Supplementary material: Backtracking ScSPM Image Classifier for Weakly Supervised Top-down Saliency
|
|
|
- Cuthbert Copeland
- 5 years ago
- Views:
Transcription




)")


![plant Yang and Yang [36] 15.2 39 9.4 5.7 3.](/docs-images/88/115901640/images/1-8.jpg "4 22 30.5 15.8 5.7 8 11.1 12.8 10.9 23.")



 on")



1 Supplementary material: Backtracking ScSPM Image Classifier for Weakly Supervised Top-down Saliency Hisham Cholakkal Jubin Johnson Deepu Rajan Nanyang Technological University Singapore {hisham002, jubin001, 1. Quantitaive Comparison of proposed weakly supervised approach vs fully supervised top-down saliency approaches-pascal VOC-07 ( patch-level precision rates at EER (%)) PASCAL VOC Aeropla Bicycle Bird Boat Bottle Bus Car Cat Chair Cow Dining ne table Dog Horse Motor bike Person Potted Sheep Sofa Train plant Yang and Yang [36] LCCSC [5] Proposed TV Monito r Mean Figure 1. Patch-level precision rates at EER ( %) on PASCAL VOC-07 dataset. 2. Quantitative comparison of pixel labeling accuracy with fully supervised object class-segmentation methods in PASCAL VOC-07 Table 1. Pixel classification accuracy of individual classes as% of correctly labeled pixels. Bird Boat Bottle Bus Motor bike Person Potted Plant Sheep










![07%, which is comparable to 16% of [2] using similar](/docs-images/88/115901640/images/2-11.jpg "parameters (SIFT like IHOG feature, hierarchical")
. 3.")

![truth Input [25] Proposed Ground truth Figure 2.](/docs-images/88/115901640/images/2-14.jpg "Qualitative comparison with [25].")
![Being an image categorization approach, [25] does](/docs-images/88/115901640/images/2-15.jpg "not report quantitative results of saliency")







2 For comparison with fully supervised class segmentation approaches [2, 11], saliency maps corresponding to each object model are applied over a test image. The pixels that have overlapping saliency values of different object classes are assigned the class with the highest saliency. Object-specific saliency maps are thresholded at their EER as explained in the paper. The pixels that fall below this threshold are classified as background. Following such an approach, 57.3% of the total pixels are correctly classified, which is better than 57% in [11], which uses fully supervised learning of CRF on superpixel based image features. The percentage of correctly labeled pixels for each class is evaluated and averaged across 21 classes(20 object classes and background class). We obtain a mean of 17.07%, which is comparable to 16% of [2] using similar parameters (SIFT like IHOG feature, hierarchical K-means based dictionary, using spatial bins and linear classifier). 3. Qualitative comparison with weakly supervised top-down saliency [25] Input [25] Proposed Ground truth Input [25] Proposed Ground truth Figure 2. Qualitative comparison with [25]. Being an image categorization approach, [25] does not report quantitative results of saliency estimation. Instead saliency maps corresponding to 6 images from Graz-02 dataset are given in the paper. In contrast to traditional training-test set split, they used 150 even numbered images per category for training and 150 odd numbered images per category for testing. We also evaluated our model using this train-test split and saliency maps corresponding to these 6 test images are produced using our approach. Fig. 2 shows that the proposed method clearly outperforms [25] (they evaluate only on Graz-02 dataset and not on PASCAL VOC-07). 4. Qualitative comparison with fully supervised top-down saliency approaches Here we compare our saliency maps with [36, 20, 5], in both Graz-02 and PASCAL VOC-07 datasets. Saliency maps of [20, 5] are provided by the authors. Saliency maps of [36] are produced using the code provided by the authors Graz-02 Input Yang and Yang [36] Kocak et al. [20] LCCSC [5] Proposed Figure 3. Qualitative comparison of our weakly supervised approach with fully supervised top-down saliency approaches for some images of Graz-02 dataset. 2








































3 4.2. PASCAL VOC-07 Qualitative comparison with fully supervised top-down saliency approaches is given in Fig. 4. AEROPLANE BICYCLE BIRD CAT Input Yang and Yang [36] Kocak DOG et al. [20] LCCSC [5] Proposed Figure 4. Qualitative comparison of the proposed weakly supervised approach against fully supervised top-down saliency approaches for PASCAL VOC More Saliency maps by the proposed method on Graz-02 and PASCAL VOC Graz-02 Input MOTORBIKE Yang and Yang [36] Kocak et al. [20] LCCSC [5] Figure 5. Saliency maps generated using the proposed weakly supervised approach on Graz-02 images. 3 Proposed



















4 5.2. PASCAL VOC-07 Saliency maps generated on PASCAL VOC-07 segmentation and detection test images are shown in Fig. 6, 7. AEROPLANE BICYCLE BIRD CAR CAT CHAIR Figure 6. Qualitative results of proposed weakly supervised approach on PASCAL VOC-07. It is hard to identify the presence of bird (column 1) inbetween trees. Car (column 3) is successfully identified even with the presence of other 3 object categories-dog,horse and person. 4



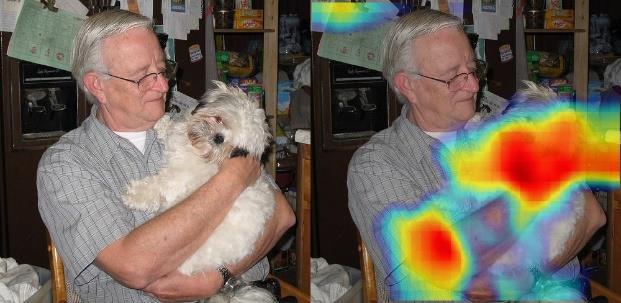


















5 DOG HORSE MOTORBIKE PERSON POTTED PLANT BOTTLE Figure 7. Qualitative results of proposed weakly supervised approach on PASCAL VOC-07. Motorbike is correctly identified, even-though it is occluded with car (column 2). It is hard to identify the presence of potted-plant which is correctly marked as salient (Column 2) 5








 identified on")


6 6. Class-specific patches extracted using R-ScSPM saliency Image patches having R-ScSPM saliency 0.5 are considered as the class-specific patches of that image. Here we show the class-specific patches extracted on Graz-02 and PASCAL VOC-07 images Class-specfic patches extracted on Graz-02 images Input Patches Input Patches Input Patches Figure 8. Class-specific patches (red) identified on training images by thresholding R-ScSPM saliency at 0.5. In the car image (column 1), car patches are selected by removing the tree patches that occlude the car. 6






























7 6.1.1 Class-specific patches extracted on PASCAL VOC-07 images Fig. 9, 10 shows the class-specific patches extracted on PASCAL VOC-07 detection images. AEROPLANE BICYCLE BIRD BOAT BOTTLE BUS Figure 9. Class-specific patches identified on PASCAL VOC-07 images. 7




























8 CAR CAT CHAIR COW DOG HORSE Figure 10. Class-specific patches identified on PASCAL VOC-07 images. 8




![discovery) [29], Joulin et al.](/docs-images/88/115901640/images/9-6.jpg "[15], and DPM+Grabcut")
![implementation given in [1].](/docs-images/88/115901640/images/9-7.jpg "We did not compare with semantic")
![object selection [1] since their](/docs-images/88/115901640/images/9-8.jpg "training requires an additional")


![[15] DPM+Grabcut Figure 11.](/docs-images/88/115901640/images/9-11.jpg "Comparison with co-segmentation")
9 7. Supplementary results for applications 7.1. Object class segmentation Comparison with co-segmentation approaches on Object Discovery dataset Segmentation results obtained using our saliency maps are compared with OD (object discovery) [29], Joulin et al. [15], and DPM+Grabcut implementation given in [1]. We did not compare with semantic object selection [1] since their training requires an additional level of supervision to select training images having white background. Input Proposed OD [29] Joulin et al. [15] DPM+Grabcut Figure 11. Comparison with co-segmentation approaches -object discovery [29], Joulin et al. [15] and grabcut applied on DPM detection output on Object Discovery dataset. 9































10 7.1.2 More segmentation results Figure 12. Segmentation results obtained from our saliency maps on Object Discovery dataset Object annotation Fig. 13 shows the object annotation results on PASCAL VOC-07 detection images. Annotaiton box obtained from our saliency map are shown in yellow color and the ground truth is shown as green colored box. 10


























































11 Cow Chair Cat Car Bus Bottle Boat Bird Bicycle Aeroplane Figure 13. Object annotation obtained on PASCAL VOC-07 detection training images using proposed approach. Green rectangular boxes shows the ground truth and yellow boxes indicates the annotation boxes obtained using the proposed approach 11










12 7.3. Action-specific patch discovery A linear classifier is learned for each action category in PASCAL VOC 2010 action dataset and these ScSPM-based classifiers are used to extract the category-specific patches corresponding to each action class as explained in the paper. Action classification works like [32] use a bounding box across the person even on test images. For training and testing, we do not use a bounding box across the person. A binary label indicating the presence or absence of a particular action in the given image is only used for classifier training. It can be seen from the results below that the proposed framework is able to extract class-specific patches corresponding to each action Action specific patches identified by R-ScSPM saliency Phoning Playing Instrument Reading Figure 14. Action category-specific patches identified on PASCAL VOC 2010 action dataset training images by the proposed patch selection strategy; i.e, by thresholding R-ScSPM saliency at 0.5). It can be observed that for phoning category, hand near the ear together with phone are identified as the class specific patches. The instruments in playing instrument, books and newspaper in reading are detected as category specific patches. References The numbering of references in the paper are used for citation. 12
THE human visual system has the ability to zero-in rapidly onto
 1 Weakly Supervised Top-down Salient Object Detection Hisham Cholakkal, Jubin Johnson, and Deepu Rajan arxiv:1611.05345v2 [cs.cv] 17 Nov 2016 Abstract Top-down saliency models produce a probability map
1 Weakly Supervised Top-down Salient Object Detection Hisham Cholakkal, Jubin Johnson, and Deepu Rajan arxiv:1611.05345v2 [cs.cv] 17 Nov 2016 Abstract Top-down saliency models produce a probability map
Object Detection. Honghui Shi IBM Research Columbia
 Object Detection Honghui Shi IBM Research 2018.11.27 @ Columbia Outline Problem Evaluation Methods Directions Problem Image classification: Horse (People, Dog, Truck ) Object detection: categories & locations
Object Detection Honghui Shi IBM Research 2018.11.27 @ Columbia Outline Problem Evaluation Methods Directions Problem Image classification: Horse (People, Dog, Truck ) Object detection: categories & locations
Backtracking ScSPM Image Classifier for Weakly Supervised Top-down Saliency
 Backtracking ScSPM Image Classifier for Weakly Supervised Top-down Saliency Hisham Cholakkal Jubin Johnson Deepu Rajan Multimedia Lab, School of Computer Science and Engineering Nanyang Technological University
Backtracking ScSPM Image Classifier for Weakly Supervised Top-down Saliency Hisham Cholakkal Jubin Johnson Deepu Rajan Multimedia Lab, School of Computer Science and Engineering Nanyang Technological University
Object Recognition: Conceptual Issues. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman
 Object Recognition: Conceptual Issues Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman Issues in recognition The statistical viewpoint Generative vs. discriminative methods
Object Recognition: Conceptual Issues Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and K. Grauman Issues in recognition The statistical viewpoint Generative vs. discriminative methods
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik UC Berkeley Tech Report @ http://arxiv.org/abs/1311.2524! Detection
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik UC Berkeley Tech Report @ http://arxiv.org/abs/1311.2524! Detection
Attentional Masking for Pre-trained Deep Networks
 Attentional Masking for Pre-trained Deep Networks IROS 2017 Marcus Wallenberg and Per-Erik Forssén Computer Vision Laboratory Department of Electrical Engineering Linköping University 2014 2017 Per-Erik
Attentional Masking for Pre-trained Deep Networks IROS 2017 Marcus Wallenberg and Per-Erik Forssén Computer Vision Laboratory Department of Electrical Engineering Linköping University 2014 2017 Per-Erik
Deep Networks and Beyond. Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University
 Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Experiment Presentation CS Chris Thomas Experiment: What is an Object? Alexe, Bogdan, et al. CVPR 2010
 Experiment Presentation CS 3710 Chris Thomas Experiment: What is an Object? Alexe, Bogdan, et al. CVPR 2010 1 Preliminaries Code for What is An Object? available online Version 2.2 Achieves near 90% recall
Experiment Presentation CS 3710 Chris Thomas Experiment: What is an Object? Alexe, Bogdan, et al. CVPR 2010 1 Preliminaries Code for What is An Object? available online Version 2.2 Achieves near 90% recall
Categories. Represent/store visual objects in terms of categories. What are categories? Why do we need categories?
 Represen'ng Objects Categories Represent/store visual objects in terms of categories. What are categories? Why do we need categories? Grouping of objects into sets where sets are called categories! Categories
Represen'ng Objects Categories Represent/store visual objects in terms of categories. What are categories? Why do we need categories? Grouping of objects into sets where sets are called categories! Categories
576 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 39, NO. 3, MARCH 2017
 576 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 39, NO. 3, MARCH 2017 Top-Down Visual Saliency via Joint CRF and Dictionary Learning Jimei Yang and Ming-Hsuan Yang Abstract Top-down
576 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 39, NO. 3, MARCH 2017 Top-Down Visual Saliency via Joint CRF and Dictionary Learning Jimei Yang and Ming-Hsuan Yang Abstract Top-down
Top down saliency estimation via superpixel-based discriminative dictionaries
 KOCAK ET AL.: TOP DOWN SALIENCY ESTIMATION 1 Top down saliency estimation via superpixel-based discriminative dictionaries Aysun Kocak aysunkocak@cs.hacettepe.edu.tr Kemal Cizmeciler kemalcizmeci@gmail.com
KOCAK ET AL.: TOP DOWN SALIENCY ESTIMATION 1 Top down saliency estimation via superpixel-based discriminative dictionaries Aysun Kocak aysunkocak@cs.hacettepe.edu.tr Kemal Cizmeciler kemalcizmeci@gmail.com
Exemplar-Driven Top-Down Saliency Detection via Deep Association
 Exemplar-Driven Top-Down Saliency Detection via Deep Association Shengfeng He 1, Rynson W.H. Lau 1, and Qingxiong Yang 2 1 Department of Computer Science, City University of Hong Kong 2 School of Information
Exemplar-Driven Top-Down Saliency Detection via Deep Association Shengfeng He 1, Rynson W.H. Lau 1, and Qingxiong Yang 2 1 Department of Computer Science, City University of Hong Kong 2 School of Information
Object Detectors Emerge in Deep Scene CNNs
 Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Towards The Deep Model: Understanding Visual Recognition Through Computational Models. Panqu Wang Dissertation Defense 03/23/2017
 Towards The Deep Model: Understanding Visual Recognition Through Computational Models Panqu Wang Dissertation Defense 03/23/2017 Summary Human Visual Recognition (face, object, scene) Simulate Explain
Towards The Deep Model: Understanding Visual Recognition Through Computational Models Panqu Wang Dissertation Defense 03/23/2017 Summary Human Visual Recognition (face, object, scene) Simulate Explain
Shu Kong. Department of Computer Science, UC Irvine
 Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge and philosophy 4. Fine-grained classification with
Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge and philosophy 4. Fine-grained classification with
Shu Kong. Department of Computer Science, UC Irvine
 Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition
 Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition Stefan Mathe, Cristian Sminchisescu Presented by Mit Shah Motivation Current Computer Vision Annotations subjectively
Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition Stefan Mathe, Cristian Sminchisescu Presented by Mit Shah Motivation Current Computer Vision Annotations subjectively
Learning Saliency Maps for Object Categorization
 Learning Saliency Maps for Object Categorization Frank Moosmann, Diane Larlus, Frederic Jurie INRIA Rhône-Alpes - GRAVIR - CNRS, {Frank.Moosmann,Diane.Larlus,Frederic.Jurie}@inrialpes.de http://lear.inrialpes.fr
Learning Saliency Maps for Object Categorization Frank Moosmann, Diane Larlus, Frederic Jurie INRIA Rhône-Alpes - GRAVIR - CNRS, {Frank.Moosmann,Diane.Larlus,Frederic.Jurie}@inrialpes.de http://lear.inrialpes.fr
Understanding and Predicting Importance in Images
 Understanding and Predicting Importance in Images Alexander C. Berg, Tamara L. Berg, Hal Daume III, Jesse Dodge, Amit Goyal, Xufeng Han, Alyssa Mensch, Margaret Mitchell, Aneesh Sood, Karl Stratos, Kota
Understanding and Predicting Importance in Images Alexander C. Berg, Tamara L. Berg, Hal Daume III, Jesse Dodge, Amit Goyal, Xufeng Han, Alyssa Mensch, Margaret Mitchell, Aneesh Sood, Karl Stratos, Kota
Learned Region Sparsity and Diversity Also Predict Visual Attention
 Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Computational modeling of visual attention and saliency in the Smart Playroom
 Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Visual Saliency Based on Multiscale Deep Features Supplementary Material
 Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
Fusing Generic Objectness and Visual Saliency for Salient Object Detection
 Fusing Generic Objectness and Visual Saliency for Salient Object Detection Yasin KAVAK 06/12/2012 Citation 1: Salient Object Detection: A Benchmark Fusing for Salient Object Detection INDEX (Related Work)
Fusing Generic Objectness and Visual Saliency for Salient Object Detection Yasin KAVAK 06/12/2012 Citation 1: Salient Object Detection: A Benchmark Fusing for Salient Object Detection INDEX (Related Work)
Learning to Generate Long-term Future via Hierarchical Prediction. A. Motion-Based Pixel-Level Evaluation, Analysis, and Control Experiments
 Appendix A. Motion-Based Pixel-Level Evaluation, Analysis, and Control Experiments In this section, we evaluate the predictions by deciles of motion similar to Villegas et al. (2017) using Peak Signal-to-Noise
Appendix A. Motion-Based Pixel-Level Evaluation, Analysis, and Control Experiments In this section, we evaluate the predictions by deciles of motion similar to Villegas et al. (2017) using Peak Signal-to-Noise
CS4495 Computer Vision Introduction to Recognition. Aaron Bobick School of Interactive Computing
 CS4495 Computer Vision Introduction to Recognition Aaron Bobick School of Interactive Computing What does recognition involve? Source: Fei Fei Li, Rob Fergus, Antonio Torralba. Verification: is that
CS4495 Computer Vision Introduction to Recognition Aaron Bobick School of Interactive Computing What does recognition involve? Source: Fei Fei Li, Rob Fergus, Antonio Torralba. Verification: is that
Clusters, Symbols and Cortical Topography
 Clusters, Symbols and Cortical Topography Lee Newman Thad Polk Dept. of Psychology Dept. Electrical Engineering & Computer Science University of Michigan 26th Soar Workshop May 26, 2006 Ann Arbor, MI agenda
Clusters, Symbols and Cortical Topography Lee Newman Thad Polk Dept. of Psychology Dept. Electrical Engineering & Computer Science University of Michigan 26th Soar Workshop May 26, 2006 Ann Arbor, MI agenda
CHAPTER 9 SUMMARY AND CONCLUSION
 CHAPTER 9 SUMMARY AND CONCLUSION 9.1 SUMMARY In this thesis, the CAD system for early detection and classification of ischemic stroke in CT image, hemorrhage and hematoma in brain CT image and brain tumor
CHAPTER 9 SUMMARY AND CONCLUSION 9.1 SUMMARY In this thesis, the CAD system for early detection and classification of ischemic stroke in CT image, hemorrhage and hematoma in brain CT image and brain tumor
arxiv: v1 [cs.cv] 2 Jun 2017
![arxiv: v1 [cs.cv] 2 Jun 2017](/thumbs/74/71415505.jpg "arxiv: v1 [cs.cv] 2 Jun 2017") INTEGRATED DEEP AND SHALLOW NETWORKS FOR SALIENT OBJECT DETECTION Jing Zhang 1,2, Bo Li 1, Yuchao Dai 2, Fatih Porikli 2 and Mingyi He 1 1 School of Electronics and Information, Northwestern Polytechnical
INTEGRATED DEEP AND SHALLOW NETWORKS FOR SALIENT OBJECT DETECTION Jing Zhang 1,2, Bo Li 1, Yuchao Dai 2, Fatih Porikli 2 and Mingyi He 1 1 School of Electronics and Information, Northwestern Polytechnical
Learning to Disambiguate by Asking Discriminative Questions Supplementary Material
 Learning to Disambiguate by Asking Discriminative Questions Supplementary Material Yining Li 1 Chen Huang 2 Xiaoou Tang 1 Chen Change Loy 1 1 Department of Information Engineering, The Chinese University
Learning to Disambiguate by Asking Discriminative Questions Supplementary Material Yining Li 1 Chen Huang 2 Xiaoou Tang 1 Chen Change Loy 1 1 Department of Information Engineering, The Chinese University
Neuromorphic convolutional recurrent neural network for road safety or safety near the road
 Neuromorphic convolutional recurrent neural network for road safety or safety near the road WOO-SUP HAN 1, IL SONG HAN 2 1 ODIGA, London, U.K. 2 Korea Advanced Institute of Science and Technology, Daejeon,
Neuromorphic convolutional recurrent neural network for road safety or safety near the road WOO-SUP HAN 1, IL SONG HAN 2 1 ODIGA, London, U.K. 2 Korea Advanced Institute of Science and Technology, Daejeon,
An Attentional Framework for 3D Object Discovery
 An Attentional Framework for 3D Object Discovery Germán Martín García and Simone Frintrop Cognitive Vision Group Institute of Computer Science III University of Bonn, Germany Saliency Computation Saliency
An Attentional Framework for 3D Object Discovery Germán Martín García and Simone Frintrop Cognitive Vision Group Institute of Computer Science III University of Bonn, Germany Saliency Computation Saliency
VISUAL search is necessary for rapid scene analysis
 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 3475 A Unified Framework for Salient Structure Detection by Contour-Guided Visual Search Kai-Fu Yang, Hui Li, Chao-Yi Li, and Yong-Jie
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 3475 A Unified Framework for Salient Structure Detection by Contour-Guided Visual Search Kai-Fu Yang, Hui Li, Chao-Yi Li, and Yong-Jie
Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation
 Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation Takumi Ege, Yoshikazu Ando, Ryosuke Tanno, Wataru Shimoda and Keiji Yanai Department of Informatics, The University of Electro-Communications,
Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation Takumi Ege, Yoshikazu Ando, Ryosuke Tanno, Wataru Shimoda and Keiji Yanai Department of Informatics, The University of Electro-Communications,
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING
 VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
Multi-task Learning of Dish Detection and Calorie Estimation
 Multi-task Learning of Dish Detection and Calorie Estimation Takumi Ege and Keiji Yanai The University of Electro-Communications, Tokyo Introduction Foodlog CaloNavi Volume selection required Crop a dish
Multi-task Learning of Dish Detection and Calorie Estimation Takumi Ege and Keiji Yanai The University of Electro-Communications, Tokyo Introduction Foodlog CaloNavi Volume selection required Crop a dish
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
 Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering SUPPLEMENTARY MATERIALS 1. Implementation Details 1.1. Bottom-Up Attention Model Our bottom-up attention Faster R-CNN
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering SUPPLEMENTARY MATERIALS 1. Implementation Details 1.1. Bottom-Up Attention Model Our bottom-up attention Faster R-CNN
Top-Down Color Attention for Object Recognition
 Top-Down Color Attention for Object Recognition Fahad Shahbaz Khan, Joost van de Weijer, Maria Vanrell Centre de Visio per Computador, Computer Science Department Universitat Autonoma de Barcelona, Edifci
Top-Down Color Attention for Object Recognition Fahad Shahbaz Khan, Joost van de Weijer, Maria Vanrell Centre de Visio per Computador, Computer Science Department Universitat Autonoma de Barcelona, Edifci
Discovery of Rare Phenotypes in Cellular Images Using Weakly Supervised Deep Learning
 Discovery of Rare Phenotypes in Cellular Images Using Weakly Supervised Deep Learning Heba Sailem *1, Mar Arias Garcia 2, Chris Bakal 2, Andrew Zisserman 1, and Jens Rittscher 1 1 Department of Engineering
Discovery of Rare Phenotypes in Cellular Images Using Weakly Supervised Deep Learning Heba Sailem *1, Mar Arias Garcia 2, Chris Bakal 2, Andrew Zisserman 1, and Jens Rittscher 1 1 Department of Engineering
A Review of Co-saliency Detection Technique: Fundamentals, Applications, and Challenges
 REGULAR PAPER 1 A Review of Co-saliency Detection Technique: Fundamentals, Applications, and Challenges Dingwen Zhang, Huazhu Fu, Junwei Han, Senior Member, IEEE, Feng Wu, Fellow, IEEE arxiv:1604.07090v2
REGULAR PAPER 1 A Review of Co-saliency Detection Technique: Fundamentals, Applications, and Challenges Dingwen Zhang, Huazhu Fu, Junwei Han, Senior Member, IEEE, Feng Wu, Fellow, IEEE arxiv:1604.07090v2
Brain Tumor segmentation and classification using Fcm and support vector machine
 Brain Tumor segmentation and classification using Fcm and support vector machine Gaurav Gupta 1, Vinay singh 2 1 PG student,m.tech Electronics and Communication,Department of Electronics, Galgotia College
Brain Tumor segmentation and classification using Fcm and support vector machine Gaurav Gupta 1, Vinay singh 2 1 PG student,m.tech Electronics and Communication,Department of Electronics, Galgotia College
Characterization of Tissue Histopathology via Predictive Sparse Decomposition and Spatial Pyramid Matching
 Characterization of Tissue Histopathology via Predictive Sparse Decomposition and Spatial Pyramid Matching Hang Chang 1,, Nandita Nayak 1,PaulT.Spellman 2, and Bahram Parvin 1, 1 Life Sciences Division,
Characterization of Tissue Histopathology via Predictive Sparse Decomposition and Spatial Pyramid Matching Hang Chang 1,, Nandita Nayak 1,PaulT.Spellman 2, and Bahram Parvin 1, 1 Life Sciences Division,
Accessorize to a Crime: Real and Stealthy Attacks on State-Of. Face Recognition. Keshav Yerra ( ) Monish Prasad ( )
 Monish Prasad ( )") Accessorize to a Crime: Real and Stealthy Attacks on State-Of Of-The The-Art Face Recognition Keshav Yerra (2670843) Monish Prasad (2671587) Machine Learning is Everywhere Cancer Diagnosis Surveillance
Accessorize to a Crime: Real and Stealthy Attacks on State-Of Of-The The-Art Face Recognition Keshav Yerra (2670843) Monish Prasad (2671587) Machine Learning is Everywhere Cancer Diagnosis Surveillance
Modeling the Deployment of Spatial Attention
 17 Chapter 3 Modeling the Deployment of Spatial Attention 3.1 Introduction When looking at a complex scene, our visual system is confronted with a large amount of visual information that needs to be broken
17 Chapter 3 Modeling the Deployment of Spatial Attention 3.1 Introduction When looking at a complex scene, our visual system is confronted with a large amount of visual information that needs to be broken
Gene expression analysis. Roadmap. Microarray technology: how it work Applications: what can we do with it Preprocessing: Classification Clustering
 Gene expression analysis Roadmap Microarray technology: how it work Applications: what can we do with it Preprocessing: Image processing Data normalization Classification Clustering Biclustering 1 Gene
Gene expression analysis Roadmap Microarray technology: how it work Applications: what can we do with it Preprocessing: Image processing Data normalization Classification Clustering Biclustering 1 Gene
Active Deformable Part Models Inference
 Active Deformable Part Models Inference Menglong Zhu Nikolay Atanasov George J. Pappas Kostas Daniilidis GRASP Laboratory, University of Pennsylvania 3330 Walnut Street, Philadelphia, PA 19104, USA Abstract.
Active Deformable Part Models Inference Menglong Zhu Nikolay Atanasov George J. Pappas Kostas Daniilidis GRASP Laboratory, University of Pennsylvania 3330 Walnut Street, Philadelphia, PA 19104, USA Abstract.
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images
 Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images Sachin Mehta 1, Ezgi Mercan 1, Jamen Bartlett 2, Donald Weaver 2, Joann G. Elmore 1, and Linda Shapiro 1 1 University
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images Sachin Mehta 1, Ezgi Mercan 1, Jamen Bartlett 2, Donald Weaver 2, Joann G. Elmore 1, and Linda Shapiro 1 1 University
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis
 Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
Hierarchical Convolutional Features for Visual Tracking
 Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features
 Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features U.Swamy Kumar PG Scholar Department of ECE, K.S.R.M College of Engineering (Autonomous), Kadapa. ABSTRACT Salient
Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features U.Swamy Kumar PG Scholar Department of ECE, K.S.R.M College of Engineering (Autonomous), Kadapa. ABSTRACT Salient
Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics
 Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics Bora Celikkale a, Aykut Erdem a, Erkut Erdem a, a Department of Computer Engineering, Hacettepe University,
Predicting Memorability of Images Using Attention-driven Spatial Pooling and Image Semantics Bora Celikkale a, Aykut Erdem a, Erkut Erdem a, a Department of Computer Engineering, Hacettepe University,
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION. {zzwang, ruihuang, lwan,
 EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
Detection of Glaucoma and Diabetic Retinopathy from Fundus Images by Bloodvessel Segmentation
 International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-5, Issue-5, June 2016 Detection of Glaucoma and Diabetic Retinopathy from Fundus Images by Bloodvessel Segmentation
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-5, Issue-5, June 2016 Detection of Glaucoma and Diabetic Retinopathy from Fundus Images by Bloodvessel Segmentation
Network Dissection: Quantifying Interpretability of Deep Visual Representation
 Name: Pingchuan Ma Student number: 3526400 Date: August 19, 2018 Seminar: Explainable Machine Learning Lecturer: PD Dr. Ullrich Köthe SS 2018 Quantifying Interpretability of Deep Visual Representation
Name: Pingchuan Ma Student number: 3526400 Date: August 19, 2018 Seminar: Explainable Machine Learning Lecturer: PD Dr. Ullrich Köthe SS 2018 Quantifying Interpretability of Deep Visual Representation
Large-scale Histopathology Image Analysis for Colon Cancer on Azure
 Large-scale Histopathology Image Analysis for Colon Cancer on Azure Yan Xu 1, 2 Tao Mo 2 Teng Gao 2 Maode Lai 4 Zhuowen Tu 2,3 Eric I-Chao Chang 2 1 Beihang University; 2 Microsoft Research Asia; 3 UCSD;
Large-scale Histopathology Image Analysis for Colon Cancer on Azure Yan Xu 1, 2 Tao Mo 2 Teng Gao 2 Maode Lai 4 Zhuowen Tu 2,3 Eric I-Chao Chang 2 1 Beihang University; 2 Microsoft Research Asia; 3 UCSD;
arxiv: v1 [cs.cv] 13 Jul 2018
![arxiv: v1 [cs.cv] 13 Jul 2018](/thumbs/84/89699669.jpg "arxiv: v1 [cs.cv] 13 Jul 2018") Multi-Scale Convolutional-Stack Aggregation for Robust White Matter Hyperintensities Segmentation Hongwei Li 1, Jianguo Zhang 3, Mark Muehlau 2, Jan Kirschke 2, and Bjoern Menze 1 arxiv:1807.05153v1 [cs.cv]
Multi-Scale Convolutional-Stack Aggregation for Robust White Matter Hyperintensities Segmentation Hongwei Li 1, Jianguo Zhang 3, Mark Muehlau 2, Jan Kirschke 2, and Bjoern Menze 1 arxiv:1807.05153v1 [cs.cv]
Improved object categorization and detection using comparative object similarity
 Improved object categorization and detection using comparative object similarity Gang Wang, Member, IEEE, David Forsyth, Fellow, IEEE, Derek Hoiem, Member, IEEE Abstract Due to the intrinsic long-tailed
Improved object categorization and detection using comparative object similarity Gang Wang, Member, IEEE, David Forsyth, Fellow, IEEE, Derek Hoiem, Member, IEEE Abstract Due to the intrinsic long-tailed
Selecting Patches, Matching Species:
 Selecting Patches, Matching Species: Shu Kong CS, ICS, UCI 2016-4-6 Selecting Patches, Matching Species: Fossil Pollen Identification... Shu Kong CS, ICS, UCI 2016-4-6 Selecting Patches, Matching Species:
Selecting Patches, Matching Species: Shu Kong CS, ICS, UCI 2016-4-6 Selecting Patches, Matching Species: Fossil Pollen Identification... Shu Kong CS, ICS, UCI 2016-4-6 Selecting Patches, Matching Species:
HHS Public Access Author manuscript Med Image Comput Comput Assist Interv. Author manuscript; available in PMC 2018 January 04.
 Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules Xinyang Feng 1, Jie Yang 1, Andrew F. Laine 1, and Elsa D. Angelini 1,2 1 Department of Biomedical Engineering,
Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules Xinyang Feng 1, Jie Yang 1, Andrew F. Laine 1, and Elsa D. Angelini 1,2 1 Department of Biomedical Engineering,
Holistically-Nested Edge Detection (HED)
") Holistically-Nested Edge Detection (HED) Saining Xie, Zhuowen Tu Presented by Yuxin Wu February 10, 20 What is an Edge? Local intensity change? Used in traditional methods: Canny, Sobel, etc Learn it!
Holistically-Nested Edge Detection (HED) Saining Xie, Zhuowen Tu Presented by Yuxin Wu February 10, 20 What is an Edge? Local intensity change? Used in traditional methods: Canny, Sobel, etc Learn it!
Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios
 2012 Ninth Conference on Computer and Robot Vision Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios Neil D. B. Bruce*, Xun Shi*, and John K. Tsotsos Department of Computer
2012 Ninth Conference on Computer and Robot Vision Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios Neil D. B. Bruce*, Xun Shi*, and John K. Tsotsos Department of Computer
Action Recognition. Computer Vision Jia-Bin Huang, Virginia Tech. Many slides from D. Hoiem
 Action Recognition Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem This section: advanced topics Convolutional neural networks in vision Action recognition Vision and Language 3D
Action Recognition Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem This section: advanced topics Convolutional neural networks in vision Action recognition Vision and Language 3D
arxiv: v1 [cs.cv] 10 Aug 2018
![arxiv: v1 [cs.cv] 10 Aug 2018](/thumbs/92/110876203.jpg "arxiv: v1 [cs.cv] 10 Aug 2018") Out of the Black Box: Properties of deep neural networks and their applications Nizar Ouarti 1, David Carmona 1, 1 IPAL, Sorbonne Universite, CNRS, NUS nizar.ouarti@ipal.cnrs.fr, david.carmona93@gmail.com
Out of the Black Box: Properties of deep neural networks and their applications Nizar Ouarti 1, David Carmona 1, 1 IPAL, Sorbonne Universite, CNRS, NUS nizar.ouarti@ipal.cnrs.fr, david.carmona93@gmail.com
How do Categories Work?
 Presentations Logistics Think about what you want to do Thursday we ll informally sign up, see if we can reach consensus. Topics Linear representations of classes Non-linear representations of classes
Presentations Logistics Think about what you want to do Thursday we ll informally sign up, see if we can reach consensus. Topics Linear representations of classes Non-linear representations of classes
POC Brain Tumor Segmentation. vlife Use Case
 Brain Tumor Segmentation vlife Use Case 1 Automatic Brain Tumor Segmentation using CNN Background Brain tumor segmentation seeks to separate healthy tissue from tumorous regions such as the advancing tumor,
Brain Tumor Segmentation vlife Use Case 1 Automatic Brain Tumor Segmentation using CNN Background Brain tumor segmentation seeks to separate healthy tissue from tumorous regions such as the advancing tumor,
Automated Estimation of mts Score in Hand Joint X-Ray Image Using Machine Learning
 Automated Estimation of mts Score in Hand Joint X-Ray Image Using Machine Learning Shweta Khairnar, Sharvari Khairnar 1 Graduate student, Pace University, New York, United States 2 Student, Computer Engineering,
Automated Estimation of mts Score in Hand Joint X-Ray Image Using Machine Learning Shweta Khairnar, Sharvari Khairnar 1 Graduate student, Pace University, New York, United States 2 Student, Computer Engineering,
Automated Embryo Stage Classification in Time-Lapse Microscopy Video of Early Human Embryo Development
 Automated Embryo Stage Classification in Time-Lapse Microscopy Video of Early Human Embryo Development Yu Wang, Farshid Moussavi, and Peter Lorenzen Auxogyn, Inc. 1490 O Brien Drive, Suite A, Menlo Park,
Automated Embryo Stage Classification in Time-Lapse Microscopy Video of Early Human Embryo Development Yu Wang, Farshid Moussavi, and Peter Lorenzen Auxogyn, Inc. 1490 O Brien Drive, Suite A, Menlo Park,
Putting Context into. Vision. September 15, Derek Hoiem
 Putting Context into Vision Derek Hoiem September 15, 2004 Questions to Answer What is context? How is context used in human vision? How is context currently used in computer vision? Conclusions Context
Putting Context into Vision Derek Hoiem September 15, 2004 Questions to Answer What is context? How is context used in human vision? How is context currently used in computer vision? Conclusions Context
Saliency Prediction with Active Semantic Segmentation
 JIANG et al.: SALIENCY PREDICTION WITH ACTIVE SEMANTIC SEGMENTATION 1 Saliency Prediction with Active Semantic Segmentation Ming Jiang 1 mjiang@u.nus.edu Xavier Boix 1,3 elexbb@nus.edu.sg Juan Xu 1 jxu@nus.edu.sg
JIANG et al.: SALIENCY PREDICTION WITH ACTIVE SEMANTIC SEGMENTATION 1 Saliency Prediction with Active Semantic Segmentation Ming Jiang 1 mjiang@u.nus.edu Xavier Boix 1,3 elexbb@nus.edu.sg Juan Xu 1 jxu@nus.edu.sg
Computational Cognitive Science
 Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Automatic Prostate Cancer Classification using Deep Learning. Ida Arvidsson Centre for Mathematical Sciences, Lund University, Sweden
 Automatic Prostate Cancer Classification using Deep Learning Ida Arvidsson Centre for Mathematical Sciences, Lund University, Sweden Outline Autoencoders, theory Motivation, background and goal for prostate
Automatic Prostate Cancer Classification using Deep Learning Ida Arvidsson Centre for Mathematical Sciences, Lund University, Sweden Outline Autoencoders, theory Motivation, background and goal for prostate
Multi-Scale Salient Object Detection with Pyramid Spatial Pooling
 Multi-Scale Salient Object Detection with Pyramid Spatial Pooling Jing Zhang, Yuchao Dai, Fatih Porikli and Mingyi He School of Electronics and Information, Northwestern Polytechnical University, China.
Multi-Scale Salient Object Detection with Pyramid Spatial Pooling Jing Zhang, Yuchao Dai, Fatih Porikli and Mingyi He School of Electronics and Information, Northwestern Polytechnical University, China.
Latent Fingerprint Image Quality Assessment Using Deep Learning
 Latent Fingerprint Image Quality Assessment Using Deep Learning Jude Ezeobiejesi and Bir Bhanu Center for Research in Intelligent Systems University of California at Riverside, Riverside, CA 92584, USA
Latent Fingerprint Image Quality Assessment Using Deep Learning Jude Ezeobiejesi and Bir Bhanu Center for Research in Intelligent Systems University of California at Riverside, Riverside, CA 92584, USA
Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation
 Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation U. Baid 1, S. Talbar 2 and S. Talbar 1 1 Department of E&TC Engineering, Shri Guru Gobind Singhji
Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation U. Baid 1, S. Talbar 2 and S. Talbar 1 1 Department of E&TC Engineering, Shri Guru Gobind Singhji
Computational Cognitive Science. The Visual Processing Pipeline. The Visual Processing Pipeline. Lecture 15: Visual Attention.
 Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Motivation: Attention: Focusing on specific parts of the input. Inspired by neuroscience.
 Outline: Motivation. What s the attention mechanism? Soft attention vs. Hard attention. Attention in Machine translation. Attention in Image captioning. State-of-the-art. 1 Motivation: Attention: Focusing
Outline: Motivation. What s the attention mechanism? Soft attention vs. Hard attention. Attention in Machine translation. Attention in Image captioning. State-of-the-art. 1 Motivation: Attention: Focusing
Skin cancer reorganization and classification with deep neural network
 Skin cancer reorganization and classification with deep neural network Hao Chang 1 1. Department of Genetics, Yale University School of Medicine 2. Email: changhao86@gmail.com Abstract As one kind of skin
Skin cancer reorganization and classification with deep neural network Hao Chang 1 1. Department of Genetics, Yale University School of Medicine 2. Email: changhao86@gmail.com Abstract As one kind of skin
CHAPTER 6 HUMAN BEHAVIOR UNDERSTANDING MODEL
 127 CHAPTER 6 HUMAN BEHAVIOR UNDERSTANDING MODEL 6.1 INTRODUCTION Analyzing the human behavior in video sequences is an active field of research for the past few years. The vital applications of this field
127 CHAPTER 6 HUMAN BEHAVIOR UNDERSTANDING MODEL 6.1 INTRODUCTION Analyzing the human behavior in video sequences is an active field of research for the past few years. The vital applications of this field
Efficient Salient Region Detection with Soft Image Abstraction
 Efficient Salient Region Detection with Soft Image Abstraction Ming-Ming Cheng Jonathan Warrell Wen-Yan Lin Shuai Zheng Vibhav Vineet Nigel Crook Vision Group, Oxford Brookes University Abstract Detecting
Efficient Salient Region Detection with Soft Image Abstraction Ming-Ming Cheng Jonathan Warrell Wen-Yan Lin Shuai Zheng Vibhav Vineet Nigel Crook Vision Group, Oxford Brookes University Abstract Detecting
CSE Introduction to High-Perfomance Deep Learning ImageNet & VGG. Jihyung Kil
 CSE 5194.01 - Introduction to High-Perfomance Deep Learning ImageNet & VGG Jihyung Kil ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
CSE 5194.01 - Introduction to High-Perfomance Deep Learning ImageNet & VGG Jihyung Kil ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
SALIENCY refers to a component (object, pixel, person) in a
 in a") 1 Personalized Saliency and Its Prediction Yanyu Xu *, Shenghua Gao *, Junru Wu *, Nianyi Li, and Jingyi Yu arxiv:1710.03011v2 [cs.cv] 16 Jun 2018 Abstract Nearly all existing visual saliency models by
1 Personalized Saliency and Its Prediction Yanyu Xu *, Shenghua Gao *, Junru Wu *, Nianyi Li, and Jingyi Yu arxiv:1710.03011v2 [cs.cv] 16 Jun 2018 Abstract Nearly all existing visual saliency models by
Beyond R-CNN detection: Learning to Merge Contextual Attribute
 Brain Unleashing Series - Beyond R-CNN detection: Learning to Merge Contextual Attribute Shu Kong CS, ICS, UCI 2015-1-29 Outline 1. RCNN is essentially doing classification, without considering contextual
Brain Unleashing Series - Beyond R-CNN detection: Learning to Merge Contextual Attribute Shu Kong CS, ICS, UCI 2015-1-29 Outline 1. RCNN is essentially doing classification, without considering contextual
arxiv: v1 [cs.cv] 24 Jul 2018
![arxiv: v1 [cs.cv] 24 Jul 2018](/thumbs/82/86822918.jpg "arxiv: v1 [cs.cv] 24 Jul 2018") Multi-Class Lesion Diagnosis with Pixel-wise Classification Network Manu Goyal 1, Jiahua Ng 2, and Moi Hoon Yap 1 1 Visual Computing Lab, Manchester Metropolitan University, M1 5GD, UK 2 University of
Multi-Class Lesion Diagnosis with Pixel-wise Classification Network Manu Goyal 1, Jiahua Ng 2, and Moi Hoon Yap 1 1 Visual Computing Lab, Manchester Metropolitan University, M1 5GD, UK 2 University of
Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval Tasks
 Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval Tasks Haomiao Liu 1,2, Ruiping Wang 1,2,3, Shiguang Shan 1,2,3, Xilin Chen 1,2,3 1 Key Laboratory of Intelligent
Learning Multifunctional Binary Codes for Both Category and Attribute Oriented Retrieval Tasks Haomiao Liu 1,2, Ruiping Wang 1,2,3, Shiguang Shan 1,2,3, Xilin Chen 1,2,3 1 Key Laboratory of Intelligent
ITERATIVELY TRAINING CLASSIFIERS FOR CIRCULATING TUMOR CELL DETECTION
 ITERATIVELY TRAINING CLASSIFIERS FOR CIRCULATING TUMOR CELL DETECTION Yunxiang Mao 1, Zhaozheng Yin 1, Joseph M. Schober 2 1 Missouri University of Science and Technology 2 Southern Illinois University
ITERATIVELY TRAINING CLASSIFIERS FOR CIRCULATING TUMOR CELL DETECTION Yunxiang Mao 1, Zhaozheng Yin 1, Joseph M. Schober 2 1 Missouri University of Science and Technology 2 Southern Illinois University
Concepts and Categories
 Concepts and Categories Functions of Concepts By dividing the world into classes of things to decrease the amount of information we need to learn, perceive, remember, and recognise: cognitive economy They
Concepts and Categories Functions of Concepts By dividing the world into classes of things to decrease the amount of information we need to learn, perceive, remember, and recognise: cognitive economy They
Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination
 Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination Timothy N. Rubin (trubin@uci.edu) Michael D. Lee (mdlee@uci.edu) Charles F. Chubb (cchubb@uci.edu) Department of Cognitive
Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination Timothy N. Rubin (trubin@uci.edu) Michael D. Lee (mdlee@uci.edu) Charles F. Chubb (cchubb@uci.edu) Department of Cognitive
Neural Coding. Computing and the Brain. How Is Information Coded in Networks of Spiking Neurons?
 Neural Coding Computing and the Brain How Is Information Coded in Networks of Spiking Neurons? Coding in spike (AP) sequences from individual neurons Coding in activity of a population of neurons Spring
Neural Coding Computing and the Brain How Is Information Coded in Networks of Spiking Neurons? Coding in spike (AP) sequences from individual neurons Coding in activity of a population of neurons Spring
Salient Object Detection in RGB-D Image Based on Saliency Fusion and Propagation
 Salient Object Detection in RGB-D Image Based on Saliency Fusion and Propagation Jingfan Guo,, Tongwei Ren,,, Jia Bei,, Yujin Zhu State Key Laboratory for Novel Software Technology, Nanjing University,
Salient Object Detection in RGB-D Image Based on Saliency Fusion and Propagation Jingfan Guo,, Tongwei Ren,,, Jia Bei,, Yujin Zhu State Key Laboratory for Novel Software Technology, Nanjing University,
Towards Open Set Deep Networks: Supplemental
 Towards Open Set Deep Networks: Supplemental Abhijit Bendale*, Terrance E. Boult University of Colorado at Colorado Springs {abendale,tboult}@vast.uccs.edu In this supplement, we provide we provide additional
Towards Open Set Deep Networks: Supplemental Abhijit Bendale*, Terrance E. Boult University of Colorado at Colorado Springs {abendale,tboult}@vast.uccs.edu In this supplement, we provide we provide additional
A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE.
 A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE Robert LAURINI, Claude Bernard University of Lyon France A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE 1 - Introduction 2 - Auditory
A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE Robert LAURINI, Claude Bernard University of Lyon France A PROTOTYPE OF AN INFORMATION SYSTEM FOR URBAN SOUNDSCAPE 1 - Introduction 2 - Auditory
Fine-Grained Image Classification Using Color Exemplar Classifiers
 Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, and Qingming Huang 1,4 1 School of Computer and Control Engineering,
Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, and Qingming Huang 1,4 1 School of Computer and Control Engineering,
Exploiting saliency for object segmentation from image level labels
 Exploiting saliency for object segmentation from image level labels Seong Joon Oh Rodrigo Benenson Anna Khoreva joon@mpi-inf.mpg.de benenson@mpi-inf.mpg.de khoreva@mpi-inf.mpg.de, Zeynep Akata Z.Akata@uva.nl
Exploiting saliency for object segmentation from image level labels Seong Joon Oh Rodrigo Benenson Anna Khoreva joon@mpi-inf.mpg.de benenson@mpi-inf.mpg.de khoreva@mpi-inf.mpg.de, Zeynep Akata Z.Akata@uva.nl
Annotation and Retrieval System Using Confabulation Model for ImageCLEF2011 Photo Annotation
 Annotation and Retrieval System Using Confabulation Model for ImageCLEF2011 Photo Annotation Ryo Izawa, Naoki Motohashi, and Tomohiro Takagi Department of Computer Science Meiji University 1-1-1 Higashimita,
Annotation and Retrieval System Using Confabulation Model for ImageCLEF2011 Photo Annotation Ryo Izawa, Naoki Motohashi, and Tomohiro Takagi Department of Computer Science Meiji University 1-1-1 Higashimita,
arxiv: v2 [cs.cv] 7 Jun 2018
![arxiv: v2 [cs.cv] 7 Jun 2018](/thumbs/79/79761281.jpg "arxiv: v2 [cs.cv] 7 Jun 2018") Deep supervision with additional labels for retinal vessel segmentation task Yishuo Zhang and Albert C.S. Chung Lo Kwee-Seong Medical Image Analysis Laboratory, Department of Computer Science and Engineering,
Deep supervision with additional labels for retinal vessel segmentation task Yishuo Zhang and Albert C.S. Chung Lo Kwee-Seong Medical Image Analysis Laboratory, Department of Computer Science and Engineering,
1 Pattern Recognition 2 1
 1 Pattern Recognition 2 1 3 Perceptrons by M.L. Minsky and S.A. Papert (1969) Books: 4 Pattern Recognition, fourth Edition (Hardcover) by Sergios Theodoridis, Konstantinos Koutroumbas Publisher: Academic
1 Pattern Recognition 2 1 3 Perceptrons by M.L. Minsky and S.A. Papert (1969) Books: 4 Pattern Recognition, fourth Edition (Hardcover) by Sergios Theodoridis, Konstantinos Koutroumbas Publisher: Academic
arxiv: v1 [cs.cv] 16 Jun 2012
![arxiv: v1 [cs.cv] 16 Jun 2012](/thumbs/74/70143056.jpg "arxiv: v1 [cs.cv] 16 Jun 2012") How important are Deformable Parts in the Deformable Parts Model? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Carnegie Mellon University arxiv:1206.3714v1 [cs.cv] 16 Jun 2012 Abstract. The main
How important are Deformable Parts in the Deformable Parts Model? Santosh K. Divvala, Alexei A. Efros, Martial Hebert Carnegie Mellon University arxiv:1206.3714v1 [cs.cv] 16 Jun 2012 Abstract. The main
Fine-Grained Image Classification Using Color Exemplar Classifiers
 Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, Qingming Huang 1, 4 1 School of Computer and Control Engineering,
Fine-Grained Image Classification Using Color Exemplar Classifiers Chunjie Zhang 1, Wei Xiong 1, Jing Liu 2, Yifan Zhang 2, Chao Liang 3, Qingming Huang 1, 4 1 School of Computer and Control Engineering,
Nature Neuroscience: doi: /nn Supplementary Figure 1. Behavioral training.
 Supplementary Figure 1 Behavioral training. a, Mazes used for behavioral training. Asterisks indicate reward location. Only some example mazes are shown (for example, right choice and not left choice maze
Supplementary Figure 1 Behavioral training. a, Mazes used for behavioral training. Asterisks indicate reward location. Only some example mazes are shown (for example, right choice and not left choice maze
Family Member Identification from Photo Collections
 2015 IEEE Winter Conference on Applications of Computer Vision Family Member Identification from Photo Collections Qieyun Dai 1,2 Peter Carr 2 Leonid Sigal 2 Derek Hoiem 1 1 University of Illinois at Urbana-Champaign
2015 IEEE Winter Conference on Applications of Computer Vision Family Member Identification from Photo Collections Qieyun Dai 1,2 Peter Carr 2 Leonid Sigal 2 Derek Hoiem 1 1 University of Illinois at Urbana-Champaign