PRINCIPLES OF EFFECTIVE MACHINE LEARNING APPLICATIONS IN REAL-WORLD EVIDENCE
|
|
|
- Myra Lambert
- 5 years ago
- Views:
Transcription

1 PRINCIPLES OF EFFECTIVE MACHINE LEARNING APPLICATIONS IN REAL-WORLD EVIDENCE Prepared and Presented by: Gorana Capkun-Niggli, PhD, Global Head of Innovation, Health Economics and Outcomes Research, Novartis, Basel, Switzerland Sreeram Ramagopalan, PhD, Director, Centre for Observational Research and Data Sciences, Bristol-Myers Squibb, London, UK Andrew Cox, PhD, Research Scientist, Evidera, London, UK David Vanness, PhD, Associate Professor, Department of Population Health Sciences, University of Wisconsin, Wisconsin, USA 2018 Evidera. All Rights Reserved. Introduction and Background 2 1
 Computing power is rapidly increasing Data Flood Greater availability of real-world structured and unstructured data Incidentally collected data Not collected for a specific")
2 Why are we hearing so much about Machine Learning? Moores Law (1965) Computing power is rapidly increasing Data Flood Greater availability of real-world structured and unstructured data Incidentally collected data Not collected for a specific question or an experiment e.g. clinical trial Messiness of Data (Sets) Statistical assumptions often violated More outliers More variables than observations 3 What is Machine Learning? Is it all new to us? Algorithmic techniques aiming at discovering data structure and relationships between variables. Statistics Machine Learning Estimation Learning Classifier Hypothesis Data point Example/Instance Regression Supervised Learning Clustering Unsupervised Learning Covariate Feature Response Label 4 2
3 Some interesting ideas: Training and testing independently; out of black box with decision trees 1 All patients 3 Build a model based on the training data set Predictive algorithm Training set 2 Split into training and test sets / independent set 4 Apply the predictive model to the test patients Training set Test set Independent set Test set Trained predictive model is tested on a test/independent set e.g. using root mean square error (RMSE) 5 Use decision trees to make results actionable: jumping out of black-box High Value Subgroup method in combination with medical expertise can optimize treatment choice for patients Classical Approach (pre-defined univariate analyses) - usual way of doing - subgroup is defined by one variable - driven by prior medical knowledge However, - existing subgroups may not be detected Data splits 1000 times Modeling samples Develop predictive models Validation samples Treatment difference curve Decision tree HVS rules Higher Value Subgroups (Machine Learning) - uses all collected data - explores complex, nonlinear structures in data - generates new hypotheses However, - subgroups may not have straightforward medical interpretation - paradigm shift towards posthoc nature of analyses Li J, Zhao L, Tian L, et al. A predictive enrichment procedure to identify potential responders to a new therapy for randomized, comparative controlled clinical studies. Biometrics. 2016;72 (3):
4 Seeking your opinion Situation A Pharma company announces their drug candidate ABC123 in a highly prevalent patient population reduces mortality by 25% compared to placebo in the confirmatory Ph III RCT. The result is consistent across all predefined subpopulations. A machine learning algorithm identifies a subpopulation with clear additional benefit A machine learning algorithm recently published in JASA identifies a subgroup of patients (e.g. moderate or severe patients who are hypertensive) for which mortality is reduced by 40%. This Higher Value Subgroup (HVS) outperforms the rest of the patients in all other relevant clinical endpoints with similar safety profile The size of the subpopulation is 30% of the total population. Business Use Only 7 Question 1: As a payer A. I would welcome these results and give access to the subpopulation only B. I would welcome these results but give access to all patients with same conditions C. I would welcome these results and offer differential access for the subpopulation D. I would ignore these findings in my decision making Business Use Only 8 4
5 Question 2: Complication Same results as before but our current medical and biological knowledge cannot explain why the selected subgroup would have increased benefit compared to the rest of the study population. As a payer A. I would welcome these results and give access to the subpopulation only B. I would welcome these results but give access to all patients with same conditions C. I would welcome these results and offer differential access for the subpopulation D. I would ignore these findings in my decision making Business Use Only 9 ML versus Traditional Statistics 10 5

6 When should machine learning be applied? 11 Looking at the original risk model development and purpose 12 6



7 Performance of the algorithms Top risk factor variables for CVD algorithms 7



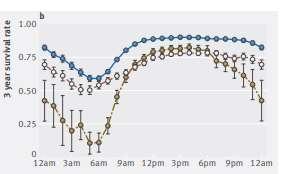
8 Cannot forget good study design. 15 Cannot forget bias and confounding. 16 8


9 These issues also apply to non-ml studies
10 Key Concepts 19 The Five Key Questions for ML Projects 1. Is ML really needed/appropriate? Is there a more simple and appropriate approach Is the choice of ML more about ML than the research question 2. Are there imbalanced classes? How rare/common are the cases being predicted? 3. Data Leakage? When information from outside the training dataset is used to create the model 4. Reporting Performance Is the reporting adequate and fair? 5. Overfitting Single holdout method is no longer acceptable 20 10
11 An Appropriate Approach? Is there a good reason to use ML? Is the dataset small with few variables? Is the interest in inference rather than prediction? Is the data sufficiently self-contained, or relatively insulated from outside influences o If in the future the problem is likely to change, then the ML model will no longer predict well Example: Google Flu Trends Prediction When the data are not generalizable? Occam s Razor Test o If you can get equal performances from two models, then you should select the more simple approach 21 Imbalanced Classes What is it?: Where the number of the class you are trying to predict is either rare or a majority 22 ML algorithms work ideally with balanced data (50% of A and 50% of B) Imbalanced classes are very common! Why is it a problem? Standard accuracy no longer reliably measures performance Example: If you are predicting a rare disease state (1% of population) then you can have great performance by just predicting all cases as No Disease ; i.e., just voting with the majority class. Therefore accuracy is very misleading How can this be addressed? Oversampling Use appropriate performance metrics (ROC curve) Use penalized methods Tree-based ensemble methods (e.g. Random Forest, Gradient Boosting) 11
12 Data Leakage Data leakage is when information from outside the training dataset is used to create the model Can cause overoptimistic prediction performance leading to invalid results How do I know if I have data leakage The performance results are too good to be true! Examples: Develop model on the training dataset test it on the training set decide if you need to change something based on the results adjust model and retest on the training set Standardize your variables across the entire dataset create your training and test datasets How can I avoid data leakage? Perform data preparation separately within each cross validation fold Create a separate validation set early on, only use it once 23 Reporting Performance Confusion matrix should be shown Predicted Status = 1 Predicted Status = 0 True Status = 1 2,221 (True Positives) 364 (False Negative) True Status = (False Positive) 1,015 (True Negatives) Gives the most comprehensive view of model performance All other performance measures are summaries of these data Summary Measures F Measure / F Statistic Accuracy True Positive Rate Out of Bag Error Rate Receiver Operator Curve (ROC) Useful for assessment of model performance Shows the trade off s for different probability thresholds 24 12

13 Overfitting What is overfitting?: Overfitting refers to a model that models the training data too well Overfitting happens when a model learns the noise in the training data to the extent that it negatively impacts the performance of the model on new data The problem is that overfitting negatively impact the models ability to generalize to new data How do I know when my model is overfitting? When you get a large difference in performance on training and testing datasets o 90% accuracy on training and only 50% accuracy on test dataset How can overfitting be avoided? Follow proper training and testing approaches K-fold cross validation Hold back a validation dataset and use it only once Avoid data leakage 25 Hyperparameters / Tuning Parameters What are Hyperparameters?: Hyperparameters are model-specific settings that can be tuned to control the behavior of a ML algorithm Example: o Random Forest number of trees, number of features o SVM C value and Kernel parameters Often overlooked! Why are they important? Can lead to better model performance, but also overfitting How do I determine the best hyperparameters for my case? Grid searches Optimization algorithms Automated tuning algorithms 26 13
14 Practical Example 27 Application: Estimating Propensity Scores for the Receipt of Allogeneic Hematopoietic Cell Transplantation (AlloHCT) in Outcomes Research Using Claims Data: A Machine Learning Approach Vanness DJ, Preussler JM, Burns LJ, Denzen EM, Leppke SN, Majhail NS, Mupfudze T, Saber W, Silver A, Steinert P, Mau LW. Biology of Blood and Marrow Transplantation Mar 1;24(3):S

, we identified patients age 20 receiving allohct (n=278) or chemotherapy only (n=570) Demographics: age, gender, region (Midwest, Northeast, South,")
![West, Unknown and combinations), and year of diagnosis Insurance: payer (commercial, Medicare, combined commercial and Medicare), product (exclusive provider organization [EPO], point of service](/docs-images/89/98246444/images/15-2.jpg "[POS], preferred provider organization [PPO] health maintenance organization [HMO], indemnity [IND], other, and combinations Baseline health status: Elixhauser Comorbidity Index, comorbidity")
15 Approach Propensity scores can be used to adjust for observed confounders that affect both selection of allohct and outcomes. Machine learning may offer advantages over logistic regression when there are many possible predictors relative to observations or when interactions and discontinuities may be important but would be difficult to pre-specify. Using Optum Clinformatics Data Mart ( ), we identified patients age 20 receiving allohct (n=278) or chemotherapy only (n=570) Demographics: age, gender, region (Midwest, Northeast, South, West, Unknown and combinations), and year of diagnosis Insurance: payer (commercial, Medicare, combined commercial and Medicare), product (exclusive provider organization [EPO], point of service [POS], preferred provider organization [PPO] health maintenance organization [HMO], indemnity [IND], other, and combinations Baseline health status: Elixhauser Comorbidity Index, comorbidity indicators (hypertension, diabetes, coagulopathy, electrolyte imbalance, anemia), and time from diagnosis to chemotherapy initiation Compared propensity scores constructed with logistic regression glm to extreme gradient boosting (R package xgboost) with stochastic resampling and feature selection, tuned to maximize 10-fold cross-validated log-likelihood. Illustration of the Boosting Algorithm 15
16 Balance Results Stabilized inverse propensityweighted datasets constructed using either logistic regression or xgboost each produced no covariates having an absolute standardized difference greater than 0.2, indicating that both approaches achieved acceptable covariate balance Distribution of Treatment Selection Errors The xgboost algorithm outperformed logistic regression in terms of accurately predicting receipt of allohct, which shows both fewer false positives and false negatives. 16
17 Investigating performance under less-than ideal circumstances. Our AlloHCT application demonstrated that boosting produced more accurate propensity scores with real-world-data, but we do not know for sure that using it result in less-biased estimates in cost. We conducted a Monte Carlo simulation using 3,000 replicated datasets where we do know the answer. Including extraneous variables that have no effect on selection or outcomes Unobservable confounders 10 T = F M X + ε 1 > 0 m= Y = T + Δ j F j + 1 Δ j β j X j + β k X k + ε 2 j=1 k=11 T Y X11-X25 X16-X25 Always Observed ε1 F1(X1) Linear F2(X2) Threshold F3(X3) Range- Discontinuous F4(X4,X5) Range- Interaction F5(X6,X7,X8) Range- Interaction F6(X9) Exponential F7(X10,X11) Signed Interaction F8(X12,X13) Multiplicative Interaction F9(X14) Squared F10(X15) Cubed F(X) Always Unobserved X1-X15 Solid: Relationship Always Present ε2 Dashed: Relationship Sometimes Present X1-X15 Elements Observable at Random 17

18 Treatment Effect Estimation Error The distributions of errors for the estimated treatment effects when using the boosted propensity score indicates substantially reduced bias at the cost of slightly higher variance when compared to the same approach with logit propensity scores Overall, the best approach appears to be to include boosted propensity scores as a regressor. Difference in RMSE between Boost and Logit (including PS as a regressor) The average pairwise difference in RMSE was lower for the boosting approach (compared to logit) when the propensity score is included as a regressor. RMSE was lower with the boosted propensity score in 81.4% of simulations. 18
19 Exploring what drove our results Used randomforest to investigate which factors varying from replication to replication led to better (or worse) relative performance of boosting compared to logit (for PS included as a regressor) Partial dependence plots show the partial relationship of each factor to comparative performance (lower values favor boosting over logit) Summary Boosting is a particularly promising method for constructing propensity scores to adjust for confounding based on observables. For confounding based on unobservables, next step will be to explore its performance in two-stage modeling with instruments Other even-more-promising approaches may await (including super-learners) Other potential applications in HEOR: High dimensional risk prediction for treatment decisions and resource allocation Risk adjustment for fair contracting and quality reporting Exploration of treatment effect heterogeneity / treatment personalization Limitations: Black box Inability to hypothesis test (though this may potentially be overcome with Targeted Machine Learning see, e.g., Van der Laan MJ, Rose S. Targeted learning: causal inference for observational and experimental data. Springer Science & Business Media; 2011 Jun 17). 19
 40 20")
20 Reviewing an Abstract 39 Reviewing an Abstract Using the 5 Key Concepts 1. Is ML really needed/appropriate? 2. Are there imbalanced classes? 3. Data Leakage? 4. Reporting Performance? 5. Overfitting? 6. Score your faith in this research on a scale of 0 to 10. Where zero is not faith at all, and 10 is complete faith and trust in the results, conclusions and methods) 40 20
 so that patients at high risk can be admitted to the hospital, while patients at low risk can be treated as")
 died from pneumonia.")
21 Is ML Really Needed/Appropriate? Objective: Predict probability of death (POD) so that patients at high risk can be admitted to the hospital, while patients at low risk can be treated as outpatients.. In total, 14,199 patients from the MCHD met all the eligibility criteria and composed the study cohort. There are 250 features describing each patient. 41 Are there Imbalanced Classes? Data: 10.86% of the patients in the dataset (1,542 patients) died from pneumonia. Methods: Random Forest was performed using a training and testing approach. The train set contains 9,847 patients and the test set has 4,352 patients (a 70%:30% train - test split)


22 Data Leakage? The train set contains 9,847 patients and the test set has 4,352 patients (a 70%:30% train - test split). Does not say anything about data preparation 43 Is Performance Reporting Adequate? Results: The AUC for the Random Forest method was Overall predictive accuracy was 0.82 and a false positive rate was
 45 Do you Trust the Research?")

23 Was There Enough Attention to Overfitting? The train set contains 9,847 patients and the test set has 4,352 patients (a 70%:30% train - test split). There are 250 features describing each patient. No information on model tuning (hyperparameters) 45 Do you Trust the Research? (Scale 0 to 10) Conclusions: Having a history if Asthma prior to admission reduced the probability of death as an outcome of the pneumonia. It may be that Asthma medication or the heightened respiratory awareness in Asthma patients leads to a better outcome in those individuals. Conclusions: Overall the performance of the Random Forest algorithm used in this work showed a high level of predictive performance, indicating it can be a useful tool to predict the probability of death from pneumonia at time of admission to hospital
Predicting Breast Cancer Survival Using Treatment and Patient Factors
 Predicting Breast Cancer Survival Using Treatment and Patient Factors William Chen wchen808@stanford.edu Henry Wang hwang9@stanford.edu 1. Introduction Breast cancer is the leading type of cancer in women
Predicting Breast Cancer Survival Using Treatment and Patient Factors William Chen wchen808@stanford.edu Henry Wang hwang9@stanford.edu 1. Introduction Breast cancer is the leading type of cancer in women
Introduction to Machine Learning. Katherine Heller Deep Learning Summer School 2018
 Introduction to Machine Learning Katherine Heller Deep Learning Summer School 2018 Outline Kinds of machine learning Linear regression Regularization Bayesian methods Logistic Regression Why we do this
Introduction to Machine Learning Katherine Heller Deep Learning Summer School 2018 Outline Kinds of machine learning Linear regression Regularization Bayesian methods Logistic Regression Why we do this
Propensity Score Methods for Estimating Causality in the Absence of Random Assignment: Applications for Child Care Policy Research
 2012 CCPRC Meeting Methodology Presession Workshop October 23, 2012, 2:00-5:00 p.m. Propensity Score Methods for Estimating Causality in the Absence of Random Assignment: Applications for Child Care Policy
2012 CCPRC Meeting Methodology Presession Workshop October 23, 2012, 2:00-5:00 p.m. Propensity Score Methods for Estimating Causality in the Absence of Random Assignment: Applications for Child Care Policy
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
Instrumental Variables Estimation: An Introduction
 Instrumental Variables Estimation: An Introduction Susan L. Ettner, Ph.D. Professor Division of General Internal Medicine and Health Services Research, UCLA The Problem The Problem Suppose you wish to
Instrumental Variables Estimation: An Introduction Susan L. Ettner, Ph.D. Professor Division of General Internal Medicine and Health Services Research, UCLA The Problem The Problem Suppose you wish to
Index. Springer International Publishing Switzerland 2017 T.J. Cleophas, A.H. Zwinderman, Modern Meta-Analysis, DOI /
 Index A Adjusted Heterogeneity without Overdispersion, 63 Agenda-driven bias, 40 Agenda-Driven Meta-Analyses, 306 307 Alternative Methods for diagnostic meta-analyses, 133 Antihypertensive effect of potassium,
Index A Adjusted Heterogeneity without Overdispersion, 63 Agenda-driven bias, 40 Agenda-Driven Meta-Analyses, 306 307 Alternative Methods for diagnostic meta-analyses, 133 Antihypertensive effect of potassium,
EPI 200C Final, June 4 th, 2009 This exam includes 24 questions.
 Greenland/Arah, Epi 200C Sp 2000 1 of 6 EPI 200C Final, June 4 th, 2009 This exam includes 24 questions. INSTRUCTIONS: Write all answers on the answer sheets supplied; PRINT YOUR NAME and STUDENT ID NUMBER
Greenland/Arah, Epi 200C Sp 2000 1 of 6 EPI 200C Final, June 4 th, 2009 This exam includes 24 questions. INSTRUCTIONS: Write all answers on the answer sheets supplied; PRINT YOUR NAME and STUDENT ID NUMBER
Selection and Combination of Markers for Prediction
 Selection and Combination of Markers for Prediction NACC Data and Methods Meeting September, 2010 Baojiang Chen, PhD Sarah Monsell, MS Xiao-Hua Andrew Zhou, PhD Overview 1. Research motivation 2. Describe
Selection and Combination of Markers for Prediction NACC Data and Methods Meeting September, 2010 Baojiang Chen, PhD Sarah Monsell, MS Xiao-Hua Andrew Zhou, PhD Overview 1. Research motivation 2. Describe
Predictive Models for Healthcare Analytics
 Predictive Models for Healthcare Analytics A Case on Retrospective Clinical Study Mengling Mornin Feng mfeng@mit.edu mornin@gmail.com 1 Learning Objectives After the lecture, students should be able to:
Predictive Models for Healthcare Analytics A Case on Retrospective Clinical Study Mengling Mornin Feng mfeng@mit.edu mornin@gmail.com 1 Learning Objectives After the lecture, students should be able to:
Biomarker adaptive designs in clinical trials
 Review Article Biomarker adaptive designs in clinical trials James J. Chen 1, Tzu-Pin Lu 1,2, Dung-Tsa Chen 3, Sue-Jane Wang 4 1 Division of Bioinformatics and Biostatistics, National Center for Toxicological
Review Article Biomarker adaptive designs in clinical trials James J. Chen 1, Tzu-Pin Lu 1,2, Dung-Tsa Chen 3, Sue-Jane Wang 4 1 Division of Bioinformatics and Biostatistics, National Center for Toxicological
TITLE: A Data-Driven Approach to Patient Risk Stratification for Acute Respiratory Distress Syndrome (ARDS)
") TITLE: A Data-Driven Approach to Patient Risk Stratification for Acute Respiratory Distress Syndrome (ARDS) AUTHORS: Tejas Prahlad INTRODUCTION Acute Respiratory Distress Syndrome (ARDS) is a condition
TITLE: A Data-Driven Approach to Patient Risk Stratification for Acute Respiratory Distress Syndrome (ARDS) AUTHORS: Tejas Prahlad INTRODUCTION Acute Respiratory Distress Syndrome (ARDS) is a condition
The Effects of Autocorrelated Noise and Biased HRF in fmri Analysis Error Rates
 The Effects of Autocorrelated Noise and Biased HRF in fmri Analysis Error Rates Ariana Anderson University of California, Los Angeles Departments of Psychiatry and Behavioral Sciences David Geffen School
The Effects of Autocorrelated Noise and Biased HRF in fmri Analysis Error Rates Ariana Anderson University of California, Los Angeles Departments of Psychiatry and Behavioral Sciences David Geffen School
Identifying Peer Influence Effects in Observational Social Network Data: An Evaluation of Propensity Score Methods
 Identifying Peer Influence Effects in Observational Social Network Data: An Evaluation of Propensity Score Methods Dean Eckles Department of Communication Stanford University dean@deaneckles.com Abstract
Identifying Peer Influence Effects in Observational Social Network Data: An Evaluation of Propensity Score Methods Dean Eckles Department of Communication Stanford University dean@deaneckles.com Abstract
Confounding by indication developments in matching, and instrumental variable methods. Richard Grieve London School of Hygiene and Tropical Medicine
 Confounding by indication developments in matching, and instrumental variable methods Richard Grieve London School of Hygiene and Tropical Medicine 1 Outline 1. Causal inference and confounding 2. Genetic
Confounding by indication developments in matching, and instrumental variable methods Richard Grieve London School of Hygiene and Tropical Medicine 1 Outline 1. Causal inference and confounding 2. Genetic
Using Ensemble-Based Methods for Directly Estimating Causal Effects: An Investigation of Tree-Based G-Computation
 Institute for Clinical Evaluative Sciences From the SelectedWorks of Peter Austin 2012 Using Ensemble-Based Methods for Directly Estimating Causal Effects: An Investigation of Tree-Based G-Computation
Institute for Clinical Evaluative Sciences From the SelectedWorks of Peter Austin 2012 Using Ensemble-Based Methods for Directly Estimating Causal Effects: An Investigation of Tree-Based G-Computation
MEA DISCUSSION PAPERS
 Inference Problems under a Special Form of Heteroskedasticity Helmut Farbmacher, Heinrich Kögel 03-2015 MEA DISCUSSION PAPERS mea Amalienstr. 33_D-80799 Munich_Phone+49 89 38602-355_Fax +49 89 38602-390_www.mea.mpisoc.mpg.de
Inference Problems under a Special Form of Heteroskedasticity Helmut Farbmacher, Heinrich Kögel 03-2015 MEA DISCUSSION PAPERS mea Amalienstr. 33_D-80799 Munich_Phone+49 89 38602-355_Fax +49 89 38602-390_www.mea.mpisoc.mpg.de
CSE 258 Lecture 2. Web Mining and Recommender Systems. Supervised learning Regression
 CSE 258 Lecture 2 Web Mining and Recommender Systems Supervised learning Regression Supervised versus unsupervised learning Learning approaches attempt to model data in order to solve a problem Unsupervised
CSE 258 Lecture 2 Web Mining and Recommender Systems Supervised learning Regression Supervised versus unsupervised learning Learning approaches attempt to model data in order to solve a problem Unsupervised
Citation for published version (APA): Ebbes, P. (2004). Latent instrumental variables: a new approach to solve for endogeneity s.n.
: Ebbes, P. (2004). Latent instrumental variables: a new approach to solve for endogeneity s.n.") University of Groningen Latent instrumental variables Ebbes, P. IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Latent instrumental variables Ebbes, P. IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
THE USE OF NONPARAMETRIC PROPENSITY SCORE ESTIMATION WITH DATA OBTAINED USING A COMPLEX SAMPLING DESIGN
 THE USE OF NONPARAMETRIC PROPENSITY SCORE ESTIMATION WITH DATA OBTAINED USING A COMPLEX SAMPLING DESIGN Ji An & Laura M. Stapleton University of Maryland, College Park May, 2016 WHAT DOES A PROPENSITY
THE USE OF NONPARAMETRIC PROPENSITY SCORE ESTIMATION WITH DATA OBTAINED USING A COMPLEX SAMPLING DESIGN Ji An & Laura M. Stapleton University of Maryland, College Park May, 2016 WHAT DOES A PROPENSITY
GSK Medicine: Study Number: Title: Rationale: Study Period: Objectives: Indication: Study Investigators/Centers: Research Methods: Data Source
 The study listed may include approved and non-approved uses, formulations or treatment regimens. The results reported in any single study may not reflect the overall results obtained on studies of a product.
The study listed may include approved and non-approved uses, formulations or treatment regimens. The results reported in any single study may not reflect the overall results obtained on studies of a product.
Selection and estimation in exploratory subgroup analyses a proposal
 Selection and estimation in exploratory subgroup analyses a proposal Gerd Rosenkranz, Novartis Pharma AG, Basel, Switzerland EMA Workshop, London, 07-Nov-2014 Purpose of this presentation Proposal for
Selection and estimation in exploratory subgroup analyses a proposal Gerd Rosenkranz, Novartis Pharma AG, Basel, Switzerland EMA Workshop, London, 07-Nov-2014 Purpose of this presentation Proposal for
BayesRandomForest: An R
 BayesRandomForest: An R implementation of Bayesian Random Forest for Regression Analysis of High-dimensional Data Oyebayo Ridwan Olaniran (rid4stat@yahoo.com) Universiti Tun Hussein Onn Malaysia Mohd Asrul
BayesRandomForest: An R implementation of Bayesian Random Forest for Regression Analysis of High-dimensional Data Oyebayo Ridwan Olaniran (rid4stat@yahoo.com) Universiti Tun Hussein Onn Malaysia Mohd Asrul
Progress in Risk Science and Causality
 Progress in Risk Science and Causality Tony Cox, tcoxdenver@aol.com AAPCA March 27, 2017 1 Vision for causal analytics Represent understanding of how the world works by an explicit causal model. Learn,
Progress in Risk Science and Causality Tony Cox, tcoxdenver@aol.com AAPCA March 27, 2017 1 Vision for causal analytics Represent understanding of how the world works by an explicit causal model. Learn,
Rise of the Machines
 Rise of the Machines Statistical machine learning for observational studies: confounding adjustment and subgroup identification Armand Chouzy, ETH (summer intern) Jason Wang, Celgene PSI conference 2018
Rise of the Machines Statistical machine learning for observational studies: confounding adjustment and subgroup identification Armand Chouzy, ETH (summer intern) Jason Wang, Celgene PSI conference 2018
Estimating population average treatment effects from experiments with noncompliance
 Estimating population average treatment effects from experiments with noncompliance Kellie Ottoboni Jason Poulos arxiv:1901.02991v1 [stat.me] 10 Jan 2019 January 11, 2019 Abstract This paper extends a
Estimating population average treatment effects from experiments with noncompliance Kellie Ottoboni Jason Poulos arxiv:1901.02991v1 [stat.me] 10 Jan 2019 January 11, 2019 Abstract This paper extends a
Roadmap for Developing and Validating Therapeutically Relevant Genomic Classifiers. Richard Simon, J Clin Oncol 23:
 Roadmap for Developing and Validating Therapeutically Relevant Genomic Classifiers. Richard Simon, J Clin Oncol 23:7332-7341 Presented by Deming Mi 7/25/2006 Major reasons for few prognostic factors to
Roadmap for Developing and Validating Therapeutically Relevant Genomic Classifiers. Richard Simon, J Clin Oncol 23:7332-7341 Presented by Deming Mi 7/25/2006 Major reasons for few prognostic factors to
Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections
 Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections New: Bias-variance decomposition, biasvariance tradeoff, overfitting, regularization, and feature selection Yi
Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections New: Bias-variance decomposition, biasvariance tradeoff, overfitting, regularization, and feature selection Yi
Identifikation von Risikofaktoren in der koronaren Herzchirurgie
 Identifikation von Risikofaktoren in der koronaren Herzchirurgie Julia Schiffner 1 Erhard Godehardt 2 Stefanie Hillebrand 1 Alexander Albert 2 Artur Lichtenberg 2 Claus Weihs 1 1 Fakultät Statistik, Technische
Identifikation von Risikofaktoren in der koronaren Herzchirurgie Julia Schiffner 1 Erhard Godehardt 2 Stefanie Hillebrand 1 Alexander Albert 2 Artur Lichtenberg 2 Claus Weihs 1 1 Fakultät Statistik, Technische
Evidence Based Medicine
 Course Goals Goals 1. Understand basic concepts of evidence based medicine (EBM) and how EBM facilitates optimal patient care. 2. Develop a basic understanding of how clinical research studies are designed
Course Goals Goals 1. Understand basic concepts of evidence based medicine (EBM) and how EBM facilitates optimal patient care. 2. Develop a basic understanding of how clinical research studies are designed
MODEL SELECTION STRATEGIES. Tony Panzarella
 MODEL SELECTION STRATEGIES Tony Panzarella Lab Course March 20, 2014 2 Preamble Although focus will be on time-to-event data the same principles apply to other outcome data Lab Course March 20, 2014 3
MODEL SELECTION STRATEGIES Tony Panzarella Lab Course March 20, 2014 2 Preamble Although focus will be on time-to-event data the same principles apply to other outcome data Lab Course March 20, 2014 3
PubH 7405: REGRESSION ANALYSIS. Propensity Score
 PubH 7405: REGRESSION ANALYSIS Propensity Score INTRODUCTION: There is a growing interest in using observational (or nonrandomized) studies to estimate the effects of treatments on outcomes. In observational
PubH 7405: REGRESSION ANALYSIS Propensity Score INTRODUCTION: There is a growing interest in using observational (or nonrandomized) studies to estimate the effects of treatments on outcomes. In observational
Statistics 202: Data Mining. c Jonathan Taylor. Final review Based in part on slides from textbook, slides of Susan Holmes.
 Final review Based in part on slides from textbook, slides of Susan Holmes December 5, 2012 1 / 1 Final review Overview Before Midterm General goals of data mining. Datatypes. Preprocessing & dimension
Final review Based in part on slides from textbook, slides of Susan Holmes December 5, 2012 1 / 1 Final review Overview Before Midterm General goals of data mining. Datatypes. Preprocessing & dimension
11/24/2017. Do not imply a cause-and-effect relationship
 Correlational research is used to describe the relationship between two or more naturally occurring variables. Is age related to political conservativism? Are highly extraverted people less afraid of rejection
Correlational research is used to describe the relationship between two or more naturally occurring variables. Is age related to political conservativism? Are highly extraverted people less afraid of rejection
Mostly Harmless Simulations? On the Internal Validity of Empirical Monte Carlo Studies
 Mostly Harmless Simulations? On the Internal Validity of Empirical Monte Carlo Studies Arun Advani and Tymon Sªoczy«ski 13 November 2013 Background When interested in small-sample properties of estimators,
Mostly Harmless Simulations? On the Internal Validity of Empirical Monte Carlo Studies Arun Advani and Tymon Sªoczy«ski 13 November 2013 Background When interested in small-sample properties of estimators,
Vocabulary. Bias. Blinding. Block. Cluster sample
 Bias Blinding Block Census Cluster sample Confounding Control group Convenience sample Designs Experiment Experimental units Factor Level Any systematic failure of a sampling method to represent its population
Bias Blinding Block Census Cluster sample Confounding Control group Convenience sample Designs Experiment Experimental units Factor Level Any systematic failure of a sampling method to represent its population
Lec 02: Estimation & Hypothesis Testing in Animal Ecology
 Lec 02: Estimation & Hypothesis Testing in Animal Ecology Parameter Estimation from Samples Samples We typically observe systems incompletely, i.e., we sample according to a designed protocol. We then
Lec 02: Estimation & Hypothesis Testing in Animal Ecology Parameter Estimation from Samples Samples We typically observe systems incompletely, i.e., we sample according to a designed protocol. We then
Propensity scores and causal inference using machine learning methods
 Propensity scores and causal inference using machine learning methods Austin Nichols (Abt) & Linden McBride (Cornell) July 27, 2017 Stata Conference Baltimore, MD Overview Machine learning methods dominant
Propensity scores and causal inference using machine learning methods Austin Nichols (Abt) & Linden McBride (Cornell) July 27, 2017 Stata Conference Baltimore, MD Overview Machine learning methods dominant
Methods for Predicting Type 2 Diabetes
 Methods for Predicting Type 2 Diabetes CS229 Final Project December 2015 Duyun Chen 1, Yaxuan Yang 2, and Junrui Zhang 3 Abstract Diabetes Mellitus type 2 (T2DM) is the most common form of diabetes [WHO
Methods for Predicting Type 2 Diabetes CS229 Final Project December 2015 Duyun Chen 1, Yaxuan Yang 2, and Junrui Zhang 3 Abstract Diabetes Mellitus type 2 (T2DM) is the most common form of diabetes [WHO
Methods for Addressing Selection Bias in Observational Studies
 Methods for Addressing Selection Bias in Observational Studies Susan L. Ettner, Ph.D. Professor Division of General Internal Medicine and Health Services Research, UCLA What is Selection Bias? In the regression
Methods for Addressing Selection Bias in Observational Studies Susan L. Ettner, Ph.D. Professor Division of General Internal Medicine and Health Services Research, UCLA What is Selection Bias? In the regression
Machine learning II. Juhan Ernits ITI8600
 Machine learning II Juhan Ernits ITI8600 Hand written digit recognition 64 Example 2: Face recogition Classification, regression or unsupervised? How many classes? Example 2: Face recognition Classification,
Machine learning II Juhan Ernits ITI8600 Hand written digit recognition 64 Example 2: Face recogition Classification, regression or unsupervised? How many classes? Example 2: Face recognition Classification,
Generalized additive model for disease risk prediction
 Generalized additive model for disease risk prediction Guodong Chen Chu Kochen Honors College, Zhejiang University Channing Division of Network Medicine, BWH & HMS Advised by: Prof. Yang-Yu Liu 1 Is it
Generalized additive model for disease risk prediction Guodong Chen Chu Kochen Honors College, Zhejiang University Channing Division of Network Medicine, BWH & HMS Advised by: Prof. Yang-Yu Liu 1 Is it
Data Analysis Using Regression and Multilevel/Hierarchical Models
 Data Analysis Using Regression and Multilevel/Hierarchical Models ANDREW GELMAN Columbia University JENNIFER HILL Columbia University CAMBRIDGE UNIVERSITY PRESS Contents List of examples V a 9 e xv " Preface
Data Analysis Using Regression and Multilevel/Hierarchical Models ANDREW GELMAN Columbia University JENNIFER HILL Columbia University CAMBRIDGE UNIVERSITY PRESS Contents List of examples V a 9 e xv " Preface
11/18/2013. Correlational Research. Correlational Designs. Why Use a Correlational Design? CORRELATIONAL RESEARCH STUDIES
 Correlational Research Correlational Designs Correlational research is used to describe the relationship between two or more naturally occurring variables. Is age related to political conservativism? Are
Correlational Research Correlational Designs Correlational research is used to describe the relationship between two or more naturally occurring variables. Is age related to political conservativism? Are
Chapter 17 Sensitivity Analysis and Model Validation
 Chapter 17 Sensitivity Analysis and Model Validation Justin D. Salciccioli, Yves Crutain, Matthieu Komorowski and Dominic C. Marshall Learning Objectives Appreciate that all models possess inherent limitations
Chapter 17 Sensitivity Analysis and Model Validation Justin D. Salciccioli, Yves Crutain, Matthieu Komorowski and Dominic C. Marshall Learning Objectives Appreciate that all models possess inherent limitations
Computer Age Statistical Inference. Algorithms, Evidence, and Data Science. BRADLEY EFRON Stanford University, California
 Computer Age Statistical Inference Algorithms, Evidence, and Data Science BRADLEY EFRON Stanford University, California TREVOR HASTIE Stanford University, California ggf CAMBRIDGE UNIVERSITY PRESS Preface
Computer Age Statistical Inference Algorithms, Evidence, and Data Science BRADLEY EFRON Stanford University, California TREVOR HASTIE Stanford University, California ggf CAMBRIDGE UNIVERSITY PRESS Preface
Glossary From Running Randomized Evaluations: A Practical Guide, by Rachel Glennerster and Kudzai Takavarasha
 Glossary From Running Randomized Evaluations: A Practical Guide, by Rachel Glennerster and Kudzai Takavarasha attrition: When data are missing because we are unable to measure the outcomes of some of the
Glossary From Running Randomized Evaluations: A Practical Guide, by Rachel Glennerster and Kudzai Takavarasha attrition: When data are missing because we are unable to measure the outcomes of some of the
Lecture 21. RNA-seq: Advanced analysis
 Lecture 21 RNA-seq: Advanced analysis Experimental design Introduction An experiment is a process or study that results in the collection of data. Statistical experiments are conducted in situations in
Lecture 21 RNA-seq: Advanced analysis Experimental design Introduction An experiment is a process or study that results in the collection of data. Statistical experiments are conducted in situations in
J2.6 Imputation of missing data with nonlinear relationships
 Sixth Conference on Artificial Intelligence Applications to Environmental Science 88th AMS Annual Meeting, New Orleans, LA 20-24 January 2008 J2.6 Imputation of missing with nonlinear relationships Michael
Sixth Conference on Artificial Intelligence Applications to Environmental Science 88th AMS Annual Meeting, New Orleans, LA 20-24 January 2008 J2.6 Imputation of missing with nonlinear relationships Michael
Summary of main challenges and future directions
 Summary of main challenges and future directions Martin Schumacher Institute of Medical Biometry and Medical Informatics, University Medical Center, Freiburg Workshop October 2008 - F1 Outline Some historical
Summary of main challenges and future directions Martin Schumacher Institute of Medical Biometry and Medical Informatics, University Medical Center, Freiburg Workshop October 2008 - F1 Outline Some historical
Derivative-Free Optimization for Hyper-Parameter Tuning in Machine Learning Problems
 Derivative-Free Optimization for Hyper-Parameter Tuning in Machine Learning Problems Hiva Ghanbari Jointed work with Prof. Katya Scheinberg Industrial and Systems Engineering Department Lehigh University
Derivative-Free Optimization for Hyper-Parameter Tuning in Machine Learning Problems Hiva Ghanbari Jointed work with Prof. Katya Scheinberg Industrial and Systems Engineering Department Lehigh University
Discussion Meeting for MCP-Mod Qualification Opinion Request. Novartis 10 July 2013 EMA, London, UK
 Discussion Meeting for MCP-Mod Qualification Opinion Request Novartis 10 July 2013 EMA, London, UK Attendees Face to face: Dr. Frank Bretz Global Statistical Methodology Head, Novartis Dr. Björn Bornkamp
Discussion Meeting for MCP-Mod Qualification Opinion Request Novartis 10 July 2013 EMA, London, UK Attendees Face to face: Dr. Frank Bretz Global Statistical Methodology Head, Novartis Dr. Björn Bornkamp
Response to Mease and Wyner, Evidence Contrary to the Statistical View of Boosting, JMLR 9:1 26, 2008
 Journal of Machine Learning Research 9 (2008) 59-64 Published 1/08 Response to Mease and Wyner, Evidence Contrary to the Statistical View of Boosting, JMLR 9:1 26, 2008 Jerome Friedman Trevor Hastie Robert
Journal of Machine Learning Research 9 (2008) 59-64 Published 1/08 Response to Mease and Wyner, Evidence Contrary to the Statistical View of Boosting, JMLR 9:1 26, 2008 Jerome Friedman Trevor Hastie Robert
National Surgical Adjuvant Breast and Bowel Project (NSABP) Foundation Annual Progress Report: 2008 Formula Grant
 Foundation Annual Progress Report: 2008 Formula Grant") National Surgical Adjuvant Breast and Bowel Project (NSABP) Foundation Annual Progress Report: 2008 Formula Grant Reporting Period July 1, 2011 December 31, 2011 Formula Grant Overview The National Surgical
National Surgical Adjuvant Breast and Bowel Project (NSABP) Foundation Annual Progress Report: 2008 Formula Grant Reporting Period July 1, 2011 December 31, 2011 Formula Grant Overview The National Surgical
Supplementary Online Content
 1 Supplementary Online Content Friedman DJ, Piccini JP, Wang T, et al. Association between left atrial appendage occlusion and readmission for thromboembolism among patients with atrial fibrillation undergoing
1 Supplementary Online Content Friedman DJ, Piccini JP, Wang T, et al. Association between left atrial appendage occlusion and readmission for thromboembolism among patients with atrial fibrillation undergoing
State-of-the-art Strategies for Addressing Selection Bias When Comparing Two or More Treatment Groups. Beth Ann Griffin Daniel McCaffrey
 State-of-the-art Strategies for Addressing Selection Bias When Comparing Two or More Treatment Groups Beth Ann Griffin Daniel McCaffrey 1 Acknowledgements This work has been generously supported by NIDA
State-of-the-art Strategies for Addressing Selection Bias When Comparing Two or More Treatment Groups Beth Ann Griffin Daniel McCaffrey 1 Acknowledgements This work has been generously supported by NIDA
Predictive Model for Detection of Colorectal Cancer in Primary Care by Analysis of Complete Blood Counts
 Predictive Model for Detection of Colorectal Cancer in Primary Care by Analysis of Complete Blood Counts Kinar, Y., Kalkstein, N., Akiva, P., Levin, B., Half, E.E., Goldshtein, I., Chodick, G. and Shalev,
Predictive Model for Detection of Colorectal Cancer in Primary Care by Analysis of Complete Blood Counts Kinar, Y., Kalkstein, N., Akiva, P., Levin, B., Half, E.E., Goldshtein, I., Chodick, G. and Shalev,
4. Model evaluation & selection
 Foundations of Machine Learning CentraleSupélec Fall 2017 4. Model evaluation & selection Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr
Foundations of Machine Learning CentraleSupélec Fall 2017 4. Model evaluation & selection Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr
The Good News. More storage capacity allows information to be saved Economic and social forces creating more aggregation of data
 The Good News Capacity to gather medically significant data growing quickly Better instrumentation (e.g., MRI machines, ambulatory monitors, cameras) generates more information/patient More storage capacity
The Good News Capacity to gather medically significant data growing quickly Better instrumentation (e.g., MRI machines, ambulatory monitors, cameras) generates more information/patient More storage capacity
3. Model evaluation & selection
 Foundations of Machine Learning CentraleSupélec Fall 2016 3. Model evaluation & selection Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr
Foundations of Machine Learning CentraleSupélec Fall 2016 3. Model evaluation & selection Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr
Applying Machine Learning Methods in Medical Research Studies
 Applying Machine Learning Methods in Medical Research Studies Daniel Stahl Department of Biostatistics and Health Informatics Psychiatry, Psychology & Neuroscience (IoPPN), King s College London daniel.r.stahl@kcl.ac.uk
Applying Machine Learning Methods in Medical Research Studies Daniel Stahl Department of Biostatistics and Health Informatics Psychiatry, Psychology & Neuroscience (IoPPN), King s College London daniel.r.stahl@kcl.ac.uk
Feature selection methods for early predictive biomarker discovery using untargeted metabolomic data
 Feature selection methods for early predictive biomarker discovery using untargeted metabolomic data Dhouha Grissa, Mélanie Pétéra, Marion Brandolini, Amedeo Napoli, Blandine Comte and Estelle Pujos-Guillot
Feature selection methods for early predictive biomarker discovery using untargeted metabolomic data Dhouha Grissa, Mélanie Pétéra, Marion Brandolini, Amedeo Napoli, Blandine Comte and Estelle Pujos-Guillot
Weight Adjustment Methods using Multilevel Propensity Models and Random Forests
 Weight Adjustment Methods using Multilevel Propensity Models and Random Forests Ronaldo Iachan 1, Maria Prosviryakova 1, Kurt Peters 2, Lauren Restivo 1 1 ICF International, 530 Gaither Road Suite 500,
Weight Adjustment Methods using Multilevel Propensity Models and Random Forests Ronaldo Iachan 1, Maria Prosviryakova 1, Kurt Peters 2, Lauren Restivo 1 1 ICF International, 530 Gaither Road Suite 500,
Research Methods in Forest Sciences: Learning Diary. Yoko Lu December Research process
 Research Methods in Forest Sciences: Learning Diary Yoko Lu 285122 9 December 2016 1. Research process It is important to pursue and apply knowledge and understand the world under both natural and social
Research Methods in Forest Sciences: Learning Diary Yoko Lu 285122 9 December 2016 1. Research process It is important to pursue and apply knowledge and understand the world under both natural and social
BREAST CANCER EPIDEMIOLOGY MODEL:
 BREAST CANCER EPIDEMIOLOGY MODEL: Calibrating Simulations via Optimization Michael C. Ferris, Geng Deng, Dennis G. Fryback, Vipat Kuruchittham University of Wisconsin 1 University of Wisconsin Breast Cancer
BREAST CANCER EPIDEMIOLOGY MODEL: Calibrating Simulations via Optimization Michael C. Ferris, Geng Deng, Dennis G. Fryback, Vipat Kuruchittham University of Wisconsin 1 University of Wisconsin Breast Cancer
MS&E 226: Small Data
 MS&E 226: Small Data Lecture 10: Introduction to inference (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 17 What is inference? 2 / 17 Where did our data come from? Recall our sample is: Y, the vector
MS&E 226: Small Data Lecture 10: Introduction to inference (v2) Ramesh Johari ramesh.johari@stanford.edu 1 / 17 What is inference? 2 / 17 Where did our data come from? Recall our sample is: Y, the vector
Introduction to Computational Neuroscience
 Introduction to Computational Neuroscience Lecture 5: Data analysis II Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis II 6 Single
Introduction to Computational Neuroscience Lecture 5: Data analysis II Lesson Title 1 Introduction 2 Structure and Function of the NS 3 Windows to the Brain 4 Data analysis 5 Data analysis II 6 Single
Panel: Machine Learning in Surgery and Cancer
 Panel: Machine Learning in Surgery and Cancer Professor Dimitris Bertsimas, SM 87, PhD 88, Boeing Leaders for Global Operations Professor of Management; Professor of Operations Research; Co-Director, Operations
Panel: Machine Learning in Surgery and Cancer Professor Dimitris Bertsimas, SM 87, PhD 88, Boeing Leaders for Global Operations Professor of Management; Professor of Operations Research; Co-Director, Operations
Lecture Outline. Biost 517 Applied Biostatistics I. Purpose of Descriptive Statistics. Purpose of Descriptive Statistics
 Biost 517 Applied Biostatistics I Scott S. Emerson, M.D., Ph.D. Professor of Biostatistics University of Washington Lecture 3: Overview of Descriptive Statistics October 3, 2005 Lecture Outline Purpose
Biost 517 Applied Biostatistics I Scott S. Emerson, M.D., Ph.D. Professor of Biostatistics University of Washington Lecture 3: Overview of Descriptive Statistics October 3, 2005 Lecture Outline Purpose
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Midterm, 2016
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Midterm, 2016 Exam policy: This exam allows one one-page, two-sided cheat sheet; No other materials. Time: 80 minutes. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Midterm, 2016 Exam policy: This exam allows one one-page, two-sided cheat sheet; No other materials. Time: 80 minutes. Be sure to write your name and
Fundamental Clinical Trial Design
 Design, Monitoring, and Analysis of Clinical Trials Session 1 Overview and Introduction Overview Scott S. Emerson, M.D., Ph.D. Professor of Biostatistics, University of Washington February 17-19, 2003
Design, Monitoring, and Analysis of Clinical Trials Session 1 Overview and Introduction Overview Scott S. Emerson, M.D., Ph.D. Professor of Biostatistics, University of Washington February 17-19, 2003
Assigning B cell Maturity in Pediatric Leukemia Gabi Fragiadakis 1, Jamie Irvine 2 1 Microbiology and Immunology, 2 Computer Science
 Assigning B cell Maturity in Pediatric Leukemia Gabi Fragiadakis 1, Jamie Irvine 2 1 Microbiology and Immunology, 2 Computer Science Abstract One method for analyzing pediatric B cell leukemia is to categorize
Assigning B cell Maturity in Pediatric Leukemia Gabi Fragiadakis 1, Jamie Irvine 2 1 Microbiology and Immunology, 2 Computer Science Abstract One method for analyzing pediatric B cell leukemia is to categorize
Chapter 21 Multilevel Propensity Score Methods for Estimating Causal Effects: A Latent Class Modeling Strategy
 Chapter 21 Multilevel Propensity Score Methods for Estimating Causal Effects: A Latent Class Modeling Strategy Jee-Seon Kim and Peter M. Steiner Abstract Despite their appeal, randomized experiments cannot
Chapter 21 Multilevel Propensity Score Methods for Estimating Causal Effects: A Latent Class Modeling Strategy Jee-Seon Kim and Peter M. Steiner Abstract Despite their appeal, randomized experiments cannot
Estimating Likelihood of Having a BRCA Gene Mutation Based on Family History of Cancers and Recommending Optimized Cancer Preventive Actions
 University of South Florida Scholar Commons Graduate Theses and Dissertations Graduate School 11-12-2015 Estimating Likelihood of Having a BRCA Gene Mutation Based on Family History of Cancers and Recommending
University of South Florida Scholar Commons Graduate Theses and Dissertations Graduate School 11-12-2015 Estimating Likelihood of Having a BRCA Gene Mutation Based on Family History of Cancers and Recommending
How should the propensity score be estimated when some confounders are partially observed?
 How should the propensity score be estimated when some confounders are partially observed? Clémence Leyrat 1, James Carpenter 1,2, Elizabeth Williamson 1,3, Helen Blake 1 1 Department of Medical statistics,
How should the propensity score be estimated when some confounders are partially observed? Clémence Leyrat 1, James Carpenter 1,2, Elizabeth Williamson 1,3, Helen Blake 1 1 Department of Medical statistics,
Does Machine Learning. In a Learning Health System?
 Does Machine Learning Have a Place In a Learning Health System? Grand Rounds: Rethinking Clinical Research Friday, December 15, 2017 Michael J. Pencina, PhD Professor of Biostatistics and Bioinformatics,
Does Machine Learning Have a Place In a Learning Health System? Grand Rounds: Rethinking Clinical Research Friday, December 15, 2017 Michael J. Pencina, PhD Professor of Biostatistics and Bioinformatics,
TRIPLL Webinar: Propensity score methods in chronic pain research
 TRIPLL Webinar: Propensity score methods in chronic pain research Felix Thoemmes, PhD Support provided by IES grant Matching Strategies for Observational Studies with Multilevel Data in Educational Research
TRIPLL Webinar: Propensity score methods in chronic pain research Felix Thoemmes, PhD Support provided by IES grant Matching Strategies for Observational Studies with Multilevel Data in Educational Research
Propensity score weighting with multilevel data
 Research Article Received 9 January 2012, Accepted 25 February 2013 Published online in Wiley Online Library (wileyonlinelibrary.com) DOI: 10.1002/sim.5786 Propensity score weighting with multilevel data
Research Article Received 9 January 2012, Accepted 25 February 2013 Published online in Wiley Online Library (wileyonlinelibrary.com) DOI: 10.1002/sim.5786 Propensity score weighting with multilevel data
In this module I provide a few illustrations of options within lavaan for handling various situations.
 In this module I provide a few illustrations of options within lavaan for handling various situations. An appropriate citation for this material is Yves Rosseel (2012). lavaan: An R Package for Structural
In this module I provide a few illustrations of options within lavaan for handling various situations. An appropriate citation for this material is Yves Rosseel (2012). lavaan: An R Package for Structural
Anirudh Kamath 1, Raj Ramnani 2, Jay Shenoy 3, Aditya Singh 4, and Ayush Vyas 5 arxiv: v2 [stat.ml] 15 Aug 2017.
![Anirudh Kamath 1, Raj Ramnani 2, Jay Shenoy 3, Aditya Singh 4, and Ayush Vyas 5 arxiv: v2 [stat.ml] 15 Aug 2017.](/thumbs/83/88335981.jpg "Anirudh Kamath 1, Raj Ramnani 2, Jay Shenoy 3, Aditya Singh 4, and Ayush Vyas 5 arxiv: v2 [stat.ml] 15 Aug 2017.") Optimization of Ensemble Supervised Learning Algorithms for Increased Sensitivity, Specificity, and AUC of Population-Based Colorectal Cancer Screenings Anirudh Kamath 1, Raj Ramnani 2, Jay Shenoy 3, Aditya
Optimization of Ensemble Supervised Learning Algorithms for Increased Sensitivity, Specificity, and AUC of Population-Based Colorectal Cancer Screenings Anirudh Kamath 1, Raj Ramnani 2, Jay Shenoy 3, Aditya
Lecture Outline. Biost 590: Statistical Consulting. Stages of Scientific Studies. Scientific Method
 Biost 590: Statistical Consulting Statistical Classification of Scientific Studies; Approach to Consulting Lecture Outline Statistical Classification of Scientific Studies Statistical Tasks Approach to
Biost 590: Statistical Consulting Statistical Classification of Scientific Studies; Approach to Consulting Lecture Outline Statistical Classification of Scientific Studies Statistical Tasks Approach to
Deep Learning Analytics for Predicting Prognosis of Acute Myeloid Leukemia with Cytogenetics, Age, and Mutations
 Deep Learning Analytics for Predicting Prognosis of Acute Myeloid Leukemia with Cytogenetics, Age, and Mutations Andy Nguyen, M.D., M.S. Medical Director, Hematopathology, Hematology and Coagulation Laboratory,
Deep Learning Analytics for Predicting Prognosis of Acute Myeloid Leukemia with Cytogenetics, Age, and Mutations Andy Nguyen, M.D., M.S. Medical Director, Hematopathology, Hematology and Coagulation Laboratory,
Lecture II: Difference in Difference. Causality is difficult to Show from cross
 Review Lecture II: Regression Discontinuity and Difference in Difference From Lecture I Causality is difficult to Show from cross sectional observational studies What caused what? X caused Y, Y caused
Review Lecture II: Regression Discontinuity and Difference in Difference From Lecture I Causality is difficult to Show from cross sectional observational studies What caused what? X caused Y, Y caused
CLASSIFICATION OF BREAST CANCER INTO BENIGN AND MALIGNANT USING SUPPORT VECTOR MACHINES
 CLASSIFICATION OF BREAST CANCER INTO BENIGN AND MALIGNANT USING SUPPORT VECTOR MACHINES K.S.NS. Gopala Krishna 1, B.L.S. Suraj 2, M. Trupthi 3 1,2 Student, 3 Assistant Professor, Department of Information
CLASSIFICATION OF BREAST CANCER INTO BENIGN AND MALIGNANT USING SUPPORT VECTOR MACHINES K.S.NS. Gopala Krishna 1, B.L.S. Suraj 2, M. Trupthi 3 1,2 Student, 3 Assistant Professor, Department of Information
Yeast Cells Classification Machine Learning Approach to Discriminate Saccharomyces cerevisiae Yeast Cells Using Sophisticated Image Features.
 Yeast Cells Classification Machine Learning Approach to Discriminate Saccharomyces cerevisiae Yeast Cells Using Sophisticated Image Features. Mohamed Tleis Supervisor: Fons J. Verbeek Leiden University
Yeast Cells Classification Machine Learning Approach to Discriminate Saccharomyces cerevisiae Yeast Cells Using Sophisticated Image Features. Mohamed Tleis Supervisor: Fons J. Verbeek Leiden University
Copyright 2016 Aftab Hassan
 Copyright 2016 Aftab Hassan Predictive Analytics and Decision Support for Heart Failure patients Aftab Hassan A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science
Copyright 2016 Aftab Hassan Predictive Analytics and Decision Support for Heart Failure patients Aftab Hassan A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science
Predicting clinical outcomes in neuroblastoma with genomic data integration
 Predicting clinical outcomes in neuroblastoma with genomic data integration Ilyes Baali, 1 Alp Emre Acar 1, Tunde Aderinwale 2, Saber HafezQorani 3, Hilal Kazan 4 1 Department of Electric-Electronics Engineering,
Predicting clinical outcomes in neuroblastoma with genomic data integration Ilyes Baali, 1 Alp Emre Acar 1, Tunde Aderinwale 2, Saber HafezQorani 3, Hilal Kazan 4 1 Department of Electric-Electronics Engineering,
Recent developments for combining evidence within evidence streams: bias-adjusted meta-analysis
 EFSA/EBTC Colloquium, 25 October 2017 Recent developments for combining evidence within evidence streams: bias-adjusted meta-analysis Julian Higgins University of Bristol 1 Introduction to concepts Standard
EFSA/EBTC Colloquium, 25 October 2017 Recent developments for combining evidence within evidence streams: bias-adjusted meta-analysis Julian Higgins University of Bristol 1 Introduction to concepts Standard
Anale. Seria Informatică. Vol. XVI fasc Annals. Computer Science Series. 16 th Tome 1 st Fasc. 2018
 HANDLING MULTICOLLINEARITY; A COMPARATIVE STUDY OF THE PREDICTION PERFORMANCE OF SOME METHODS BASED ON SOME PROBABILITY DISTRIBUTIONS Zakari Y., Yau S. A., Usman U. Department of Mathematics, Usmanu Danfodiyo
HANDLING MULTICOLLINEARITY; A COMPARATIVE STUDY OF THE PREDICTION PERFORMANCE OF SOME METHODS BASED ON SOME PROBABILITY DISTRIBUTIONS Zakari Y., Yau S. A., Usman U. Department of Mathematics, Usmanu Danfodiyo
Risk of serious infections associated with use of immunosuppressive agents in pregnant women with autoimmune inflammatory conditions: cohor t study
 Risk of serious infections associated with use of immunosuppressive agents in pregnant women with autoimmune inflammatory conditions: cohor t study BMJ 2017; 356 doi: https://doi.org/10.1136/bmj.j895 (Published
Risk of serious infections associated with use of immunosuppressive agents in pregnant women with autoimmune inflammatory conditions: cohor t study BMJ 2017; 356 doi: https://doi.org/10.1136/bmj.j895 (Published
cloglog link function to transform the (population) hazard probability into a continuous
 hazard probability into a continuous") Supplementary material. Discrete time event history analysis Hazard model details. In our discrete time event history analysis, we used the asymmetric cloglog link function to transform the (population)
Supplementary material. Discrete time event history analysis Hazard model details. In our discrete time event history analysis, we used the asymmetric cloglog link function to transform the (population)
Unit 1 Exploring and Understanding Data
 Unit 1 Exploring and Understanding Data Area Principle Bar Chart Boxplot Conditional Distribution Dotplot Empirical Rule Five Number Summary Frequency Distribution Frequency Polygon Histogram Interquartile
Unit 1 Exploring and Understanding Data Area Principle Bar Chart Boxplot Conditional Distribution Dotplot Empirical Rule Five Number Summary Frequency Distribution Frequency Polygon Histogram Interquartile
Model reconnaissance: discretization, naive Bayes and maximum-entropy. Sanne de Roever/ spdrnl
 Model reconnaissance: discretization, naive Bayes and maximum-entropy Sanne de Roever/ spdrnl December, 2013 Description of the dataset There are two datasets: a training and a test dataset of respectively
Model reconnaissance: discretization, naive Bayes and maximum-entropy Sanne de Roever/ spdrnl December, 2013 Description of the dataset There are two datasets: a training and a test dataset of respectively
School of Population and Public Health SPPH 503 Epidemiologic methods II January to April 2019
 School of Population and Public Health SPPH 503 Epidemiologic methods II January to April 2019 Time: Tuesday, 1330 1630 Location: School of Population and Public Health, UBC Course description Students
School of Population and Public Health SPPH 503 Epidemiologic methods II January to April 2019 Time: Tuesday, 1330 1630 Location: School of Population and Public Health, UBC Course description Students
Colon cancer subtypes from gene expression data
 Colon cancer subtypes from gene expression data Nathan Cunningham Giuseppe Di Benedetto Sherman Ip Leon Law Module 6: Applied Statistics 26th February 2016 Aim Replicate findings of Felipe De Sousa et
Colon cancer subtypes from gene expression data Nathan Cunningham Giuseppe Di Benedetto Sherman Ip Leon Law Module 6: Applied Statistics 26th February 2016 Aim Replicate findings of Felipe De Sousa et
School Autonomy and Regression Discontinuity Imbalance
 School Autonomy and Regression Discontinuity Imbalance Todd Kawakita 1 and Colin Sullivan 2 Abstract In this research note, we replicate and assess Damon Clark s (2009) analysis of school autonomy reform
School Autonomy and Regression Discontinuity Imbalance Todd Kawakita 1 and Colin Sullivan 2 Abstract In this research note, we replicate and assess Damon Clark s (2009) analysis of school autonomy reform
A Practical Guide to Getting Started with Propensity Scores
 Paper 689-2017 A Practical Guide to Getting Started with Propensity Scores Thomas Gant, Keith Crowland Data & Information Management Enhancement (DIME) Kaiser Permanente ABSTRACT This paper gives tools
Paper 689-2017 A Practical Guide to Getting Started with Propensity Scores Thomas Gant, Keith Crowland Data & Information Management Enhancement (DIME) Kaiser Permanente ABSTRACT This paper gives tools
An Empirical Assessment of Bivariate Methods for Meta-analysis of Test Accuracy
 Number XX An Empirical Assessment of Bivariate Methods for Meta-analysis of Test Accuracy Prepared for: Agency for Healthcare Research and Quality U.S. Department of Health and Human Services 54 Gaither
Number XX An Empirical Assessment of Bivariate Methods for Meta-analysis of Test Accuracy Prepared for: Agency for Healthcare Research and Quality U.S. Department of Health and Human Services 54 Gaither
An Improved Algorithm To Predict Recurrence Of Breast Cancer
 An Improved Algorithm To Predict Recurrence Of Breast Cancer Umang Agrawal 1, Ass. Prof. Ishan K Rajani 2 1 M.E Computer Engineer, Silver Oak College of Engineering & Technology, Gujarat, India. 2 Assistant
An Improved Algorithm To Predict Recurrence Of Breast Cancer Umang Agrawal 1, Ass. Prof. Ishan K Rajani 2 1 M.E Computer Engineer, Silver Oak College of Engineering & Technology, Gujarat, India. 2 Assistant
Systematic Reviews and Meta- Analysis in Kidney Transplantation
 Systematic Reviews and Meta- Analysis in Kidney Transplantation Greg Knoll MD MSc Associate Professor of Medicine Medical Director, Kidney Transplantation University of Ottawa and The Ottawa Hospital KRESCENT
Systematic Reviews and Meta- Analysis in Kidney Transplantation Greg Knoll MD MSc Associate Professor of Medicine Medical Director, Kidney Transplantation University of Ottawa and The Ottawa Hospital KRESCENT