buildup of activity during the fore-period, but this occurred only when the animal had selected the right-hand target in the previous trial, and this choice was not rewarded. During the delay period, the activity of this neuron diverged to reflect the animal s choice in the current trial (Fig. 6, arrow). The same neuron showed markedly weaker activity during the search trials, suggesting that information coded in the activity of this neuron regarding the outcome of choosing a particular target was actively maintained in free-choice trials (Fig. 6). For the fore-period, 20% of the neurons showed significant interaction between the animal s choice and its outcome in the previous trial (P < 0.05; Fig. 3). Activity related to eye movements was not an important factor: 90% of these neurons showed the same effect in the residuals from the regression analysis that factored out the effects of eye movements. Furthermore, during the fore-period, 27% of the same neurons showed significant threeway interactions among task type, animal s choice in the previous trial and outcome of the previous trial. In contrast, the control analysis during the first two blocks of the freechoice task revealed such an effect only in 5% of the neurons (Fig. 3). These results indicate that signals related to the conjunction of the animal s previous decision and its outcome are processed differently in the PFC according to the type of decisions made by the animal. DISCUSSION Interaction with other intelligent beings is fundamentally different from and more complex than dealing with inanimate objects 32,33.Interactions with other animals are complicated by the fact that their behavioral strategies often change as a result of one s own behavior. Therefore, the analysis Figure 6 Example neuron with a significant interaction between the animal s choice and its outcome in the previous trial. Same format as in Figure 4. Arrows indicate the time when the animal s choice in the current trial was first reflected in the neural activity. 408 VOLUME 7 NUMBER 4 APRIL 2004 NATURE NEUROSCIENCE
6 of decision making in a group requires a more sophisticated analytical framework, which is provided by game theory. Matching pennies is a relatively simple zero-sum game that involves two players and two alternative choices. The present study examined the behavior of monkeys playing a competitive game similar to matching pennies against a computer opponent. It is not known whether monkeys treated this game as a competitive situation with another intentional being. Nevertheless, the same formal framework of game theory is applicable to the task used in this study, and as predicted, the animal s behavior was influenced by the opponent s strategy. When the computer blindly played the equilibrium strategy regardless of the animal s behavior, the animals selected one of the targets more frequently. In contrast, when the computer opponent began exploiting biases in the animal s choice sequence, the animal s behavior approached the equilibrium strategy. Furthermore, when the computer did not examine the animal s reward history (algorithm 1), the animals achieved a nearly optimal reward rate by adopting the win-stay-lose-switch (WSLS) strategy. This was possible because this strategy was not detected by the computer. Finally, the frequency of the WSLS strategy was reduced when the computer began exploiting biases in the animal s choice and reward sequences (algorithm 2). These results also suggest that the animals approximated the optimal strategy using a reinforcement learning algorithm. This model assumes that the animals base their decisions, in part, on the estimates of expected rewards for the two targets and tend to select the target with larger expected reward. During zero-sum games such as matching pennies, strategies of the players behaving according to some reinforcement learning algorithms would gradually converge on a set of equilibrium strategies 5 7.However, it is important to update the value functions of different targets by a small amount after each play when playing against a fully informed rational player (such as algorithm 2 in the present study). This is because large, predictable changes in the value functions would reveal one s next choice to the opponent. In the present study, the magnitude of changes in the value function varied according to the strategy of the opponent and was adjusted through the animal s experience. Finally, neurophysiological recordings in the PFC revealed a potential neural basis for updating the value functions adaptively while interacting with a rational opponent. Reward-related activity is widespread in the brain In particular, signals related to expected reward (i.e.,value functions) are present in various brain areas 39 43, including the DLPFC Our results showed that neurons in the DLPFC also code signals related to the animal s choice in the previous trial. Such signals might be actively maintained and processed differently in the DLPFC according to the type of information required for the animal s upcoming decisions. Furthermore, signals related to the animal s past choices and their outcomes are combined at the level of individual PFC neurons. These signals might then be temporally integrated according to a reinforcement learning algorithm to update the value functions for alternative actions. Many neurons in the PFC show persistent activity during a working memory task, and the same circuitry might be ideally suited for temporal integration of signals related to the animal s previous choice and its outcome 49.Although the present study examined the animal s choice behavior in a competitive game, reinforcement learning algorithms can converge on optimal solutions for a wide range of decision-making problems in dynamic environments. Therefore, the results from the present study suggest that the PFC has an important role in optimizing decision-making strategies in a dynamic environment that may include multiple agents. METHODS Animal preparations. Two male rhesus monkeys were used. Their eye movements were monitored at a sampling rate of 250 Hz with either a scleral eye coil or a high-speed video-based eye tracker (ET49, Thomas Recording). All the procedures used in this study conformed to National Institutes of Health guidelines and were approved by the University of Rochester Committee on Animal Research. Behavioral task. Monkeys were trained to play a competitive game analogous to matching pennies against a computer in an oculomotor free-choice task (Fig. 1a). During a 0.5-s fore-period, they fixated a small yellow square ( ; CIE x = 0.432, y = 0.494, Y = 62.9 cd/m 2 ) in the center of a computer screen, and then two identical green disks (radius = 0.6 ; CIE x = 0.286, y = 0.606, Y = 43.2 cd/m 2 ) were presented 5 away in diametrically opposed locations. The central target disappeared after a 0.5-s delay period, and the animal was required to shift its gaze to one of the targets. At the end of a 0.5-s hold period, a red ring (radius = 1 ; CIE x = 0.632, y = 0.341, Y = 17.6 cd/m 2 ) appeared around the target selected by the computer, and the animal maintained its fixation for another 0.2 s. The animal was rewarded at the end of this second hold period, but only if it selected the same target as the computer. The computer had been programmed to exploit certain biases displayed by the animal in making its choices. Each neuron was also tested in a visual search task. This task was identical to the free-choice task, except that one of the targets in the free-choice task was replaced by a distractor (red disk). The animal was required to shift its gaze toward the remaining target (green disk), and this was rewarded randomly with 50% probability. This made it possible to examine the effect of reward on the neural activity. The location of the target was selected from the two alternative locations pseudo-randomly for each search trial. Algorithms for computer opponent. During the free-choice task, the computer selected its target according to one of three different algorithms. In algorithm 0, the computer selected the two targets randomly with equal probabilities, which corresponds to the Nash equilibrium in the matching pennies game. In algorithm 1, the computer exploited any systematic bias in the animal s choice sequence to minimize the animal s reward rate. The computer saved the entire history of the animal s choices in a given session, and used this information to predict the animal s next choice by testing a set of hypotheses. First, the conditional probabilities of choosing each target given the animal s choices in the preceding n trials (n = 0 to 4) were estimated. Next, each of these conditional probabilities was tested against the hypothesis that the animal had chosen both targets with equal probabilities. When none of these hypotheses was rejected, the computer selected each target randomly with 50% probability, as in algorithm 0. Otherwise, the computer biased its selection according to the probability with the largest deviation from 0.5 that was statistically significant (binomial test, P < 0.05). For example, if the animal chose the right-hand target with 80% probability, the computer selected the left-hand target with the same probability. Therefore, to maximize reward, animals needed to choose both targets with equal frequency and select a target on each trial independently from previous choices. In algorithm 2, the computer exploited any systematic bias in the animal s choice and reward sequences. In addition to the hypotheses tested in algorithm 1, algorithm 2 also tested the hypothesis that the animal s decisions were independent of prior choices and their payoffs in the preceding n trials (n =1 to 4). Thus, to maximize total reward in algorithm 2, it was necessary for the animal to choose both targets with equal frequency and to make choices independently from previous choices and payoffs. Neurophysiological recording. Single-unit activity was recorded from the neurons in the DLPFC of two monkeys using a five-channel multi-electrode recording system (Thomas Recording). The placement of the recording chamber was guided by magnetic resonance images, and this was confirmed in one animal by metal pins inserted in known anatomical locations. In addition, the frontal eye field (FEF) was defined in both animals as the area in which saccades were evoked by electrical stimulations with currents <50 µa (ref. 50). All the neurons described in the present study were anterior to the FEF. Analysis of behavioral data. The frequency of a behavioral event (e.g.,reward) was examined with the corresponding probability averaged across recording NATURE NEUROSCIENCE VOLUME 7 NUMBER 4 APRIL
7 sessions and its standard deviation. The values of mutual information were corrected for the finite sample size. Null hypotheses in the analysis of behavioral data were tested using a binomial test or a t-test (P < 0.05). Parameters in the reinforcement learning model were estimated by a maximum likelihood procedure, using a function minimization algorithm in Matlab (Mathworks Inc.), and confidence intervals were estimated by profile likelihood intervals 31. Analysis of neural data. Spikes during a series of 500-ms bins were counted separately for each trial. The effects of the animal s choice (P) and reward (R) in the previous trial and the choice in the current trial (C) were analyzed in a 3-way ANOVA (P R C). The effect of the task (search versus free-choice) was analyzed in a four-way ANOVA (Task P R C). As a control analysis to determine whether the task effect was due to non-stationarity in neural activity, the same four-way ANOVA was performed for the first two successive blocks of 128 trials in the free-choice task (Fig. 3). To determine whether eye movements were confounding factors, the above analysis was repeated using the residuals from the following regression model: S = a 0 + a 1 X pre80 + a 2 Y pre80 + a 3 X FP + a 4 Y FP + a 5 X SV + a 6 Y SV + a 7 SRT + a 8 PV + ε where S indicates the spike count, X pre80 (Y pre80 ) the horizontal (vertical) eye position 80 ms before the onset of central fixation target, X FP (Y FP ) the average horizontal (vertical) eye position during the fore-period, X SV (Y SV ) the horizontal (vertical) component of the saccade directed to the target, SRT and PV the saccadic reaction time and the peak velocity of the saccade, and ε the error term. ACKNOWLEDGMENTS We thank L. Carr, R. Farrell, B. McGreevy and T. Twietmeyer for their technical assistance, J. Swan-Stone for programming, X.-J. Wang for discussions, and B. Averbeck and J. Malpeli for critically reading the manuscript. This work was supported by the James S. McDonnell Foundation and the National Institutes of Health (NS44270 and EY01319). COMPETING INTERESTS STATEMENT The authors declare that they have no competing financial interests. Received 23 December 2003; accepted 12 February 2004 Published online at 1. Von Neumann J. & Morgenstern O. Theory of Games and Economic Behavior (Princeton Univ. Press, New Jersey, 1944). 2. Fudenberg, D. & Tirole, J. Game Theory (MIT Press, Cambridge, Massachusetts, 1991). 3. Dixit, A. & Skeath, S. Games of Strategy (Norton, New York, 1999). 4. Glimcher, P.W. Decisions, Uncertainty, and the Brain (MIT Press, Cambridge, Massachusetts, 2003). 5. Nash, J.F. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 36, (1950). 6. Robinson, J. An iterative method of solving a game. Ann. Math. 54, (1951). 7. Binmore, K., Swierzbinski, J. & Proulx, C. Does minimax work? An experimental study. Econ. J. 111, (2001). 8. Touhey, J.C. Decision processes, expectations, and adoption of strategies in zerosum games. Hum. Relat. 27, (1974). 9. O Neill, B. Nonmetric test of the minimax theory of two-person zerosum games. Proc. Natl. Acad. Sci. USA 84, (1987). 10. Brown, J.N. & Rosenthal, R.W. Testing the minimax hypothesis: a re-examination of O Neill s game experiment. Econometrica 58, (1990). 11. Rapoport, A. & Boebel, R.B. Mixed strategies in strictly competitive games: a further test of the minimax hypothesis. Games Econ. Behav. 4, (1992). 12. Rapoport, A. & Budescu, D.V. Generation of random series in two-person strictly competitive games. J. Exp. Psychol. Gen. 121, (1992). 13. Budescu, D.V. & Rapoport, A. Subjective randomization in one- and two-person games. J. Behav. Dec. Making 7, (1994). 14. Ochs, J. Games with unique, mixed strategy equilibria: an experimental study. Games Econ. Behav. 10, (1995). 15. Sarin, R. & Vahid, F. Predicting how people play games: a simple dynamic model of choice. Games Econ. Behav. 34, (2001). 16. Shachat, J.M. Mixed strategy play and the minimax hypothesis. J. Econ. Theory 104, (2002). 17. Walker, M. & Wooders, J. Minimax play at Wimbledon. Am. Econ. Rev. 91, (2001). 18. Fudenberg, D. & Levine, D.K. Theory of Learning in Games (MIT Press, Cambridge, Massachusetts, 1998). 19. Mookherjee, D. & Sopher, B. Learning behavior in an experimental matching pennies game. Games Econ. Behav. 7, (1994). 20. Erev, I. & Roth, A.E. Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibria. Am. Econ. Rev. 88, (1998). 21. Camerer, C.F. Behavioral Game Theory (Princeton Univ. Press, Princeton, New Jersey, 2003). 22. Simon, H.A. Models of Man (Wiley, New York, 1957). 23. Kahneman, D., Slovic, P. & Tversky, A. Judgement Under Uncertainty: Heuristics and Biases (Cambridge Univ. Press, Cambridge, UK, 1982). 24. O Neill, B. Comments on Brown and Rosenthal s reexamination. Econometrica 59, (1991). 25. Rapoport, A. & Budescu, D.V. Randomization in individual choice behavior. Psychol. Rev. 104, (1997). 26. Chen, H-C., Friedman, J.W. & Thisse, J-F. Boundedly rational Nash equilibrium: a probabilistic choice approach. Games Econ. Behav. 18, (1997). 27. Rubinstein, A. Modeling Bounded Rationality (MIT Press, Cambridge, Massachusetts, 1998). 28. Sutton, R.S. & Barto, A.G. Reinforcement Learning: an Introduction (MIT Press, Cambridge, Massachusetts, 1998). 29. Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. Machine Learning: Proc. 11th Int. Conf. pp (Morgan Kaufmann, San Francisco, California, 1994) 30. Christensen, R. Log-linear Models and Logistic Regression edn. 2 (Springer-Verlag, New York, 1997). 31. Burnham, K.P. & Anderson, D.R. Model Selection and Multimodel Inference 2nd edn. (Springer-Verlag, New York, 2002). 32. Byrne, R.W. & Whiten, A. Machiavellian Intelligence: Social Expertise and the Evolution of Intellect in Monkeys, Apes and Humans (Oxford Univ. Press, Oxford, UK, 1988). 33. Whiten, A. & Byrne, R.W. Machiavellian Intelligence II: Extensions and Evaluations (Cambridge Univ. Press, Cambridge, UK, 1997). 34. Schultz, W. Predictive reward signal of dopamine neurons. J. Neurophysiol. 80, 1 27 (1998). 35. Rolls, E.T. Brain and Emotion (Oxford Univ. Press, Oxford, UK, 1999). 36. Amador, N., Schlag-Rey, M. & Schlag, J. Reward-predicting and reward detecting neuronal activity in the primate supplementary eye field. J. Neurophysiol. 84, (2000). 37. Stuphorn, V., Taylor, T.L. & Schall, J.D. Performance monitoring by the supplementary eye field. Nature 408, (2000). 38. Ito, S., Stuphorn, V., Brown, J.W. & Schall, J.D. Performance monitoring by the anterior cingulate cortex during saccade countermanding. Science 302, (2003). 39. Kawagoe, R., Takikawa, Y. & Hikosaka, O. Expectation of reward modulates cognitive signals in the basal ganglia. Nat. Neurosci. 1, (1998). 40. Platt, M.L. & Glimcher, P.W. Neural correlates of decision variables in parietal cortex. Nature 400, (1999). 41. Shidara, M. & Richmond, B.J. Anterior cingulate: single neuronal signals related to degree of reward expectancy. Science 296, (2002). 42. Ikeda, T. & Hikosaka, O. Reward-dependent gain and bias of visual responses in primate superior colliculus. Neuron 39, (2003). 43. McCoy, A.N., Crowley, J.C., Haghighian, G., Dean, H.L. & Platt, M.L. Saccade reward signals in posterior cingulate cortex. Neuron 40, (2003). 44. Watanabe, M. Reward expectancy in primate prefrontal cortex. Nature 382, (1996). 45. Leon, M.I. & Shadlen, M.N. Effect of expected reward magnitude on the response of neurons in the dorsolateral prefrontal cortex of the macaque. Neuron 24, (1999). 46. Kobayashi, S., Lauwereyns, J., Koizumi, M., Sakagami, M. & Hikosaka, O. Influence of reward expectation on visuospatial processing in macaque lateral prefrontal cortex. J. Neurophysiol. 87, (2002). 47. Roesch, M.R. & Olson, C.R. Impact of expected reward on neuronal activity in prefrontal cortex, frontal and supplementary eye fields and premotor cortex. J. Neurophysiol. 90, (2003). 48. Tsujimoto, S. & Sawaguchi, T. Neuronal representation of response outcome in the primate prefrontal cortex. Cereb. Cortex 14, (2004). 49. Wang, X.-J. Probabilistic decision making by slow reverberation in cortical circuits. Neuron 36, (2002). 50. Bruce, C.J., Goldberg, M.E., Bushnell, M.C. & Stanton, G.B. Primate frontal eye fields. II. Physiological and anatomical correlates of electrically evoked eye movements. J. Neurophysiol. 54, (1985). 410 VOLUME 7 NUMBER 4 APRIL 2004 NATURE NEUROSCIENCE
Lateral Intraparietal Cortex and Reinforcement Learning during a Mixed-Strategy Game
 7278 The Journal of Neuroscience, June 3, 2009 29(22):7278 7289 Behavioral/Systems/Cognitive Lateral Intraparietal Cortex and Reinforcement Learning during a Mixed-Strategy Game Hyojung Seo, 1 * Dominic
7278 The Journal of Neuroscience, June 3, 2009 29(22):7278 7289 Behavioral/Systems/Cognitive Lateral Intraparietal Cortex and Reinforcement Learning during a Mixed-Strategy Game Hyojung Seo, 1 * Dominic
Supplementary materials for: Executive control processes underlying multi- item working memory
 Supplementary materials for: Executive control processes underlying multi- item working memory Antonio H. Lara & Jonathan D. Wallis Supplementary Figure 1 Supplementary Figure 1. Behavioral measures of
Supplementary materials for: Executive control processes underlying multi- item working memory Antonio H. Lara & Jonathan D. Wallis Supplementary Figure 1 Supplementary Figure 1. Behavioral measures of
Choosing the Greater of Two Goods: Neural Currencies for Valuation and Decision Making
 Choosing the Greater of Two Goods: Neural Currencies for Valuation and Decision Making Leo P. Surgre, Gres S. Corrado and William T. Newsome Presenter: He Crane Huang 04/20/2010 Outline Studies on neural
Choosing the Greater of Two Goods: Neural Currencies for Valuation and Decision Making Leo P. Surgre, Gres S. Corrado and William T. Newsome Presenter: He Crane Huang 04/20/2010 Outline Studies on neural
Neuronal representations of cognitive state: reward or attention?
 Opinion TRENDS in Cognitive Sciences Vol.8 No.6 June 2004 representations of cognitive state: reward or attention? John H.R. Maunsell Howard Hughes Medical Institute & Baylor College of Medicine, Division
Opinion TRENDS in Cognitive Sciences Vol.8 No.6 June 2004 representations of cognitive state: reward or attention? John H.R. Maunsell Howard Hughes Medical Institute & Baylor College of Medicine, Division
Effects of Sequential Context on Judgments and Decisions in the Prisoner s Dilemma Game
 Effects of Sequential Context on Judgments and Decisions in the Prisoner s Dilemma Game Ivaylo Vlaev (ivaylo.vlaev@psy.ox.ac.uk) Department of Experimental Psychology, University of Oxford, Oxford, OX1
Effects of Sequential Context on Judgments and Decisions in the Prisoner s Dilemma Game Ivaylo Vlaev (ivaylo.vlaev@psy.ox.ac.uk) Department of Experimental Psychology, University of Oxford, Oxford, OX1
Double dissociation of value computations in orbitofrontal and anterior cingulate neurons
 Supplementary Information for: Double dissociation of value computations in orbitofrontal and anterior cingulate neurons Steven W. Kennerley, Timothy E. J. Behrens & Jonathan D. Wallis Content list: Supplementary
Supplementary Information for: Double dissociation of value computations in orbitofrontal and anterior cingulate neurons Steven W. Kennerley, Timothy E. J. Behrens & Jonathan D. Wallis Content list: Supplementary
Distributed Coding of Actual and Hypothetical Outcomes in the Orbital and Dorsolateral Prefrontal Cortex
 Article Distributed Coding of Actual and Hypothetical Outcomes in the Orbital and Dorsolateral Prefrontal Cortex Hiroshi Abe 1 and Daeyeol Lee 1,2,3, * 1 Department of Neurobiology 2 Kavli Institute for
Article Distributed Coding of Actual and Hypothetical Outcomes in the Orbital and Dorsolateral Prefrontal Cortex Hiroshi Abe 1 and Daeyeol Lee 1,2,3, * 1 Department of Neurobiology 2 Kavli Institute for
A neural circuit model of decision making!
 A neural circuit model of decision making! Xiao-Jing Wang! Department of Neurobiology & Kavli Institute for Neuroscience! Yale University School of Medicine! Three basic questions on decision computations!!
A neural circuit model of decision making! Xiao-Jing Wang! Department of Neurobiology & Kavli Institute for Neuroscience! Yale University School of Medicine! Three basic questions on decision computations!!
SUPPLEMENTARY INFORMATION
 doi:10.1038/nature14066 Supplementary discussion Gradual accumulation of evidence for or against different choices has been implicated in many types of decision-making, including value-based decisions
doi:10.1038/nature14066 Supplementary discussion Gradual accumulation of evidence for or against different choices has been implicated in many types of decision-making, including value-based decisions
Cognitive modeling versus game theory: Why cognition matters
 Cognitive modeling versus game theory: Why cognition matters Matthew F. Rutledge-Taylor (mrtaylo2@connect.carleton.ca) Institute of Cognitive Science, Carleton University, 1125 Colonel By Drive Ottawa,
Cognitive modeling versus game theory: Why cognition matters Matthew F. Rutledge-Taylor (mrtaylo2@connect.carleton.ca) Institute of Cognitive Science, Carleton University, 1125 Colonel By Drive Ottawa,
There are, in total, four free parameters. The learning rate a controls how sharply the model
 Supplemental esults The full model equations are: Initialization: V i (0) = 1 (for all actions i) c i (0) = 0 (for all actions i) earning: V i (t) = V i (t - 1) + a * (r(t) - V i (t 1)) ((for chosen action
Supplemental esults The full model equations are: Initialization: V i (0) = 1 (for all actions i) c i (0) = 0 (for all actions i) earning: V i (t) = V i (t - 1) + a * (r(t) - V i (t 1)) ((for chosen action
Attention Response Functions: Characterizing Brain Areas Using fmri Activation during Parametric Variations of Attentional Load
 Attention Response Functions: Characterizing Brain Areas Using fmri Activation during Parametric Variations of Attentional Load Intro Examine attention response functions Compare an attention-demanding
Attention Response Functions: Characterizing Brain Areas Using fmri Activation during Parametric Variations of Attentional Load Intro Examine attention response functions Compare an attention-demanding
Supplementary Eye Field Encodes Reward Prediction Error
 9 The Journal of Neuroscience, February 9, 3(9):9 93 Behavioral/Systems/Cognitive Supplementary Eye Field Encodes Reward Prediction Error NaYoung So and Veit Stuphorn, Department of Neuroscience, The Johns
9 The Journal of Neuroscience, February 9, 3(9):9 93 Behavioral/Systems/Cognitive Supplementary Eye Field Encodes Reward Prediction Error NaYoung So and Veit Stuphorn, Department of Neuroscience, The Johns
Sum of Neurally Distinct Stimulus- and Task-Related Components.
 SUPPLEMENTARY MATERIAL for Cardoso et al. 22 The Neuroimaging Signal is a Linear Sum of Neurally Distinct Stimulus- and Task-Related Components. : Appendix: Homogeneous Linear ( Null ) and Modified Linear
SUPPLEMENTARY MATERIAL for Cardoso et al. 22 The Neuroimaging Signal is a Linear Sum of Neurally Distinct Stimulus- and Task-Related Components. : Appendix: Homogeneous Linear ( Null ) and Modified Linear
How rational are your decisions? Neuroeconomics
 How rational are your decisions? Neuroeconomics Hecke CNS Seminar WS 2006/07 Motivation Motivation Ferdinand Porsche "Wir wollen Autos bauen, die keiner braucht aber jeder haben will." Outline 1 Introduction
How rational are your decisions? Neuroeconomics Hecke CNS Seminar WS 2006/07 Motivation Motivation Ferdinand Porsche "Wir wollen Autos bauen, die keiner braucht aber jeder haben will." Outline 1 Introduction
Beyond bumps: Spiking networks that store sets of functions
 Neurocomputing 38}40 (2001) 581}586 Beyond bumps: Spiking networks that store sets of functions Chris Eliasmith*, Charles H. Anderson Department of Philosophy, University of Waterloo, Waterloo, Ont, N2L
Neurocomputing 38}40 (2001) 581}586 Beyond bumps: Spiking networks that store sets of functions Chris Eliasmith*, Charles H. Anderson Department of Philosophy, University of Waterloo, Waterloo, Ont, N2L
Introduction to Game Theory:
 Introduction to Game Theory: Levels of Reasoning Version 10/29/17 How Many Levels Do Players Reason? When we first hear about game theory, we are naturally led to ponder: How does a player Ann in a game
Introduction to Game Theory: Levels of Reasoning Version 10/29/17 How Many Levels Do Players Reason? When we first hear about game theory, we are naturally led to ponder: How does a player Ann in a game
Supplemental Material
 Supplemental Material Recording technique Multi-unit activity (MUA) was recorded from electrodes that were chronically implanted (Teflon-coated platinum-iridium wires) in the primary visual cortex representing
Supplemental Material Recording technique Multi-unit activity (MUA) was recorded from electrodes that were chronically implanted (Teflon-coated platinum-iridium wires) in the primary visual cortex representing
COOPERATION 1. How Economic Rewards Affect Cooperation Reconsidered. Dan R. Schley and John H. Kagel. The Ohio State University
 COOPERATION 1 Running Head: COOPERATION How Economic Rewards Affect Cooperation Reconsidered Dan R. Schley and John H. Kagel The Ohio State University In Preparation Do Not Cite Address correspondence
COOPERATION 1 Running Head: COOPERATION How Economic Rewards Affect Cooperation Reconsidered Dan R. Schley and John H. Kagel The Ohio State University In Preparation Do Not Cite Address correspondence
Supplementary Information
 Supplementary Information The neural correlates of subjective value during intertemporal choice Joseph W. Kable and Paul W. Glimcher a 10 0 b 10 0 10 1 10 1 Discount rate k 10 2 Discount rate k 10 2 10
Supplementary Information The neural correlates of subjective value during intertemporal choice Joseph W. Kable and Paul W. Glimcher a 10 0 b 10 0 10 1 10 1 Discount rate k 10 2 Discount rate k 10 2 10
Supplementary Figure 1. Example of an amygdala neuron whose activity reflects value during the visual stimulus interval. This cell responded more
 1 Supplementary Figure 1. Example of an amygdala neuron whose activity reflects value during the visual stimulus interval. This cell responded more strongly when an image was negative than when the same
1 Supplementary Figure 1. Example of an amygdala neuron whose activity reflects value during the visual stimulus interval. This cell responded more strongly when an image was negative than when the same
Morton-Style Factorial Coding of Color in Primary Visual Cortex
 Morton-Style Factorial Coding of Color in Primary Visual Cortex Javier R. Movellan Institute for Neural Computation University of California San Diego La Jolla, CA 92093-0515 movellan@inc.ucsd.edu Thomas
Morton-Style Factorial Coding of Color in Primary Visual Cortex Javier R. Movellan Institute for Neural Computation University of California San Diego La Jolla, CA 92093-0515 movellan@inc.ucsd.edu Thomas
Introduction to Computational Neuroscience
 Introduction to Computational Neuroscience Lecture 11: Attention & Decision making Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis
Introduction to Computational Neuroscience Lecture 11: Attention & Decision making Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis
Different inhibitory effects by dopaminergic modulation and global suppression of activity
 Different inhibitory effects by dopaminergic modulation and global suppression of activity Takuji Hayashi Department of Applied Physics Tokyo University of Science Osamu Araki Department of Applied Physics
Different inhibitory effects by dopaminergic modulation and global suppression of activity Takuji Hayashi Department of Applied Physics Tokyo University of Science Osamu Araki Department of Applied Physics
Selective bias in temporal bisection task by number exposition
 Selective bias in temporal bisection task by number exposition Carmelo M. Vicario¹ ¹ Dipartimento di Psicologia, Università Roma la Sapienza, via dei Marsi 78, Roma, Italy Key words: number- time- spatial
Selective bias in temporal bisection task by number exposition Carmelo M. Vicario¹ ¹ Dipartimento di Psicologia, Università Roma la Sapienza, via dei Marsi 78, Roma, Italy Key words: number- time- spatial
5th Mini-Symposium on Cognition, Decision-making and Social Function: In Memory of Kang Cheng
 5th Mini-Symposium on Cognition, Decision-making and Social Function: In Memory of Kang Cheng 13:30-13:35 Opening 13:30 17:30 13:35-14:00 Metacognition in Value-based Decision-making Dr. Xiaohong Wan (Beijing
5th Mini-Symposium on Cognition, Decision-making and Social Function: In Memory of Kang Cheng 13:30-13:35 Opening 13:30 17:30 13:35-14:00 Metacognition in Value-based Decision-making Dr. Xiaohong Wan (Beijing
Representation of negative motivational value in the primate
 Representation of negative motivational value in the primate lateral habenula Masayuki Matsumoto & Okihide Hikosaka Supplementary Figure 1 Anticipatory licking and blinking. (a, b) The average normalized
Representation of negative motivational value in the primate lateral habenula Masayuki Matsumoto & Okihide Hikosaka Supplementary Figure 1 Anticipatory licking and blinking. (a, b) The average normalized
Reinforcement Learning : Theory and Practice - Programming Assignment 1
 Reinforcement Learning : Theory and Practice - Programming Assignment 1 August 2016 Background It is well known in Game Theory that the game of Rock, Paper, Scissors has one and only one Nash Equilibrium.
Reinforcement Learning : Theory and Practice - Programming Assignment 1 August 2016 Background It is well known in Game Theory that the game of Rock, Paper, Scissors has one and only one Nash Equilibrium.
A Neural Model of Context Dependent Decision Making in the Prefrontal Cortex
 A Neural Model of Context Dependent Decision Making in the Prefrontal Cortex Sugandha Sharma (s72sharm@uwaterloo.ca) Brent J. Komer (bjkomer@uwaterloo.ca) Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris
A Neural Model of Context Dependent Decision Making in the Prefrontal Cortex Sugandha Sharma (s72sharm@uwaterloo.ca) Brent J. Komer (bjkomer@uwaterloo.ca) Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris
A model to explain the emergence of reward expectancy neurons using reinforcement learning and neural network $
 Neurocomputing 69 (26) 1327 1331 www.elsevier.com/locate/neucom A model to explain the emergence of reward expectancy neurons using reinforcement learning and neural network $ Shinya Ishii a,1, Munetaka
Neurocomputing 69 (26) 1327 1331 www.elsevier.com/locate/neucom A model to explain the emergence of reward expectancy neurons using reinforcement learning and neural network $ Shinya Ishii a,1, Munetaka
Belief Formation in a Signalling Game without Common Prior: An Experiment
 Belief Formation in a Signalling Game without Common Prior: An Experiment Alex Possajennikov University of Nottingham February 2012 Abstract Using belief elicitation, the paper investigates the formation
Belief Formation in a Signalling Game without Common Prior: An Experiment Alex Possajennikov University of Nottingham February 2012 Abstract Using belief elicitation, the paper investigates the formation
What Happens in the Field Stays in the Field: Professionals Do Not Play Minimax in Laboratory Experiments
 What Happens in the Field Stays in the Field: Professionals Do Not Play Minimax in Laboratory Experiments Steven D. Levitt, John A. List, and David H. Reiley American Economic Review July 2008 HELLO! I
What Happens in the Field Stays in the Field: Professionals Do Not Play Minimax in Laboratory Experiments Steven D. Levitt, John A. List, and David H. Reiley American Economic Review July 2008 HELLO! I
The detection of visual signals by macaque frontal eye field during masking
 articles The detection of visual signals by macaque frontal eye field during masking Kirk G. Thompson and Jeffrey D. Schall Vanderbilt Vision Research Center, Department of Psychology, Wilson Hall, Vanderbilt
articles The detection of visual signals by macaque frontal eye field during masking Kirk G. Thompson and Jeffrey D. Schall Vanderbilt Vision Research Center, Department of Psychology, Wilson Hall, Vanderbilt
Supplementary Motor Area exerts Proactive and Reactive Control of Arm Movements
 Supplementary Material Supplementary Motor Area exerts Proactive and Reactive Control of Arm Movements Xiaomo Chen, Katherine Wilson Scangos 2 and Veit Stuphorn,2 Department of Psychological and Brain
Supplementary Material Supplementary Motor Area exerts Proactive and Reactive Control of Arm Movements Xiaomo Chen, Katherine Wilson Scangos 2 and Veit Stuphorn,2 Department of Psychological and Brain
Resistance to forgetting associated with hippocampus-mediated. reactivation during new learning
 Resistance to Forgetting 1 Resistance to forgetting associated with hippocampus-mediated reactivation during new learning Brice A. Kuhl, Arpeet T. Shah, Sarah DuBrow, & Anthony D. Wagner Resistance to
Resistance to Forgetting 1 Resistance to forgetting associated with hippocampus-mediated reactivation during new learning Brice A. Kuhl, Arpeet T. Shah, Sarah DuBrow, & Anthony D. Wagner Resistance to
Paradoxes and Violations of Normative Decision Theory. Jay Simon Defense Resources Management Institute, Naval Postgraduate School
 Paradoxes and Violations of Normative Decision Theory Jay Simon Defense Resources Management Institute, Naval Postgraduate School Yitong Wang University of California, Irvine L. Robin Keller University
Paradoxes and Violations of Normative Decision Theory Jay Simon Defense Resources Management Institute, Naval Postgraduate School Yitong Wang University of California, Irvine L. Robin Keller University
Supplementary Material for
 Supplementary Material for Selective neuronal lapses precede human cognitive lapses following sleep deprivation Supplementary Table 1. Data acquisition details Session Patient Brain regions monitored Time
Supplementary Material for Selective neuronal lapses precede human cognitive lapses following sleep deprivation Supplementary Table 1. Data acquisition details Session Patient Brain regions monitored Time
SUPPLEMENTARY INFORMATION
 Supplementary Statistics and Results This file contains supplementary statistical information and a discussion of the interpretation of the belief effect on the basis of additional data. We also present
Supplementary Statistics and Results This file contains supplementary statistical information and a discussion of the interpretation of the belief effect on the basis of additional data. We also present
SUPPLEMENTARY INFORMATION. Table 1 Patient characteristics Preoperative. language testing
 Categorical Speech Representation in the Human Superior Temporal Gyrus Edward F. Chang, Jochem W. Rieger, Keith D. Johnson, Mitchel S. Berger, Nicholas M. Barbaro, Robert T. Knight SUPPLEMENTARY INFORMATION
Categorical Speech Representation in the Human Superior Temporal Gyrus Edward F. Chang, Jochem W. Rieger, Keith D. Johnson, Mitchel S. Berger, Nicholas M. Barbaro, Robert T. Knight SUPPLEMENTARY INFORMATION
Behavioral Game Theory
 Outline (September 3, 2007) Outline (September 3, 2007) Introduction Outline (September 3, 2007) Introduction Examples of laboratory experiments Outline (September 3, 2007) Introduction Examples of laboratory
Outline (September 3, 2007) Outline (September 3, 2007) Introduction Outline (September 3, 2007) Introduction Examples of laboratory experiments Outline (September 3, 2007) Introduction Examples of laboratory
Introduction to Computational Neuroscience
 Introduction to Computational Neuroscience Lecture 5: Data analysis II Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis II 6 Single
Introduction to Computational Neuroscience Lecture 5: Data analysis II Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis II 6 Single
Human and Optimal Exploration and Exploitation in Bandit Problems
 Human and Optimal Exploration and ation in Bandit Problems Shunan Zhang (szhang@uci.edu) Michael D. Lee (mdlee@uci.edu) Miles Munro (mmunro@uci.edu) Department of Cognitive Sciences, 35 Social Sciences
Human and Optimal Exploration and ation in Bandit Problems Shunan Zhang (szhang@uci.edu) Michael D. Lee (mdlee@uci.edu) Miles Munro (mmunro@uci.edu) Department of Cognitive Sciences, 35 Social Sciences
Supplementary Information. Gauge size. midline. arcuate 10 < n < 15 5 < n < 10 1 < n < < n < 15 5 < n < 10 1 < n < 5. principal principal
 Supplementary Information set set = Reward = Reward Gauge size Gauge size 3 Numer of correct trials 3 Numer of correct trials Supplementary Fig.. Principle of the Gauge increase. The gauge size (y axis)
Supplementary Information set set = Reward = Reward Gauge size Gauge size 3 Numer of correct trials 3 Numer of correct trials Supplementary Fig.. Principle of the Gauge increase. The gauge size (y axis)
Learning to Attend and to Ignore Is a Matter of Gains and Losses Chiara Della Libera and Leonardo Chelazzi
 PSYCHOLOGICAL SCIENCE Research Article Learning to Attend and to Ignore Is a Matter of Gains and Losses Chiara Della Libera and Leonardo Chelazzi Department of Neurological and Vision Sciences, Section
PSYCHOLOGICAL SCIENCE Research Article Learning to Attend and to Ignore Is a Matter of Gains and Losses Chiara Della Libera and Leonardo Chelazzi Department of Neurological and Vision Sciences, Section
Reward Size Informs Repeat-Switch Decisions and Strongly Modulates the Activity of Neurons in Parietal Cortex
 Cerebral Cortex, January 217;27: 447 459 doi:1.193/cercor/bhv23 Advance Access Publication Date: 21 October 2 Original Article ORIGINAL ARTICLE Size Informs Repeat-Switch Decisions and Strongly Modulates
Cerebral Cortex, January 217;27: 447 459 doi:1.193/cercor/bhv23 Advance Access Publication Date: 21 October 2 Original Article ORIGINAL ARTICLE Size Informs Repeat-Switch Decisions and Strongly Modulates
Dopamine neurons activity in a multi-choice task: reward prediction error or value function?
 Dopamine neurons activity in a multi-choice task: reward prediction error or value function? Jean Bellot 1,, Olivier Sigaud 1,, Matthew R Roesch 3,, Geoffrey Schoenbaum 5,, Benoît Girard 1,, Mehdi Khamassi
Dopamine neurons activity in a multi-choice task: reward prediction error or value function? Jean Bellot 1,, Olivier Sigaud 1,, Matthew R Roesch 3,, Geoffrey Schoenbaum 5,, Benoît Girard 1,, Mehdi Khamassi
Heterogeneous Coding of Temporally Discounted Values in the Dorsal and Ventral Striatum during Intertemporal Choice
 Article Heterogeneous Coding of Temporally Discounted Values in the Dorsal and Ventral Striatum during Intertemporal Choice Xinying Cai, 1,2 Soyoun Kim, 1,2 and Daeyeol Lee 1, * 1 Department of Neurobiology,
Article Heterogeneous Coding of Temporally Discounted Values in the Dorsal and Ventral Striatum during Intertemporal Choice Xinying Cai, 1,2 Soyoun Kim, 1,2 and Daeyeol Lee 1, * 1 Department of Neurobiology,
A Model of Dopamine and Uncertainty Using Temporal Difference
 A Model of Dopamine and Uncertainty Using Temporal Difference Angela J. Thurnham* (a.j.thurnham@herts.ac.uk), D. John Done** (d.j.done@herts.ac.uk), Neil Davey* (n.davey@herts.ac.uk), ay J. Frank* (r.j.frank@herts.ac.uk)
A Model of Dopamine and Uncertainty Using Temporal Difference Angela J. Thurnham* (a.j.thurnham@herts.ac.uk), D. John Done** (d.j.done@herts.ac.uk), Neil Davey* (n.davey@herts.ac.uk), ay J. Frank* (r.j.frank@herts.ac.uk)
SUPPLEMENTARY INFORMATION
 doi:10.1038/nature11239 Introduction The first Supplementary Figure shows additional regions of fmri activation evoked by the task. The second, sixth, and eighth shows an alternative way of analyzing reaction
doi:10.1038/nature11239 Introduction The first Supplementary Figure shows additional regions of fmri activation evoked by the task. The second, sixth, and eighth shows an alternative way of analyzing reaction
NIH Public Access Author Manuscript Nature. Author manuscript; available in PMC 2009 August 17.
 NIH Public Access Author Manuscript Published in final edited form as: Nature. 2008 May 15; 453(7193): 406 409. doi:10.1038/nature06849. Free choice activates a decision circuit between frontal and parietal
NIH Public Access Author Manuscript Published in final edited form as: Nature. 2008 May 15; 453(7193): 406 409. doi:10.1038/nature06849. Free choice activates a decision circuit between frontal and parietal
Deconstructing the Receptive Field: Information Coding in Macaque area MST
 : Information Coding in Macaque area MST Bart Krekelberg, Monica Paolini Frank Bremmer, Markus Lappe, Klaus-Peter Hoffmann Ruhr University Bochum, Dept. Zoology & Neurobiology ND7/30, 44780 Bochum, Germany
: Information Coding in Macaque area MST Bart Krekelberg, Monica Paolini Frank Bremmer, Markus Lappe, Klaus-Peter Hoffmann Ruhr University Bochum, Dept. Zoology & Neurobiology ND7/30, 44780 Bochum, Germany
Neural basis of quasi-rational decision making Daeyeol Lee
 Neural basis of quasi-rational decision making Daeyeol Lee Standard economic theories conceive homo economicus as a rational decision maker capable of maximizing utility. In reality, however, people tend
Neural basis of quasi-rational decision making Daeyeol Lee Standard economic theories conceive homo economicus as a rational decision maker capable of maximizing utility. In reality, however, people tend
Unit 1 Exploring and Understanding Data
 Unit 1 Exploring and Understanding Data Area Principle Bar Chart Boxplot Conditional Distribution Dotplot Empirical Rule Five Number Summary Frequency Distribution Frequency Polygon Histogram Interquartile
Unit 1 Exploring and Understanding Data Area Principle Bar Chart Boxplot Conditional Distribution Dotplot Empirical Rule Five Number Summary Frequency Distribution Frequency Polygon Histogram Interquartile
Hebbian Plasticity for Improving Perceptual Decisions
 Hebbian Plasticity for Improving Perceptual Decisions Tsung-Ren Huang Department of Psychology, National Taiwan University trhuang@ntu.edu.tw Abstract Shibata et al. reported that humans could learn to
Hebbian Plasticity for Improving Perceptual Decisions Tsung-Ren Huang Department of Psychology, National Taiwan University trhuang@ntu.edu.tw Abstract Shibata et al. reported that humans could learn to
Nature Neuroscience: doi: /nn Supplementary Figure 1. Task timeline for Solo and Info trials.
 Supplementary Figure 1 Task timeline for Solo and Info trials. Each trial started with a New Round screen. Participants made a series of choices between two gambles, one of which was objectively riskier
Supplementary Figure 1 Task timeline for Solo and Info trials. Each trial started with a New Round screen. Participants made a series of choices between two gambles, one of which was objectively riskier
CHOOSING THE GREATER OF TWO GOODS: NEURAL CURRENCIES FOR VALUATION AND DECISION MAKING
 CHOOSING THE GREATER OF TWO GOODS: NEURAL CURRENCIES FOR VALUATION AND DECISION MAKING Leo P. Sugrue, Greg S. Corrado and William T. Newsome Abstract To make adaptive decisions, animals must evaluate the
CHOOSING THE GREATER OF TWO GOODS: NEURAL CURRENCIES FOR VALUATION AND DECISION MAKING Leo P. Sugrue, Greg S. Corrado and William T. Newsome Abstract To make adaptive decisions, animals must evaluate the
Supplementary Figure 1. Recording sites.
 Supplementary Figure 1 Recording sites. (a, b) Schematic of recording locations for mice used in the variable-reward task (a, n = 5) and the variable-expectation task (b, n = 5). RN, red nucleus. SNc,
Supplementary Figure 1 Recording sites. (a, b) Schematic of recording locations for mice used in the variable-reward task (a, n = 5) and the variable-expectation task (b, n = 5). RN, red nucleus. SNc,
Planning activity for internally generated reward goals in monkey amygdala neurons
 Europe PMC Funders Group Author Manuscript Published in final edited form as: Nat Neurosci. 2015 March ; 18(3): 461 469. doi:10.1038/nn.3925. Planning activity for internally generated reward goals in
Europe PMC Funders Group Author Manuscript Published in final edited form as: Nat Neurosci. 2015 March ; 18(3): 461 469. doi:10.1038/nn.3925. Planning activity for internally generated reward goals in
arxiv: v1 [cs.gt] 14 Mar 2014
![arxiv: v1 [cs.gt] 14 Mar 2014](/thumbs/72/67278486.jpg "arxiv: v1 [cs.gt] 14 Mar 2014") Generalized prisoner s dilemma Xinyang Deng a, Qi Liu b, Yong Deng a,c, arxiv:1403.3595v1 [cs.gt] 14 Mar 2014 a School of Computer and Information Science, Southwest University, Chongqing, 400715, China
Generalized prisoner s dilemma Xinyang Deng a, Qi Liu b, Yong Deng a,c, arxiv:1403.3595v1 [cs.gt] 14 Mar 2014 a School of Computer and Information Science, Southwest University, Chongqing, 400715, China
Motor Systems I Cortex. Reading: BCP Chapter 14
 Motor Systems I Cortex Reading: BCP Chapter 14 Principles of Sensorimotor Function Hierarchical Organization association cortex at the highest level, muscles at the lowest signals flow between levels over
Motor Systems I Cortex Reading: BCP Chapter 14 Principles of Sensorimotor Function Hierarchical Organization association cortex at the highest level, muscles at the lowest signals flow between levels over
[1] provides a philosophical introduction to the subject. Simon [21] discusses numerous topics in economics; see [2] for a broad economic survey.
![[1] provides a philosophical introduction to the subject. Simon [21] discusses numerous topics in economics; see [2] for a broad economic survey.](/thumbs/78/76811320.jpg "[1] provides a philosophical introduction to the subject. Simon [21] discusses numerous topics in economics; see [2] for a broad economic survey.") Draft of an article to appear in The MIT Encyclopedia of the Cognitive Sciences (Rob Wilson and Frank Kiel, editors), Cambridge, Massachusetts: MIT Press, 1997. Copyright c 1997 Jon Doyle. All rights reserved
Draft of an article to appear in The MIT Encyclopedia of the Cognitive Sciences (Rob Wilson and Frank Kiel, editors), Cambridge, Massachusetts: MIT Press, 1997. Copyright c 1997 Jon Doyle. All rights reserved
Describe what is meant by a placebo Contrast the double-blind procedure with the single-blind procedure Review the structure for organizing a memo
 Please note the page numbers listed for the Lind book may vary by a page or two depending on which version of the textbook you have. Readings: Lind 1 11 (with emphasis on chapters 5, 6, 7, 8, 9 10 & 11)
Please note the page numbers listed for the Lind book may vary by a page or two depending on which version of the textbook you have. Readings: Lind 1 11 (with emphasis on chapters 5, 6, 7, 8, 9 10 & 11)
Walras-Bowley Lecture 2003 (extended)
") Walras-Bowley Lecture 2003 (extended) Sergiu Hart This version: November 2005 SERGIU HART c 2005 p. 1 ADAPTIVE HEURISTICS A Little Rationality Goes a Long Way Sergiu Hart Center for Rationality, Dept.
Walras-Bowley Lecture 2003 (extended) Sergiu Hart This version: November 2005 SERGIU HART c 2005 p. 1 ADAPTIVE HEURISTICS A Little Rationality Goes a Long Way Sergiu Hart Center for Rationality, Dept.
Information Acquisition in the Iterated Prisoner s Dilemma Game: An Eye-Tracking Study
 Information Acquisition in the Iterated Prisoner s Dilemma Game: An Eye-Tracking Study Evgenia Hristova (ehristova@cogs.nbu.bg ) Central and Eastern European Center for Cognitive Science, New Bulgarian
Information Acquisition in the Iterated Prisoner s Dilemma Game: An Eye-Tracking Study Evgenia Hristova (ehristova@cogs.nbu.bg ) Central and Eastern European Center for Cognitive Science, New Bulgarian
Veronika Grimm, Friederike Mengel. Let me sleep on it: Delay reduces rejection rates in Ultimatum Games RM/10/017
 Veronika Grimm, Friederike Mengel Let me sleep on it: Delay reduces rejection rates in Ultimatum Games RM/10/017 Let me sleep on it: Delay reduces rejection rates in Ultimatum Games Veronika Grimm Friederike
Veronika Grimm, Friederike Mengel Let me sleep on it: Delay reduces rejection rates in Ultimatum Games RM/10/017 Let me sleep on it: Delay reduces rejection rates in Ultimatum Games Veronika Grimm Friederike
Business Statistics Probability
 Business Statistics The following was provided by Dr. Suzanne Delaney, and is a comprehensive review of Business Statistics. The workshop instructor will provide relevant examples during the Skills Assessment
Business Statistics The following was provided by Dr. Suzanne Delaney, and is a comprehensive review of Business Statistics. The workshop instructor will provide relevant examples during the Skills Assessment
In this paper we intend to explore the manner in which decision-making. Equivalence and Stooge Strategies. in Zero-Sum Games
 Equivalence and Stooge Strategies in Zero-Sum Games JOHN FOX MELVIN GUYER Mental Health Research Institute University of Michigan Classes of two-person zero-sum games termed "equivalent games" are defined.
Equivalence and Stooge Strategies in Zero-Sum Games JOHN FOX MELVIN GUYER Mental Health Research Institute University of Michigan Classes of two-person zero-sum games termed "equivalent games" are defined.
The primate amygdala combines information about space and value
 The primate amygdala combines information about space and Christopher J Peck 1,8, Brian Lau 1,7,8 & C Daniel Salzman 1 6 npg 213 Nature America, Inc. All rights reserved. A stimulus predicting reinforcement
The primate amygdala combines information about space and Christopher J Peck 1,8, Brian Lau 1,7,8 & C Daniel Salzman 1 6 npg 213 Nature America, Inc. All rights reserved. A stimulus predicting reinforcement
An Experiment to Evaluate Bayesian Learning of Nash Equilibrium Play
 . An Experiment to Evaluate Bayesian Learning of Nash Equilibrium Play James C. Cox 1, Jason Shachat 2, and Mark Walker 1 1. Department of Economics, University of Arizona 2. Department of Economics, University
. An Experiment to Evaluate Bayesian Learning of Nash Equilibrium Play James C. Cox 1, Jason Shachat 2, and Mark Walker 1 1. Department of Economics, University of Arizona 2. Department of Economics, University
THE PREFRONTAL CORTEX. Connections. Dorsolateral FrontalCortex (DFPC) Inputs
 Inputs") THE PREFRONTAL CORTEX Connections Dorsolateral FrontalCortex (DFPC) Inputs The DPFC receives inputs predominantly from somatosensory, visual and auditory cortical association areas in the parietal, occipital
THE PREFRONTAL CORTEX Connections Dorsolateral FrontalCortex (DFPC) Inputs The DPFC receives inputs predominantly from somatosensory, visual and auditory cortical association areas in the parietal, occipital
The role of cognitive effort in subjective reward devaluation and risky decision-making
 The role of cognitive effort in subjective reward devaluation and risky decision-making Matthew A J Apps 1,2, Laura Grima 2, Sanjay Manohar 2, Masud Husain 1,2 1 Nuffield Department of Clinical Neuroscience,
The role of cognitive effort in subjective reward devaluation and risky decision-making Matthew A J Apps 1,2, Laura Grima 2, Sanjay Manohar 2, Masud Husain 1,2 1 Nuffield Department of Clinical Neuroscience,
A Drift Diffusion Model of Proactive and Reactive Control in a Context-Dependent Two-Alternative Forced Choice Task
 A Drift Diffusion Model of Proactive and Reactive Control in a Context-Dependent Two-Alternative Forced Choice Task Olga Lositsky lositsky@princeton.edu Robert C. Wilson Department of Psychology University
A Drift Diffusion Model of Proactive and Reactive Control in a Context-Dependent Two-Alternative Forced Choice Task Olga Lositsky lositsky@princeton.edu Robert C. Wilson Department of Psychology University
Emotion Explained. Edmund T. Rolls
 Emotion Explained Edmund T. Rolls Professor of Experimental Psychology, University of Oxford and Fellow and Tutor in Psychology, Corpus Christi College, Oxford OXPORD UNIVERSITY PRESS Contents 1 Introduction:
Emotion Explained Edmund T. Rolls Professor of Experimental Psychology, University of Oxford and Fellow and Tutor in Psychology, Corpus Christi College, Oxford OXPORD UNIVERSITY PRESS Contents 1 Introduction:
Effects of similarity and history on neural mechanisms of visual selection
 tion. For this experiment, the target was specified as one combination of color and shape, and distractors were formed by other possible combinations. Thus, the target cannot be distinguished from the
tion. For this experiment, the target was specified as one combination of color and shape, and distractors were formed by other possible combinations. Thus, the target cannot be distinguished from the
 Peripheral facial paralysis (right side). The patient is asked to close her eyes and to retract their mouth (From Heimer) Hemiplegia of the left side. Note the characteristic position of the arm with
Peripheral facial paralysis (right side). The patient is asked to close her eyes and to retract their mouth (From Heimer) Hemiplegia of the left side. Note the characteristic position of the arm with
Introduction to Machine Learning. Katherine Heller Deep Learning Summer School 2018
 Introduction to Machine Learning Katherine Heller Deep Learning Summer School 2018 Outline Kinds of machine learning Linear regression Regularization Bayesian methods Logistic Regression Why we do this
Introduction to Machine Learning Katherine Heller Deep Learning Summer School 2018 Outline Kinds of machine learning Linear regression Regularization Bayesian methods Logistic Regression Why we do this
Jakub Steiner The University of Edinburgh. Abstract
 A trace of anger is enough: on the enforcement of social norms Jakub Steiner The University of Edinburgh Abstract It is well documented that the possibility of punishing free-riders increases contributions
A trace of anger is enough: on the enforcement of social norms Jakub Steiner The University of Edinburgh Abstract It is well documented that the possibility of punishing free-riders increases contributions
Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task
 Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris Eliasmith (celiasmith@uwaterloo.ca) Centre for Theoretical
Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris Eliasmith (celiasmith@uwaterloo.ca) Centre for Theoretical
Nash Equilibrium and Dynamics
 Nash Equilibrium and Dynamics Sergiu Hart September 12, 2008 John F. Nash, Jr., submitted his Ph.D. dissertation entitled Non-Cooperative Games to Princeton University in 1950. Read it 58 years later,
Nash Equilibrium and Dynamics Sergiu Hart September 12, 2008 John F. Nash, Jr., submitted his Ph.D. dissertation entitled Non-Cooperative Games to Princeton University in 1950. Read it 58 years later,
Readings: Textbook readings: OpenStax - Chapters 1 11 Online readings: Appendix D, E & F Plous Chapters 10, 11, 12 and 14
 Readings: Textbook readings: OpenStax - Chapters 1 11 Online readings: Appendix D, E & F Plous Chapters 10, 11, 12 and 14 Still important ideas Contrast the measurement of observable actions (and/or characteristics)
Readings: Textbook readings: OpenStax - Chapters 1 11 Online readings: Appendix D, E & F Plous Chapters 10, 11, 12 and 14 Still important ideas Contrast the measurement of observable actions (and/or characteristics)
The individual animals, the basic design of the experiments and the electrophysiological
 SUPPORTING ONLINE MATERIAL Material and Methods The individual animals, the basic design of the experiments and the electrophysiological techniques for extracellularly recording from dopamine neurons were
SUPPORTING ONLINE MATERIAL Material and Methods The individual animals, the basic design of the experiments and the electrophysiological techniques for extracellularly recording from dopamine neurons were
Reward-Dependent Modulation of Working Memory in Lateral Prefrontal Cortex
 The Journal of Neuroscience, March 11, 29 29(1):3259 327 3259 Behavioral/Systems/Cognitive Reward-Dependent Modulation of Working Memory in Lateral Prefrontal Cortex Steven W. Kennerley and Jonathan D.
The Journal of Neuroscience, March 11, 29 29(1):3259 327 3259 Behavioral/Systems/Cognitive Reward-Dependent Modulation of Working Memory in Lateral Prefrontal Cortex Steven W. Kennerley and Jonathan D.
Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task
 Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris Eliasmith (celiasmith@uwaterloo.ca) Centre for Theoretical
Neural Cognitive Modelling: A Biologically Constrained Spiking Neuron Model of the Tower of Hanoi Task Terrence C. Stewart (tcstewar@uwaterloo.ca) Chris Eliasmith (celiasmith@uwaterloo.ca) Centre for Theoretical
Bayesian integration in sensorimotor learning
 Bayesian integration in sensorimotor learning Introduction Learning new motor skills Variability in sensors and task Tennis: Velocity of ball Not all are equally probable over time Increased uncertainty:
Bayesian integration in sensorimotor learning Introduction Learning new motor skills Variability in sensors and task Tennis: Velocity of ball Not all are equally probable over time Increased uncertainty:
The optimism bias may support rational action
 The optimism bias may support rational action Falk Lieder, Sidharth Goel, Ronald Kwan, Thomas L. Griffiths University of California, Berkeley 1 Introduction People systematically overestimate the probability
The optimism bias may support rational action Falk Lieder, Sidharth Goel, Ronald Kwan, Thomas L. Griffiths University of California, Berkeley 1 Introduction People systematically overestimate the probability
Early Learning vs Early Variability 1.5 r = p = Early Learning r = p = e 005. Early Learning 0.
 The temporal structure of motor variability is dynamically regulated and predicts individual differences in motor learning ability Howard Wu *, Yohsuke Miyamoto *, Luis Nicolas Gonzales-Castro, Bence P.
The temporal structure of motor variability is dynamically regulated and predicts individual differences in motor learning ability Howard Wu *, Yohsuke Miyamoto *, Luis Nicolas Gonzales-Castro, Bence P.
Lateral Inhibition Explains Savings in Conditioning and Extinction
 Lateral Inhibition Explains Savings in Conditioning and Extinction Ashish Gupta & David C. Noelle ({ashish.gupta, david.noelle}@vanderbilt.edu) Department of Electrical Engineering and Computer Science
Lateral Inhibition Explains Savings in Conditioning and Extinction Ashish Gupta & David C. Noelle ({ashish.gupta, david.noelle}@vanderbilt.edu) Department of Electrical Engineering and Computer Science
Responsiveness to feedback as a personal trait
 Responsiveness to feedback as a personal trait Thomas Buser University of Amsterdam Leonie Gerhards University of Hamburg Joël van der Weele University of Amsterdam Pittsburgh, June 12, 2017 1 / 30 Feedback
Responsiveness to feedback as a personal trait Thomas Buser University of Amsterdam Leonie Gerhards University of Hamburg Joël van der Weele University of Amsterdam Pittsburgh, June 12, 2017 1 / 30 Feedback
Equilibrium Selection In Coordination Games
 Equilibrium Selection In Coordination Games Presenter: Yijia Zhao (yz4k@virginia.edu) September 7, 2005 Overview of Coordination Games A class of symmetric, simultaneous move, complete information games
Equilibrium Selection In Coordination Games Presenter: Yijia Zhao (yz4k@virginia.edu) September 7, 2005 Overview of Coordination Games A class of symmetric, simultaneous move, complete information games
Using Heuristic Models to Understand Human and Optimal Decision-Making on Bandit Problems
 Using Heuristic Models to Understand Human and Optimal Decision-Making on andit Problems Michael D. Lee (mdlee@uci.edu) Shunan Zhang (szhang@uci.edu) Miles Munro (mmunro@uci.edu) Mark Steyvers (msteyver@uci.edu)
Using Heuristic Models to Understand Human and Optimal Decision-Making on andit Problems Michael D. Lee (mdlee@uci.edu) Shunan Zhang (szhang@uci.edu) Miles Munro (mmunro@uci.edu) Mark Steyvers (msteyver@uci.edu)
Observational Learning Based on Models of Overlapping Pathways
 Observational Learning Based on Models of Overlapping Pathways Emmanouil Hourdakis and Panos Trahanias Institute of Computer Science, Foundation for Research and Technology Hellas (FORTH) Science and Technology
Observational Learning Based on Models of Overlapping Pathways Emmanouil Hourdakis and Panos Trahanias Institute of Computer Science, Foundation for Research and Technology Hellas (FORTH) Science and Technology
The weak side of informal social control Paper prepared for Conference Game Theory and Society. ETH Zürich, July 27-30, 2011
 The weak side of informal social control Paper prepared for Conference Game Theory and Society. ETH Zürich, July 27-30, 2011 Andreas Flache Department of Sociology ICS University of Groningen Collective
The weak side of informal social control Paper prepared for Conference Game Theory and Society. ETH Zürich, July 27-30, 2011 Andreas Flache Department of Sociology ICS University of Groningen Collective
Nature Neuroscience: doi: /nn Supplementary Figure 1. Trial structure for go/no-go behavior
 Supplementary Figure 1 Trial structure for go/no-go behavior a, Overall timeline of experiments. Day 1: A1 mapping, injection of AAV1-SYN-GCAMP6s, cranial window and headpost implantation. Water restriction
Supplementary Figure 1 Trial structure for go/no-go behavior a, Overall timeline of experiments. Day 1: A1 mapping, injection of AAV1-SYN-GCAMP6s, cranial window and headpost implantation. Water restriction
The Function and Organization of Lateral Prefrontal Cortex: A Test of Competing Hypotheses
 The Function and Organization of Lateral Prefrontal Cortex: A Test of Competing Hypotheses Jeremy R. Reynolds 1 *, Randall C. O Reilly 2, Jonathan D. Cohen 3, Todd S. Braver 4 1 Department of Psychology,
The Function and Organization of Lateral Prefrontal Cortex: A Test of Competing Hypotheses Jeremy R. Reynolds 1 *, Randall C. O Reilly 2, Jonathan D. Cohen 3, Todd S. Braver 4 1 Department of Psychology,
Repetition Suppression Accompanying Behavioral Priming. in Macaque Inferotemporal Cortex. David B.T. McMahon* and Carl R. Olson
 Repetition Suppression Accompanying Behavioral Priming in Macaque Inferotemporal Cortex David B.T. McMahon* and Carl R. Olson * To whom correspondence should be addressed: mcmahon@cnbc.cmu.edu Center for
Repetition Suppression Accompanying Behavioral Priming in Macaque Inferotemporal Cortex David B.T. McMahon* and Carl R. Olson * To whom correspondence should be addressed: mcmahon@cnbc.cmu.edu Center for
Describe what is meant by a placebo Contrast the double-blind procedure with the single-blind procedure Review the structure for organizing a memo
 Business Statistics The following was provided by Dr. Suzanne Delaney, and is a comprehensive review of Business Statistics. The workshop instructor will provide relevant examples during the Skills Assessment
Business Statistics The following was provided by Dr. Suzanne Delaney, and is a comprehensive review of Business Statistics. The workshop instructor will provide relevant examples during the Skills Assessment
Choice set options affect the valuation of risky prospects
 Choice set options affect the valuation of risky prospects Stian Reimers (stian.reimers@warwick.ac.uk) Neil Stewart (neil.stewart@warwick.ac.uk) Nick Chater (nick.chater@warwick.ac.uk) Department of Psychology,
Choice set options affect the valuation of risky prospects Stian Reimers (stian.reimers@warwick.ac.uk) Neil Stewart (neil.stewart@warwick.ac.uk) Nick Chater (nick.chater@warwick.ac.uk) Department of Psychology,
Feedback-Controlled Parallel Point Process Filter for Estimation of Goal-Directed Movements From Neural Signals
 IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING, VOL. 21, NO. 1, JANUARY 2013 129 Feedback-Controlled Parallel Point Process Filter for Estimation of Goal-Directed Movements From Neural
IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING, VOL. 21, NO. 1, JANUARY 2013 129 Feedback-Controlled Parallel Point Process Filter for Estimation of Goal-Directed Movements From Neural
SUPPLEMENTAL MATERIAL
 1 SUPPLEMENTAL MATERIAL Response time and signal detection time distributions SM Fig. 1. Correct response time (thick solid green curve) and error response time densities (dashed red curve), averaged across
1 SUPPLEMENTAL MATERIAL Response time and signal detection time distributions SM Fig. 1. Correct response time (thick solid green curve) and error response time densities (dashed red curve), averaged across
SUPPLEMENTARY INFORMATION
 doi:10.1038/nature10776 Supplementary Information 1: Influence of inhibition among blns on STDP of KC-bLN synapses (simulations and schematics). Unconstrained STDP drives network activity to saturation
doi:10.1038/nature10776 Supplementary Information 1: Influence of inhibition among blns on STDP of KC-bLN synapses (simulations and schematics). Unconstrained STDP drives network activity to saturation