VISUAL search is necessary for rapid scene analysis
|
|
|
- June Greene
- 5 years ago
- Views:
Transcription



 demonstrate that our system achieves competitive performance for SS detection (i.")



![[4]. Manuscript received July 28, 2015; revised December 20, 2015 and May 17, 2016; accepted May 21, 2016. Date of publication May 24, 2016; date of current version June 14, 2016.](/docs-images/96/128308915/images/1-7.jpg "This work was supported in part by the Major State Basic Research Program under Grant 2013CB329401 and in part by the National Natural Science Foundation of China under Grant 61375115 and Grant")
1 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST A Unified Framework for Salient Structure Detection by Contour-Guided Visual Search Kai-Fu Yang, Hui Li, Chao-Yi Li, and Yong-Jie Li, Member, IEEE Abstract We define the task of salient structure (SS) detection to unify the saliency-related tasks, such as fixation prediction, salient object detection, and detection of other structures of interest in cluttered environments. To solve such SS detection tasks, a unified framework inspired by the two-pathway-based search strategy of biological vision is proposed in this paper. First, a contour-based spatial prior (CBSP) is extracted based on the layout of edges in the given scene along a fast non-selective pathway, which provides a rough, task-irrelevant, and robust estimation of the locations where the potential SSs are present. Second, another flow of local feature extraction is executed in parallel along the selective pathway. Finally, Bayesian inference is used to auto-weight and integrate the local cues guided by CBSP and to predict the exact locations of SSs. This model is invariant to the size and features of objects. The experimental results on six large datasets (three fixation prediction datasets and three salient object datasets) demonstrate that our system achieves competitive performance for SS detection (i.e., both the tasks of fixation prediction and salient object detection) compared with the state-of-the-art methods. In addition, our system also performs well for salient object construction from saliency maps and can be easily extended for salient edge detection. Index Terms Visual search, fixation, salient object, salient edge, salient structure detection, Bayesian inference. I. INTRODUCTION VISUAL search is necessary for rapid scene analysis in daily life because information processing in the visual system is limited to one or a few targets or regions at one time [1]. To select potential regions or objects of interest rapidly in a task-independent manner, the so-called visual saliency is important for reducing the complexity of scene analysis. From the perspective of engineering, modeling visual saliency usually facilitates subsequent higher visual processing, such as image re-targeting [2], image compression [3], and object recognition [4]. Manuscript received July 28, 2015; revised December 20, 2015 and May 17, 2016; accepted May 21, Date of publication May 24, 2016; date of current version June 14, This work was supported in part by the Major State Basic Research Program under Grant 2013CB and in part by the National Natural Science Foundation of China under Grant and Grant The associate editor coordinating the review of this manuscript and approving it for publication was Prof. Weisi Lin. (Corresponding author: Yong-Jie Li.) K.-F. Yang, H. Li, and Y.-J. Li are with the Key Laboratory of Neuroinformation of Ministry of Education, University of Electronic Science and Technology of China, Chengdu , China ( yang_kf@163.com; li_hui_2015@163.com; liyj@uestc.edu.cn). C.-Y. Li is with the School of Life Science and Technology, University of Electronic Science and Technology of China, Chengdu , China, and also with the Center for Life Sciences, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai , China ( cyli@sibs.ac.cn). Color versions of one or more of the figures in this paper are available online at Digital Object Identifier /TIP Fig. 1. Compared with the tasks of fixation prediction (b) and salient object detection (c), our salient structure detection (d) aims to extract interesting structures from both complex and simple scenes (a). This paper introduces several saliency-related concepts that need to be first clarified. (1) Fixations are usually related to human fixating points recorded by eye-tracker. Human fixations are usually used as the ground truth to benchmark fixation prediction methods. (2) Regions of Interest (ROIs) represent some regions containing interesting information, in which clear objects cannot be easily segregated from others. Although benchmarked on human fixations, fixation prediction methods usually obtain smoothed ROIs of scene, and Regions of Interest and Saliency Map are interchangeable when describing the output of fixation prediction methods [5]. (3) Salient Objects are specific dominant objects (e.g., animals, people, cars, etc.) in natural scenes, and, in general, salient object detection requires labeling pixel-accurate object silhouettes [6]. (4) Salient Edges are only the edges of salient objects [7]. In contrast, we propose a new model for Salient Structure (SS) detection, a more general term defined as the task of detecting the accurate regions containing structures of interest (e.g., ROIs, salient objects, salient edges, etc.) in a scene. This means that such a task aims to detect the ROIs in cluttered scenes and identify dominant objects in simple scenes. Fig. 1 shows two examples of SS detection. Fixation prediction methods (e.g., IT [5]) usually focus on high-contrast boundaries, but ignore object surfaces and shapes (Fig. 1b). In contrast, salient object detection models (e.g., HS [8]) may be inefficient for ROI detection in complex scenes without dominant objects (Fig. 1c). The proposed method is designed to extract SSs for both simple and complex scenes (Fig. 1d). It is widely accepted that visual attention is influenced by both the bottom-up mechanism that processes the input visual scene and the top-down mechanism that introduces the visual knowledge about the scene and (or) the target [9]. Among the various theories explaining the biological mechanisms of integration between bottom-up and top-down information [9], [10], Feature Integration Theory (FIT) [11], [12], Guided Search Theory (GST) [1], [13] IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See for more information.
2 3476 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 and Biased Competition Theory (BCT) [14] are three influential theories. Explicitly or implicitly inspired by these visual attention theories, computational modeling of visual searching is gaining increasing attention, mainly aiming for fixation prediction [15] or salient object detection [16]. Note that in this paper we use the term fixation prediction to unify the computational tasks of attention models and eye movement prediction models because both of these models are often validated against eye movement data although the two types of models have slight differences in scope and approaches [15]. Most of the existing fixation prediction models are built on the biologically-inspired architecture based on the famous FIT [11], [12]. For instance, Itti et al. proposed a famous FIT-inspired saliency model that computes the saliency map with local contrast in multiple feature dimensions, such as color, orientation, etc. [5], [17]. However, FIT-based methods may risk being immersed in local saliency (e.g., object boundaries) because they employ local contrast of features in limited regions and ignore global information. In contrast to FIT, GST [1], [13] suggests visual mechanisms to search for ROIs or objects with the guidance from scene layout or top-down sources. The recent version of GST claims that the visual system searches for the objects of interest along two parallel pathways: the non-selective pathway and the selective pathway [1]. This strategy allows observers to extract spatial layout (or gist) information rapidly from the entire scene via the non-selective pathway. This global information of scene acts as top-down modulation to guide the salient object search in the selective pathway. This two-pathwaybased search strategy provides parallel processing of global and local information for rapid visual search. In our two-pathway-based contour-guided visual search (CGVS) framework, the contour-represented layout in the non-selective pathway is used as the initial guidance to estimate the location and sizes of ROIs and the relative importance of low-level local cues. In contrast, the local cues (e.g., color, luminance, texture, etc.) are extracted in parallel along the selective pathway. Finally, Bayesian inference is used to integrate the contour-based spatial prior (CBSP) and the local cues to predict the saliency of each pixel. The salient structures are further enhanced via iterative processing to refine the prior guidance as the final prediction. The proposed system attempts to bridge the gap between the two highly related tasks of human fixation prediction [15] and salient object detection [16], with a general framework. Extensive evaluations demonstrate that our model can handle both tasks well without specific tuning. In addition, the proposed method can efficiently transform the saliency maps of fixation prediction methods to salient objects. Furthermore, we apply our system for other saliency related tasks, such as salient edge detection. Our experiments show that the proposed system can be flexibly extended for related tasks. To summarize the above, this work draws its inspiration directly from the biological visual search theory, and the contributions of the proposed model are as follows. (1) We define a new task called salient structure (SS) detection to unify various saliency-related tasks, including fixation prediction, salient object detection, and salient edge extraction. (2) We propose a unified framework for SS detection inspired by Guided Search Theory. (3) A simple yet efficient filling-in operation is implemented to create the global layout used for location prior of potential salient structures. (4) Simple yet robust methods are proposed to automatically define the sizes of potential salient structures and estimate the weight of each bottom-up feature. (5) The proposed system also provides an efficient way for transforming saliency maps (outputted from any model) to salient objects and multi-object searches. II. RELATED WORK A. Fixation Prediction As mentioned above, the existing fixation prediction models aim to compute Saliency Maps to indicate the ROIs where human fixations locate [15], [18]. Ever since Koch and Ullman [12] proposed the concept of the saliency map and Itti et al. [5] proposed their model, many fixation prediction methods have been proposed to predict human fixations with a bottom-up framework [15], [19]. Some typical methods along this line include Graph-based (GB) [20], Information Maximization (AIM) [21], Image Signature (SIG) [22], Adaptive Whitening Saliency (AWS) [23], Local and Global Patch Rarities [24], and Earth Mover s Distance-Based Saliency Measurement and Nonlinear Feature Combination for static and dynamic saliency maps [25], [26]. Frequency domain based models include Spectral Residual (SR) [27], Phase spectrum of Quaternion Fourier Transform (PQFT) [28], [29], and Hypercomplex Fourier Transform (HFT) [30]. In addition, machine learning techniques have also been introduced to improve the performance of fixation prediction. In these models, both bottom-up and top-down visual features are learnt to predict salient locations [31], [32]. In general, interesting objects (such as humans, faces, cars, text, animals, etc.) convey more information in a scene, and they usually attract more human gaze [33] [36]. Task-related top-down information is also commonly used [37] [40]. Some models also learn optimal weights for channel combination in the bottom-up architecture [41], and nonparametric saliency models learn directly from human eye movement data [42]. In addition to scene context, the observer s current task also exerts dominant top-down control of visual attention [43]. This makes the investigation on the role of top-down guidance along two lines: 1) goal directed, task-driven control and 2) scene contextual information directed, task-irrelevant control. Zhang et al. [44] proposed a Bayesian framework for saliency computation using the statistics of natural images. Torralba et al. [45], [46] used global features to guide object search by summarizing the probability regions of presence of target objects in the scene. Itti and Baldi [47] proposed the Bayesian definition of surprise by measuring the difference between posterior and prior beliefs of the observer. Lu et al. computed saliency map from image Co-Occurrence histograms [48]. Fixation prediction models usually provide smoothing regions of interest rather than uniform regions highlighting the
![YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3477 entire salient objects [16].](/docs-images/96/128308915/images/3-0.jpg "Though fixation points indicate the location information of the potential objects but miss some object-related information (e.g., object shapes and surfaces) that is necessary for further high-level tasks such as object detection and recognition.")
![B. Salient Object Detection To accurately extract the dominant objects from natural scenes, Liu et al. [49] formulated the salient object detection as a binary labeling problem. Achanta et al.](/docs-images/96/128308915/images/3-1.jpg "[6] further claimed that salient object detection requires labeling pixel-accurate object silhouettes.")
![Most of the existing methods attempt to detect the most salient object based on local or global region contrast [8], [50] [52]. For example, Cheng et al.](/docs-images/96/128308915/images/3-2.jpg "[50] proposed a region-based method for salient object detection by measuring the global contrast between the target and other regions.")
![Other methods include center-surround contrasts with Kullback-Leiblar [53], background prior [54], [55], etc.](/docs-images/96/128308915/images/3-3.jpg "Salient object detection is also highly related to another task called object proposal, which attempts to generate a set of all objects in the scene, regardless of the specific saliency of these")
![objects [56] [58].](/docs-images/96/128308915/images/3-4.jpg "Recent advances reveal that the state-ofthe-art models can produce excellent results when evaluated using the traditional benchmark images containing a clear, unambiguous object of interest [16].")
![However, when facing randomly-selected images (e.g., from the Internet), there is still a strong need to develop more robust methods [50].](/docs-images/96/128308915/images/3-5.jpg "For attentional modeling, Bayesian inference seems a reasonable tool for combining visual evidence with prior constraints by taking advantage of the statistics of natural scenes or other features")
3 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3477 entire salient objects [16]. Though fixation points indicate the location information of the potential objects but miss some object-related information (e.g., object shapes and surfaces) that is necessary for further high-level tasks such as object detection and recognition. B. Salient Object Detection To accurately extract the dominant objects from natural scenes, Liu et al. [49] formulated the salient object detection as a binary labeling problem. Achanta et al. [6] further claimed that salient object detection requires labeling pixel-accurate object silhouettes. Most of the existing methods attempt to detect the most salient object based on local or global region contrast [8], [50] [52]. For example, Cheng et al. [50] proposed a region-based method for salient object detection by measuring the global contrast between the target and other regions. Other methods include center-surround contrasts with Kullback-Leiblar [53], background prior [54], [55], etc. Salient object detection is also highly related to another task called object proposal, which attempts to generate a set of all objects in the scene, regardless of the specific saliency of these objects [56] [58]. Recent advances reveal that the state-ofthe-art models can produce excellent results when evaluated using the traditional benchmark images containing a clear, unambiguous object of interest [16]. However, when facing randomly-selected images (e.g., from the Internet), there is still a strong need to develop more robust methods [50]. For attentional modeling, Bayesian inference seems a reasonable tool for combining visual evidence with prior constraints by taking advantage of the statistics of natural scenes or other features that attract attention. In fact, many physiological experiments and computational analyses strongly suggest that attentional modulation in the biological visual system may arise as a consequence of Bayesian inference in cortical networks [10], [44], [47], [59], [60]. The biological plausibility of Bayesian inference inspires us to adopt it to combine the contour-based guidance and bottom-up features. A related model is proposed by Xie et al. [61], who employ Bayesian inference for saliency computation, with the help of prior information estimated using the convex hull of Harris points and a Laplacian sparse subspace clustering algorithm. Unlike their method, our method obtains the spatial prior information in a much simpler way. The contour-based information in our model is used to identify the sizes of potential objects and the importance of local cues. In addition, our model provides a unified framework for various saliency-related tasks (including fixation prediction, salient object detection and salient edge extraction), termed Salient Structure Detection in the present study (see Fig. 1). C. Bridging the Two Tasks More recently, several authors attempted to bridge the gap between the two tasks of fixation prediction and salient object detection. Typically, Goferman et al. [2] proposed a contextaware saliency algorithm to detect both prominent objects and the parts of the background that convey the context. Li et al. [18] trained a random regression forest to extract Fig. 2. The flowchart of the proposed system with selective and non-selective pathways. salient regions based on an image segmentation method. In comparison to [2], our method can obtain more reasonable salient structures with accurate object silhouettes and object surfaces. Compared with [18], the proposed model is capable of handling the task of salient structure detection in both simple and complex scenes without foregone computation such as image segmentation. A method based on Boolean Map was originally proposed for fixation prediction [62] but could also be used for salient object detection by adding specific tuning and post-processing. The recent method proposed by Cheng et al. [50], which targets salient object detection, is also capable of obtaining acceptable performance for fixation prediction by adjusting their model s implementation. In contrast, our method can achieve both tasks without the need for specific tuning. III. CONTOUR-GUIDED VISUAL SEARCH MODEL In general, contours or boundaries help to segment an image into various perceptional regions (before the perception of specific objects) that may be used by the visual system to rapidly construct a rough sketch of the image structure in space [63]. In addition, contours (shapes) lead to perceptual saliency of different geometrical properties, which have been strongly proven to contribute to early global topological perception [64]. Furthermore, physiological evidence shows that the global contours delineating the outlines of visual objects may respond quite early (perhaps via a special pathway) through the neurons of high cortexes, which, although producing only a crude signal about the position and shape of the objects, can provide sufficient feedback modulation that enhances contour-related responses at lower levels and suppresses irrelevant background input [65]. These facts inspired us to detect salient stuctures guided by dominant edges. The flowchart of the proposed method is summarized in Fig. 2. The possible locations of potential salient structures are estimated with the distribution of dominant edges in the non-selective pathway. Meanwhile, the local features such as color, luminance, and texture are extracted from the given scene in the selective pathway. The contour-based spatial prior (CBSP) information is fed into the Bayesian framework for feature integration and salient structure prediction. Finally, the
![3478 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 of d r. S e and S c are linearly normalized to the range of [0, 1]. Then, the final CBSP is given by S w = S e + S c (1) Fig. 3.](/docs-images/96/128308915/images/4-0.jpg "Example of reconstructing the potential saliency regions based on the dominant edges. Left: the input image. Middle: the dominant edges shown in red lines.")

, and some isolated and high-contrast edges (e.")

![Some authors have proposed that boundaries are a type of useful information that can be used to block the lateral spreading or diffusion in visual perception and achieve filling-in of surfaces [68],](/docs-images/96/128308915/images/4-4.jpg "[69]. This inspires us to build a new implementation of filling-in for the computation of Contour-based Spatial Prior (CBSP) based on the dominant contours.")
![In detail, we first extract the edge responses and the corresponding orientations using the edge detector proposed in [70], which is a biologically-inspired method and can efficiently detect both](/docs-images/96/128308915/images/4-5.jpg "color- and brightness-defined dominant boundaries from cluttered scenes. Fig. 3 shows an example of reconstructing CBSP.")


) to speed up the computation. We denote the rough spatial weights of saliency as S e.")
![In addition, we also consider the widely-used center-bias weighting [31], [71] (denoted by S c ), which is simply modeled by a Gaussian mask with the standard deviation as σ c = min(w, H )/3, based](/docs-images/96/128308915/images/4-9.jpg "on a similar consideration with that S w is also linearly normalized to the range of [0, 1] for later used as the prior probability. B.")
 and the two color-opponent channels ( f rg and f by ) are obtained as f lum = (r + g + b)/3 (2)")
![f rg = r g (3) f by = b (r + g)/2 (4) Note that these three basic channels are smoothed with a Gaussian filter with the same scale as that used in our edge detector [70] to remove noise.](/docs-images/96/128308915/images/4-11.jpg "In addition, considering that texture can reflect more complicated properties of image regions, we added a texture channel for a better representation of potential salient structures.")

4 3478 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 of d r. S e and S c are linearly normalized to the range of [0, 1]. Then, the final CBSP is given by S w = S e + S c (1) Fig. 3. Example of reconstructing the potential saliency regions based on the dominant edges. Left: the input image. Middle: the dominant edges shown in red lines. For each edge pixel, the averaged edge responses in the left and right half disks around it are compared to decide which half is located in the salient region. Right: the potential saliency regions. output of the Bayesian framework is used as new spatial prior to refine the salient structures with an iterative procedure. A. Contour-Based Spatial Prior (CBSP) In the non-selective pathway, we compute the rough spatial weights of saliency based on the distribution of the dominant edges. In fact, edge information has been widely used for saliency computation [5], [66]. However, it is difficult to use these methods to provide regional information (e.g., object surfaces), and some isolated and high-contrast edges (e.g., the boundary between two large surfaces) may be incorrectly evaluated as high saliency. In this paper, we roughly identify the potential salient regions with a visual filling-in-like operation [67] based on the dominant contours. Some authors have proposed that boundaries are a type of useful information that can be used to block the lateral spreading or diffusion in visual perception and achieve filling-in of surfaces [68], [69]. This inspires us to build a new implementation of filling-in for the computation of Contour-based Spatial Prior (CBSP) based on the dominant contours. In detail, we first extract the edge responses and the corresponding orientations using the edge detector proposed in [70], which is a biologically-inspired method and can efficiently detect both color- and brightness-defined dominant boundaries from cluttered scenes. Fig. 3 shows an example of reconstructing CBSP. For each edge pixel, we compute the average edge response (AER) in the left and right half disk around it. The disk is defined by the orientation of each edge pixel, with a radius of d r. Considering the fact that radius d r would be strongly dependent on the image size, viewing distance, etc., we select d r as a relative value of image size instead of an absolute value. In this work, we experimentally set d r = min(w, H )/3, where W and H indicate the width and height of the given image, respectively. Then, all of the pixels within the half disk having stronger AER between two half disks are voted 1, and the pixels in the other half are voted 0. For each pixel, its saliency weight is represented by the number of votes when all of the edge pixels finish their voting. We only scan the dominant edges (i.e., the ridges, red pixels in Fig. 3(middle)) to speed up the computation. We denote the rough spatial weights of saliency as S e. In addition, we also consider the widely-used center-bias weighting [31], [71] (denoted by S c ), which is simply modeled by a Gaussian mask with the standard deviation as σ c = min(w, H )/3, based on a similar consideration with that S w is also linearly normalized to the range of [0, 1] for later used as the prior probability. B. Low-Level Feature Extraction In the selective pathway, basic low-level features including color, luminance and texture are extracted in parallel. With r, g,andb denoting the red, green, and blue components of the input image, the luminance ( f lum ) and the two color-opponent channels ( f rg and f by ) are obtained as f lum = (r + g + b)/3 (2) f rg = r g (3) f by = b (r + g)/2 (4) Note that these three basic channels are smoothed with a Gaussian filter with the same scale as that used in our edge detector [70] to remove noise. In addition, considering that texture can reflect more complicated properties of image regions, we added a texture channel for a better representation of potential salient structures. In this work, the texture channel ( f ed ) is represented by the information of edge density (ED), which reflects the contrast of local patches, because some authors have claimed that local luminance and luminance contrast are independent or weakly dependent with each other in the early visual system and in natural scenes [72], [73], although inconsistent conclusions have also been reported [74]. f ed is computed by smoothing the edge responses (the same as used in the non-selective pathway, Section III-A) with an average filter of pixels. C. Bayesian Inference With Contour Guidance In this paper, we employ the tool of Bayesian inference to adaptively integrate the global CBSP and the local features, simulating the interaction of top-down and bottom-up information processing flows in the selective visual attention. With Bayesian inference, the possibility of a pixel at x belonging to a salient structure s (posterior probability), p(s x), can be computed as p(s x) = p(s) p(x s) p(s) p(x s) + p(b) p(x b) where p(s) and p(b) = 1 p(s) are the prior probabilities of a pixel at x belonging to a salient structure and the background, respectively. p(x s) and p(x b) are likelihood functions based on the observed salient structure and the background, respectively. In this work, we set the CBSP as the initial prior probability, i.e., p(s) = S w. The observation likelihood p(x s) and p(x b) will be evaluated according to each scene context, including the possible sizes of salient structures and the relative importance of each feature. The implementation details are as follows. (5)
 Predict the Size of Potential Structure: To obtain p(x s) and p(x b), the observation likelihood of the observed objects")
) with an adaptive threshold to capture rough potential regions of structures and their sizes.")


 to avoid fragments.")
![This assumption is supported by a simple experiment on two popular salient object datasets: the mean sizes (percentage) of salient objects are 20.01% on ASD [6] and 28.51% on ECSSD datasets [8].](/docs-images/96/128308915/images/5-7.jpg "The influence on images with smaller and larger objects is discussed in Section IV-F.")
5 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH ) Predict the Size of Potential Structure: To obtain p(x s) and p(x b), the observation likelihood of the observed objects and background, we first extract the possible regions containing structures from the background. Simply, we binarize the map of prior probability ( p(s)) with an adaptive threshold to capture rough potential regions of structures and their sizes. We use S Tk and B Tk to denote the pixel sets of structure and background obtained by binarizing p(s) with a threshold T k. The optimal threshold T opt is found by searching for a possible T k that maximizes the difference of all of the features between the structure and background pixel sets according to T opt = arg max T k i ( ω 0 i ( S i Tk B i Tk )) 2 (6) where S T i k and B T i k denote the mean values of the structure and background pixels, respectively, in feature channel i, i {f lum, f rg, f by, f ed }. The initial feature weight is wi 0 = 0.25, which indicates the equal importance of each cue at the initial status. T k {10%, 12%, 14%,...,50%} indicates the percentage of pixels of the potential salient structures. This suggests a potential assumption that salient structures are usually smaller than half of the image. We ignore the regions with fine scales (<10%) to avoid fragments. This assumption is supported by a simple experiment on two popular salient object datasets: the mean sizes (percentage) of salient objects are 20.01% on ASD [6] and 28.51% on ECSSD datasets [8]. The influence on images with smaller and larger objects is discussed in Section IV-F. 2) Evaluate the Importance of Each Feature: After finding the potential salient and background pixel sets for each feature map based on the optimal threshold T opt, we re-evaluate the importance of each feature as ω i = 1 μ S T i opt B T i opt (7) where μ = i ω i, i {f lum, f rg, f by, f ed }. Equation (7) indicates that a feature will have higher importance when the difference of mean pixel values between the salient structure and background is larger in this channel. 3) Calculate the Observation Likelihood: We then compute the observation likelihood p(x s) and p(x b) with the potential object and background pixel sets and the weight of each feature. We assume that the four feature channels are independent to simplify the estimation of the joint probability distribution of various features. Note that this is a bold assumption. Though there are certainly interactions between the channels of texture and color contrast [75], the independence of luminance vs. contrast and luminance vs. color are still controversial [72] [74], [76]. Nevertheless, this bold assumption proves acceptable for practical applications, such as the famous Naive Bayes Classifier in machine learning [61], [77], [78]. Thus, the observation likelihood at pixel x can be computed as ( ωi p(x s) = p(x i S Topt )) (8) p(x b) = i { f lum, f rg, f by, f ed } i { f lum, f rg, f by, f ed } ( p(x i B Topt )) ωi (9) Fig. 4. Examples illustrating that our system automatically selects the size of potential salient structure and estimates the importance of each local feature. The object mask in (c) is obtained by thresholding the CBSP in (b) with the currently optimal threshold (i.e., the percentage value shown in (c)). where p(x i S Topt ) and p(x i B Topt ) are respectively the distribution functions of each feature (i {f lum, f rg, f by, f ed }) in the salient structure and background sets. We simplify the computation of the observation likelihood of each feature based on the normalized histogram of pixels in salient or background sets in each feature channel. Specifically, p(x i S Topt ) is computed as N(x i )/N(S Topt ),wheren(x i ) is the number of points in various disjoined bins containing feature x i in the region of S Topt,andN(S Topt ) is the total pixel number in the region of S Topt. p(x i B Topt ) is computed similarly. ω i indicates the contribution of the distribution function of the i th feature, which will be iteratively modified as follows. Finally, p(s x) is computed using (5) as the saliency of each pixel. 4) Enhance the Salient Structure by Iterating: We further enhance the salient structures iteratively by re-initializing the prior function with p(s) p(s x) and the feature weights as ω 0 i ω i. In the experiment, we re-initialize the prior function with the smoothed version of p(s x) (by median filtering with a size of pixels) to remove small fragments. Finally, we denote CGVS(t), t = t 0, t 1,...,t n as our contourguided visual search model with various iterations (t), and the CGVS(t 0 ) is the first step s output without iteration. IV. EXPERIMENTS We first show the basic properties of our system in scene analysis. Then the proposed method is evaluated on both fixation prediction datasets [30], [31], [79] and salient object detection datasets [6], [8], [18]. In addition, we demonstrate that with the proposed system, fixation prediction methods can be significantly improved for the task of salient object detection. Our system is also tested to demonstrate that the proposed method can be easily extended for general salient structure detection. Finally, we exploit the influence of model parameters on detection performance. A. Basic Property of the Proposed Model To clearly demonstrate how the proposed system works, we first show several of its basic properties, including: (1) automatic selection of the sizes of potential salient structures and the relative importance (i.e., weight) of each feature, (2) the ability to search for objects in multi-object scenes, and (3) the contribution of iterative processing.

![For an input image, we first obtain the smoothed saliency map (e.g., using Itti s method [5]), which contains several regions of interest (ROIs).](/docs-images/96/128308915/images/6-1.jpg "The most salient location (ROI 1) is extract using winner-take-all mechanisms (step 1 ), and then the first object")
, i.e., removing the scanned locations (step 3 ).")

, our system can automatically select the spatial sizes of potential objects in the given scene and roughly")
) with certain threshold values.")
 and (9).")
) is obtained using Bayesian inference. Fig. 4(e) lists the weights of all of the features.")





![The bottom row of Fig. 5 shows the classical shift of focus of attention modeled using the method of Itti et al. [5].](/docs-images/96/128308915/images/6-13.jpg "Compared to Itti s model, our system further extracts the full structure (the top row) from each attended location")




 Original image, (b) CBSP, (c)-(e) Results of our method at different iteration steps. is inaccurate.")
, the top row), the most salient location is on the head of the bear, and most parts of the bear s body are")


6 3480 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 Fig. 5. The procedure of object searching in a multi-object scene. For an input image, we first obtain the smoothed saliency map (e.g., using Itti s method [5]), which contains several regions of interest (ROIs). The most salient location (ROI 1) is extract using winner-take-all mechanisms (step 1 ), and then the first object is detected with the proposed system (step 2 ) with ROI 1 as the spatial prior. The inhibition-of-return mechanism is employed to search for the next salient location (ROI 2), i.e., removing the scanned locations (step 3 ). Repeating these procedures, our system can extract all of the objects one by one (the top row) from each attended location instead of the classical shift of focus in Itti s model [5]. Fig. 4 shows three examples including objects with different spatial scales. With (6), our system can automatically select the spatial sizes of potential objects in the given scene and roughly evaluate and identify the pixels of salient regions and background (Fig. 4(c)) by thresholding the CBSP (Fig. 4(b)) with certain threshold values. Then, the weight of each feature is computed with (7), and the observed likelihood functions of salient regions and background are evaluated with (8) and (9). Finally, the possibility of a pixel belonging to the salient structure (Fig. 4(d)) is obtained using Bayesian inference. Fig. 4(e) lists the weights of all of the features. We can clearly see that our system obtains reasonable evaluations about the size of salient structures and the importance of features of the input scene, which are important in searching for task-free interesting structures in cluttered scenes. In fact, this auto-weighting of different features is quite consistent with the guided search theory [1], [13], which proposes that visual search can be biased toward ROIs by modulating the relative weights through which different types of features contribute to attention adaptively. An additional experiment was executed to model the process of object searching in multiple object scenes. Fig. 5 shows the object searching procedure beginning with an initial saliency map. Based on the previous work of Itti et al. [5], the mechanisms of winner-take-all and inhibition-of-return were employed to search for the salient locations. The bottom row of Fig. 5 shows the classical shift of focus of attention modeled using the method of Itti et al. [5]. Compared to Itti s model, our system further extracts the full structure (the top row) from each attended location (the middle row). The objects were found one by one over the time course. In addition, our method provides the importance of each feature for each object, which is indicated by the histogram shown in Fig. 5 (the middle row). We believe that these extracted features with auto-defined weights are also useful for further computer vision applications such as object recognition. In addition, our model further re-evaluates the salient structures with new prior and feature weights to improve the confidence of salient structures. Fig. 6 shows two examples that illustrate that our system can always correctly identify the salient objects, although the initial CBSP (Fig. 6(b)) Fig. 6. Enhancing the salient structure in an iterative way. (a) Original image, (b) CBSP, (c)-(e) Results of our method at different iteration steps. is inaccurate. For example, in the bear image (Fig. 6(a), the top row), the most salient location is on the head of the bear, and most parts of the bear s body are missed in the initial CBSP. However, after two steps of iteration, our model detects the full bear while suppressing the background (Fig. 6(c)-(e)). It is also worth noting the different contributions of the nonselective pathway and selective pathway. When turning down the selective pathway, our model obtains the CBSP only along the non-selective pathway, which can be used for fixation prediction, as demonstrated in the following section. In contrast, when the non-selective pathway is turned down, the proposed framework would be reduced to a simple model if the Bayesian inference is replaced by a center-surround operation and linear combination, which would be quite similar to the classical bottom-up Itti (i.e., IT) model for fixation prediction. B. Fixation Prediction Fixation prediction methods are usually benchmarked on some available human fixation datasets [30], [31]. As a common metric for fixation prediction, Natural Scanpath Saliency (NSS) aims to measure the correspondence between the salience map and scanpath [80]. Basically, both NSS and the original version of ROC reflect the combined effect of the true positive rate and false positive rate [81]. To fairly evaluate the fixation prediction ability based on the saliency map produced by a salient object detection model (such as the proposed model), it seems more important to focus mainly on the true positive rate, for which the implementation version of ROC (AUC) in [31] is an appropriate choice, because it is insensitive to false positive rate [41]. Nevertheless, in this

 original images, (b) salient structure produced using the")
 Judd et al.")
![(Judd) [31], (d) Boolean map (BMS) [62], (e) Context-aware (CA)](/docs-images/96/128308915/images/7-3.jpg "[2], (f) Graph-Based (GB) [20], (g) Itti et al.")
![(IT) [5], and (h) Image Signature (SIG) [22].](/docs-images/96/128308915/images/7-4.jpg "Note that the red points on the CGVS maps indicate the human")


![(a) Judd et al. [31], (b) ImgSal [30], and (c) SALICON dataset [79].](/docs-images/96/128308915/images/7-7.jpg "Top: ROC curves for our method with various iteration steps,")

![model outperforms most of the methods and is comparable to GB [20].](/docs-images/96/128308915/images/7-9.jpg "Percent Salient denotes the percentage of the predicted saliency")
 in [31] to better understand the fixation prediction")

![[31] contains 1003 images and is widely used, whereas the dataset](/docs-images/96/128308915/images/7-12.jpg "collected by Li et al.")
![[30] contains 235 images with various sizes of regions of interest.](/docs-images/96/128308915/images/7-13.jpg "Moreover, a recent SALICON dataset (5000 images) [79], which")


, while ignoring the surfaces of salient structures.")




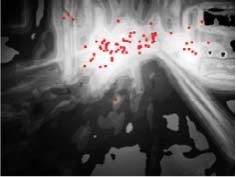
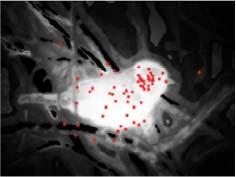

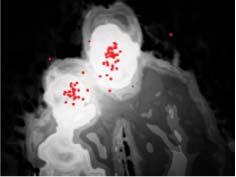
7 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3481 Fig. 7. Comparison of the fixation prediction results. (a) original images, (b) salient structure produced using the proposed method (CGVS) without the iterative processing, and saliency maps produced using multiple methods: (c) Judd et al. (Judd) [31], (d) Boolean map (BMS) [62], (e) Context-aware (CA) [2], (f) Graph-Based (GB) [20], (g) Itti et al. (IT) [5], and (h) Image Signature (SIG) [22]. Note that the red points on the CGVS maps indicate the human fixations (ground truth). It is clear that our CGVS generates uniformly highlighted salient structures that cover almost all of the human fixations. Fig. 8. Quantitative evaluation on three fixation prediction datasets. (a) Judd et al. [31], (b) ImgSal [30], and (c) SALICON dataset [79]. Top: ROC curves for our method with various iteration steps, showing that CGVS(t 0 ) obtains the best performance. Bottom: ROC curves for various algorithms, indicating that our model outperforms most of the methods and is comparable to GB [20]. Percent Salient denotes the percentage of the predicted saliency maps. section, we evaluated several datasets with both the NSS and the ROC (AUC) in [31] to better understand the fixation prediction performance of the proposed model. The dataset collected by Judd et al. [31] contains 1003 images and is widely used, whereas the dataset collected by Li et al. [30] contains 235 images with various sizes of regions of interest. Moreover, a recent SALICON dataset (5000 images) [79], which contains a large number of non-iconic view objects, is also considered. From Fig. 7, some existing methods usually provide stronger responses to regions with higher local contrasts, such as edges or boundaries of objects (e.g., CA [2]), while ignoring the surfaces of salient structures. Others models can obtain a highly blurred saliency map, which cannot provide fine shapes or structures of objects. In contrast, our CGVS method is efficient for various situations. For simple scenes with predominant objects, CGVS can respond well to full objects (Fig. 7, the first to second rows). In addition, our method is also efficient when scenes contain multiple objects (two objects in Fig. 7, the third row) or widely spread interesting regions (Fig. 7, the fourth row). In short, our CGVS contributes to saliency computation in both simple and complex scenes. We further evaluated the performance of our CGVS for the task of fixation prediction. Fig. 8(top) shows the ROC curves of CGVS with various iterations on three datasets. In general, CGVS(t 0 ) achieves the best performance for fixation prediction because the iterative processing makes our system focus on the most salient objects in scenes, which decreases the precision of fixation prediction. Fig. 8 (bottom) shows that our method outperforms (or at least matches) all of the considered bottom-up (low-level) methods. Note that the method proposed by Judd et al. [31] achieves better performance mainly because several high-level feature related operations, such as face detection and person detection, are introduced into their model. Table I lists the comparison of AUC and NSS on the Judd and SALICON datasets. Note that the measure of ROC is somewhat biased when evaluating the performance of fixation prediction [81].


![[2], incorporating a center prior to the final saliency estimation can remarkably improve quantitative evaluation, but make the saliency map look less visually convincing. Fig.](/docs-images/96/128308915/images/8-2.jpg "9 shows examples indicating that CA with center prior obtains high performance in ROC (Fig. 9, the last column) but misses much object information when visualizing the saliency maps (Fig.")

 Some photographers are apt to locate the interesting contents at the center of view when taking pictures.")
![Actually, most of the existing methods promote higher saliency values in the center of the image plane, such as GBVS [20], Judd et al. [31], etc.](/docs-images/96/128308915/images/8-5.jpg "The proposed method also combines the center prior when computing CBSP. With similar observation with [2], CBSP achieves good performance on the ROC curve with the very blurred saliency region (Fig.")
 and achieving high performance on the ROC at the same time (Fig. 9, the last column).")

 are expected to tackle the influence of the center prior [81].")

![extract objects regional information. C. Salient Object Detection Salient object detection methods are commonly benchmarked by binary pixel-accurate object masks [16].](/docs-images/96/128308915/images/8-11.jpg "In this experiment, we first used the standard F-measure (P-R curve and F-score) for performance evaluation on two popular datasets with different peculiarities: ASD [6] includes simple scenes,")
![whereas ECSSD [8] includes more complex scenes. We also evaluated various methods on the PASCAL-S dataset [18], which was designed to be less biased.](/docs-images/96/128308915/images/8-12.jpg "In addition, considering the analysis of Margolin et al.")
8 3482 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 Fig. 9. Examples showing the gap between qualitative and quantitative evaluation. Quantitatively, CA provides clear improvement when introducing the center prior, but the visual assessment decreases substantially. Similarly, although quantitative evaluation of our method is a little worse than that of CA with the center prior, our CGVS obtains excellent assessment when visualizing the saliency map, which highlights almost all of the pixels of the dominant objects. TABLE I AUC AND NSS COMPARISONS ON TWO LARGER DATASET As indicated by Goferman et al. [2], incorporating a center prior to the final saliency estimation can remarkably improve quantitative evaluation, but make the saliency map look less visually convincing. Fig. 9 shows examples indicating that CA with center prior obtains high performance in ROC (Fig. 9, the last column) but misses much object information when visualizing the saliency maps (Fig. 9, the third column). Conversely, CA without center prior provides better results with qualitative evaluation (Fig. 9, the second column) but a lower score on the ROC curve. In general, two possible reasons may result in center bias. (1) In most eye-tracking experiments, image viewing is driven through a central fixation point before image presentation, and such center bias of human fixations can not be completely reduced by discarding several fixations at the beginning of the recording [31]. (2) Some photographers are apt to locate the interesting contents at the center of view when taking pictures. Actually, most of the existing methods promote higher saliency values in the center of the image plane, such as GBVS [20], Judd et al. [31], etc. The proposed method also combines the center prior when computing CBSP. With similar observation with [2], CBSP achieves good performance on the ROC curve with the very blurred saliency region (Fig. 9, the fourth column) regardless of the structure information of objects, which demonstrates the contribution of the nonselective pathway when turning down the selective pathway. However, our final CGVS is usually capable of detecting full objects and surfaces (Fig. 9, the fifth column) and achieving high performance on the ROC at the same time (Fig. 9, the last column). Compared to CA with or without a center prior, CGVS achieves qualitatively better results, although CA with a center prior achieves higher performance on the ROC curve, because CBSP is just a rough estimate of potential salient regions, and the saliency of each pixel is eventually identified with Bayesian Inference. Therefore, the center prior introduced in CBSP will not weaken greatly the salient structures close to the border of images. In addition, there are several other metrics for saliency evaluation, and some of them (e.g., shuffled AUC [44]) are expected to tackle the influence of the center prior [81]. However, all of these metrics for evaluating fixation prediction are computed against human fixations that are extremely sparse. Some salient structures such as large object surfaces extracted using our method may be incorrectly treated as false alarms by these metrics, which will unfairly evaluate the ability of our method to extract objects regional information. C. Salient Object Detection Salient object detection methods are commonly benchmarked by binary pixel-accurate object masks [16]. In this experiment, we first used the standard F-measure (P-R curve and F-score) for performance evaluation on two popular datasets with different peculiarities: ASD [6] includes simple scenes, whereas ECSSD [8] includes more complex scenes. We also evaluated various methods on the PASCAL-S dataset [18], which was designed to be less biased. In addition, considering the analysis of Margolin et al. [83] showing that the F-measure does not always provide a reliable evaluation for salient object detection, we also employed the amended F-measure (called Weighted F-score) proposed in [83] and the measure termed Mean Absolute Error (MAE) [51], [55], [84]. Fig. 10 lists the performance of our methods with both the standard P-R curves and the Weighted F-scores on the ASD and ECSSD datasets. In contrast to the fixation prediction in Section IV-B, the iterative process can further enhance the regions of objects and improve the performance because the benchmark used in this experiment has few salient objects. In general, our CGVS can obtain a stable performance with only two steps of iteration (i.e., CGVS(t 2 )). Fig. 11 shows the P-R Curve, F-score, Weighted F-score, and MAE for various state-of-the-art salient object methods on the three datasets. From the standard P-R curve and F-score, our CGVS(t 2 ) outperforms most of the considered algorithms except HS [8] and RF [18]. However, our method achieves high F-scores across a large range
9 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3483 Fig. 10. Quantitative evaluation on two salient object datasets (a) ASD [6] and (b) ECSSD [8]. Left: P-R curves for our method with various iteration steps. Right: Weighted F-score for our method with various iteration steps. CGVS(t 2 ) achieves stable performance with salient object detection. Fig. 11. Comparison of different saliency detection methods on three datasets with four metrics. (a) P-R Curve, (b) F-score, (c) Weighted F-score, and (d) Mean Absolute Error (MAE). The methods considered include LC [82], FT [6], HC [50], RC [50], SF [51], HS [8], Bayes [61]. CGVS denotes the version of our method without center bias. of thresholds (Fig. 11, the second column) on all of the considered datasets. This result indicates that the proposed model is capable of obtaining salient objects with high confidence. In addition, our method significantly outperforms all of the considered models on the measures of weighted F-score and MAE (except RF on PASCAL-S). Totally, our system achieves quite competitive performance compared to the state-of-theart methods in simple scenes. In addition, considering the fact that most of the methods compared here do not employ the center bias, we also show the performance of our CGVS without center bias (denoted by CGVS ) for fair comparison, as shown in Fig.11. It is clear that, although slightly worse than that of CGVS(t 2 ), CGVS obtains acceptable performance, especially in terms of the weighted F-score and MAE. Fig. 12 shows several example results of salient object detection. It should be noted that there are several recent methods that achieve better performance than the proposed system for the specific task of salient object detection [50], [55]. For example, the SaliencyCut method in [50] uses the detected saliency map (e.g., RC [50]) to initialize a novel iterative version of GrabCut for high quality salient object segmentation. We believe that by introducing specific post-processing similar to these methods, the performance of our model can also be improved on various metrics. D. Between Saliency Map and Salient Object In general, fixation prediction methods obtain poor performance when used for salient object detection. This is because almost all of the fixation prediction methods ignore the object surface and shape information and provide only a few fixation points. In this experiment, we demonstrated how to bridge the gap between the two tasks by simply transforming the saliency map to the salient object. In detail, when the saliency map is computed using certain fixation prediction methods,
 original images, (b) human-marked ground truth, results of salient object detection with various methods: (c) the proposed method with two steps of iteration, (d) Bayesian saliency (Bayes) [61],")
![(e) Boolean map (BMS) [62], (f) Hierarchical saliency (HS) [8], (g) Saliency filters (SF) [51], (h) region-based contrast (RC) [50], (i) histogram-based contrast (HC) [50], and (j) Frequency-tuned](/docs-images/96/128308915/images/10-1.jpg "(FT) [6]. Fig. 14(d) shows that the models for salient object detection perform poorly at fixation prediction on the Judd dataset [31].")
 Image. (b) IT. (c) Gaussian Fitted. (d) CGVS (t 0 ).")
) in the non-selective pathway.")
![Then, our system can transform the saliency map to salient objects with (5) (9). Fig. 13 shows two examples. We first computed the saliency map with a certain fixation prediction method (e.g., IT [5] with center prior, shown in Fig.](/docs-images/96/128308915/images/10-4.jpg "13(b)). The fitted Gaussian function is shown in Fig.")
-(b) show that the performances of several fixation prediction methods are significantly improved for salient object detection on both metrics of P-R Curve and weighted F-score on ASD dataset")
![when their fixation prediction maps are inputted as the initial CBSP of our model. Fig. 14(c) shows the comparison with RF [18], which conducted a similar task (i.e., detecting salient objects based on the GB fixation prediction method) on the PASCAL-S dataset [18].](/docs-images/96/128308915/images/10-6.jpg "Fig. 14(c) shows that our GB (one version of our method that is also based on GB) is slightly worse than RF in terms of the F-score and Weighted F-score but slightly better than RF on MAE. E.")
 with edge responses.")
10 3484 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 Fig. 12. Visual comparison of salient object detection. (a) original images, (b) human-marked ground truth, results of salient object detection with various methods: (c) the proposed method with two steps of iteration, (d) Bayesian saliency (Bayes) [61], (e) Boolean map (BMS) [62], (f) Hierarchical saliency (HS) [8], (g) Saliency filters (SF) [51], (h) region-based contrast (RC) [50], (i) histogram-based contrast (HC) [50], and (j) Frequency-tuned (FT) [6]. Fig. 14(d) shows that the models for salient object detection perform poorly at fixation prediction on the Judd dataset [31]. This is mainly because most pixels within objects detected by a salient object detection method are treated as false alarms when benchmarking on sparse human fixations. Fig. 13. The steps of transforming the saliency map to the salient object with the proposed system. (a) Image. (b) IT. (c) Gaussian Fitted. (d) CGVS (t 0 ). important information is usually distributed within or around the saliency regions. We employ the commonly used center prior to weaken the effect of saliency regions close to the image border. Then, we fit the global distribution of the saliency map with a 2-Dimension Gaussian function. The fitted result is used as the initial CBSP (Equivalent to S w in (1)) in the non-selective pathway. Then, our system can transform the saliency map to salient objects with (5) (9). Fig. 13 shows two examples. We first computed the saliency map with a certain fixation prediction method (e.g., IT [5] with center prior, shown in Fig. 13(b)). The fitted Gaussian function is shown in Fig. 13(c). Then the salient object (Fig. 13(d)) is obtained by the proposed system with the Gaussian-fitted saliency map as the initial CBSP. Fig. 14(a)-(b) show that the performances of several fixation prediction methods are significantly improved for salient object detection on both metrics of P-R Curve and weighted F-score on ASD dataset when their fixation prediction maps are inputted as the initial CBSP of our model. Fig. 14(c) shows the comparison with RF [18], which conducted a similar task (i.e., detecting salient objects based on the GB fixation prediction method) on the PASCAL-S dataset [18]. Fig. 14(c) shows that our GB (one version of our method that is also based on GB) is slightly worse than RF in terms of the F-score and Weighted F-score but slightly better than RF on MAE. E. Extended Saliency-Related Applications In this experiment, we extended our CGVS system to the task of salient edge detection. To implement this task, we compute the prior edges by multiplying the CBSP in (1) with edge responses. We also replace the four low-level features with three gradients in luminance and two color-opponent channels. Thus, the final output of our system is salient edges. Fig. 15 shows two examples of salient edge detection compared to the results of [7]. Fig. 16 shows that, with iterative processing, our CGVS system can search for some specific edges such as texts in natural scenes. This example reveals the potential application of our system in the task of text detection. F. Robustness to Parameters In the proposed system, the observed object mask and cue weights are important for the evaluation of likelihood functions in Section III-C. Fortunately, our system is capable of automatically predicting the sizes of potential structures and the relative weight of each feature according to CBSP. Therefore, we only tested the robustness of our method to the parameters of d r and σ c in the range of {1/2, 1/3, 1/4, 1/5, 1/6} min(w, H ) used in the computation of CBSP in Section III-A. Fig. 17(top) shows the F-scores and the weighted F-scores on the entire ASD dataset when varying these parameters. It can be seen that our system is very robust to these parameters. The same conclusion can be drawn from the fixation prediction experiment on Judd dataset with AUC and NSS measures (Fig. 17(bottom)). Taken together, Fig. 17 indicates that our method would not benefit much from learning an optimal parameter setting, and manual parameter selection is enough to robustly obtain quite acceptable performance. Fig. 18 shows that setting the threshold between 10% to 50% (Section III-C) may affect the final salient


 on the ASD dataset [6].")
![(c) The comparison with RF [18], on the new PASCAL-S dataset [18].](/docs-images/96/128308915/images/11-3.jpg "(d) The performance of some salient object detection methods used for fixation")
![prediction on the Judd dataset [31]. Fig. 15.](/docs-images/96/128308915/images/11-4.jpg "Two examples of salient edge detection compared to the results of salient edges by [7].")
 and fixation prediction")
 with σ c = min(w, H )/3 and various d r (left), and with d")
 on the Judd dataset. Fig. 16.")

).")
).")

 of the biological vision.")
![Different from the classical FIT theory [11] and the popular model proposed by Itti et](/docs-images/96/128308915/images/11-13.jpg "al. [5], our method searches for salient structures (SSs) with Bayesian inference")



![, [50], [55]), our model highlights the dominant objects with accurate shapes from](/docs-images/96/128308915/images/11-17.jpg "relatively simple scenes with as few as two or three steps Fig. 18.")

11 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3485 Fig. 14. Between fixation prediction and salient object detection. Evaluating the performances of several fixation prediction methods and their modified versions ( ) for salient structure detection with the metrics of P-R Curve (a) and weighted F-score (b) on the ASD dataset [6]. (c) The comparison with RF [18], on the new PASCAL-S dataset [18]. (d) The performance of some salient object detection methods used for fixation prediction on the Judd dataset [31]. Fig. 15. Two examples of salient edge detection compared to the results of salient edges by [7]. Fig. 17. Robustness to parameters on salient object dataset (ASD) and fixation prediction dataset (Judd). Top: Testing our CGVS(t 2 ) with σ c = min(w, H )/3 and various d r (left), and with d r = min(w, H )/3 and various σ c (right). Bottom: similar testing of CGVS(t 0 ) on the Judd dataset. Fig. 16. The CGVS system can search for some specific edges such as texts in natural scenes with iterative processing. structure detection. For example, for smaller objects (<10%), high thresholds (>10%) lead to many background pixels being incorrectly divided into object sets (Fig. 18(top)). In contrast, for larger objects, a low threshold may cause the algorithm to respond only to a partial region of the object (Fig. 18(bottom)). Therefore, a more robust strategy for object size selection is expected in the future to adapt to various complex scenes. V. DISCUSSION In this paper, we proposed a contour-guided visual search (CGVS) system inspired by the guided search theory (GST) of the biological vision. Different from the classical FIT theory [11] and the popular model proposed by Itti et al. [5], our method searches for salient structures (SSs) with Bayesian inference guided by contour information, such as the location and size of SS, importance of features, etc. Although many recent models attempt to employ various image segmentation algorithms as a pre-processing step to divide the images into superpixels and obtain high quality salient object segmentation (e.g., [50], [55]), our model highlights the dominant objects with accurate shapes from relatively simple scenes with as few as two or three steps Fig. 18. Examples of detecting quite small or large objects. Top: incorrect estimation for a small object. Bottom: response to part of a larger object. of iteration, without the requirement of segmenting input image into superpixels. The flexibility and robustness of the proposed system come from the following novel strategies, in comparison to other Bayesian inference based saliency detection models: (1) A simple yet efficient edge-based filling-in operation is implemented to create the robust global gist used for topdown control. This edge-based filling-in can always capture the interesting regions where an unambiguous object of interest is contained. (2) Simple yet robust methods are designed to automatically and robustly define the sizes of potential salient structures and estimate the weight of each bottom-up feature, which enables the salient objects to have clear shapes and filled surfaces or highlights the interesting regions (without clear object) within a filled but limited area.
12 3486 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 Extracting contextual (or coarse) information from scenes rapidly and then guiding the processing of fine information is an efficient strategy (i.e., coarse-to-fine) for visual perception and scene analysis without involving specific tasks. From this standpoint, the proposed model can be regarded as a general framework for guided search, and this system can be easily extended, e.g., by introducing high-level object-related global features in the non-selective pathway for a specific object search task. Meanwhile, adding more local features (e.g., depth, motion, etc.) in the selective pathway may also extend our system to more applications such as video processing. In addition, some unsupervised learning methods [85] can be employed for rapid scene analysis and finding the structured context in the non-selective pathway. It is clear that the proposed approach is purely image signal driven. In particular, the dominant edges in the nonselective pathway of this model act as a type of non-selective structural information to provide the where prior of potential objects, whereas the detailed object features (i.e., the what information) are extracted in the selective pathway. However, it seems difficult to closely relate our two-pathway based approach to the widely recognised work by Ungerleider on ventral and dorsal pathways [86]. As indicated by Wolfe et al. [1], more studies are still required before the selective and non-selective pathways can be properly related to the what and where pathways in terms of neurophysiology, though the corresponding pathways in these two theories seem to be similar in terms of specific functional roles. To conclude, the result of this work is a single computationally efficient system that provides dual use. When given a cluttered scene without any dominant object, the proposed system will work as a fixation prediction model. Alternatively, when given a simple scene, the proposed system will determine the dominant objects contained in the scene. REFERENCES [1] J.M.Wolfe,M.L.-H.Võ,K.K.Evans,andM.R.Greene, Visual search in scenes involves selective and non-selective pathways, Trends Cognit. Sci., vol. 15, no. 2, pp , [2] S. Goferman, L. Zelnik-Manor, and A. Tal, Context-aware saliency detection, IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 10, pp , Oct [3] C. Christopoulos, A. Skodras, and T. Ebrahimi, The JPEG2000 still image coding system: An overview, IEEE Trans. Consum. Electron., vol. 46, no. 4, pp , Nov [4] U. Rutishauser, D. Walther, C. Koch, and P. Perona, Is bottom-up attention useful for object recognition? in Proc. IEEE CVPR, vol. 2. Jun./Jul. 2004, pp. II-37 II-44. [5] L. Itti, C. Koch, and E. Niebur, A model of saliency-based visual attention for rapid scene analysis, IEEE Trans. Pattern Anal. Mach. Intell., vol. 20, no. 11, pp , Nov [6] R. Achanta, S. Hemami, F. Estrada, and S. Susstrunk, Frequencytuned salient region detection, in Proc. IEEE CVPR, Jun. 2009, pp [7] M. Holtzman-Gazit, L. Zelnik-Manor, and I. Yavneh, Salient edges: A multi scale approach, in Proc. ECCV Workshop, 2010, p [8] Q. Yan, L. Xu, J. Shi, and J. Jia, Hierarchical saliency detection, in Proc. IEEE CVPR, Jun. 2013, pp [9] M. V. Peelen and S. Kastner, Attention in the real world: Toward understanding its neural basis, Trends Cognit. Sci., vol. 18, no. 5, pp , [10] L. Elazary and L. Itti, A Bayesian model for efficient visual search and recognition, Vis. Res., vol. 50, no. 14, pp , [11] A. M. Treisman and G. Gelade, A feature-integration theory of attention, Cognit. Psychol., vol. 12, no. 1, pp , Jan [12] C. Koch and S. Ullman, Shifts in selective visual attention: Towards the underlying neural circuitry, in Proc. Matters Intell., 1987, pp [13] J. M. Wolfe, Guided search 2.0 a revised model of visual search, Psychonomic Bull. Rev., vol. 1, no. 2, pp , [14] R. Desimone and J. Duncan, Neural mechanisms of selective visual attention, Ann. Rev. Neurosci., vol. 18, no. 1, pp , [15] A. Borji and L. Itti, State-of-the-art in visual attention modeling, IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 1, pp , Jan [16] A. Borji, M.-M. Cheng, H. Jiang, and J. Li. (Nov. 2014). Salient object detection: A survey. [Online]. Available: [17] L. Itti and C. Koch, Computational modelling of visual attention, Nature Rev. Neurosci., vol. 2, no. 3, pp , [18] Y. Li, X. Hou, C. Koch, J. M. Rehg, and A. L. Yuille, The secrets of salient object segmentation, in Proc. IEEE CVPR, Jun. 2014, pp [19] O. Le Meur, P. Le Callet, D. Barba, and D. Thoreau, A coherent computational approach to model bottom-up visual attention, IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 5, pp , May [20] J. Harel, C. Koch, and P. Perona, Graph-based visual saliency, in Proc. NIPS, 2006, pp [21] N. Bruce and J. Tsotsos, Saliency based on information maximization, in Proc. NIPS, 2005, pp [22] X. Hou, J. Harel, and C. Koch, Image signature: Highlighting sparse salient regions, IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 1, pp , Jan [23] A. Garcia-Diaz, X. R. Fdez-Vidal, X. M. Pardo, and R. Dosil, Decorrelation and distinctiveness provide with human-like saliency, in Proc. Adv. Concepts Intell. Vis. Syst., 2009, pp [24] A. Borji and L. Itti, Exploiting local and global patch rarities for saliency detection, in Proc. IEEE CVPR, Jun. 2012, pp [25] Y. Lin, B. Fang, and Y. Tang, A computational model for saliency maps by using local entropy, in Proc. 24th AAAI, 2010, pp [26] Y. Lin, Y. Y. Tang, B. Fang, Z. Shang, Y. Huang, and S. Wang, A visual-attention model using earth mover s distance-based saliency measurement and nonlinear feature combination, IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 2, pp , Feb [27] X. Hou and L. Zhang, Saliency detection: A spectral residual approach, in Proc. IEEE CVPR, Jun. 2007, pp [28] C. Guo, Q. Ma, and L. Zhang, Spatio-temporal saliency detection using phase spectrum of quaternion Fourier transform, in Proc. IEEE CVPR, Jun. 2008, pp [29] C. Guo and L. Zhang, A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression, IEEE Trans. Image Process., vol. 19, no. 1, pp , Jan [30] J. Li, M. D. Levine, X. An, X. Xu, and H. He, Visual saliency based on scale-space analysis in the frequency domain, IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 4, pp , Apr [31] T. Judd, K. Ehinger, F. Durand, and A. Torralba, Learning to predict where humans look, in Proc. IEEE 12th ICCV, Sep./Oct. 2009, pp [32] A. Borji, Boosting bottom-up and top-down visual features for saliency estimation, in Proc. IEEE CVPR, Jun. 2012, pp [33] W. Einhäuser, M. Spain, and P. Perona, Objects predict fixations better than early saliency, J. Vis., vol. 8, no. 14, pp. 1 26, [34] L. Elazary and L. Itti, Interesting objects are visually salient, J. Vis., vol. 8, no. 3, pp. 1 15, [35] M. Cerf, J. Harel, W. Einhäuser, and C. Koch, Predicting human gaze using low-level saliency combined with face detection, in Proc. NIPS, 2008, pp [36] S. Ramanathan, H. Katti, N. Sebe, M. Kankanhalli, and T.-S. Chua, An eye fixation database for saliency detection in images, in Proc. 11th ECCV, 2010, pp [37] A. Oliva, A. Torralba, M. S. Castelhano, and J. M. Henderson, Topdown control of visual attention in object detection, in Proc. ICIP, vol. 1. Sep. 2003, pp [38] V. Navalpakkam and L. Itti, Modeling the influence of task on attention, Vis. Res., vol. 45, no. 2, pp , [39] V. Navalpakkam and L. Itti, An integrated model of top-down and bottom-up attention for optimizing detection speed, in Proc. IEEE CVPR, vol. 2. Jun. 2006, pp [40] R. J. Peters and L. Itti, Beyond bottom-up: Incorporating taskdependent influences into a computational model of spatial attention, in Proc. IEEE CVPR, Jun. 2007, pp. 1 8.
![YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3487 [41] Q. Zhao and C. Koch, Learning a saliency map using fixated locations in natural scenes, J. Vis., vol. 11, no.](/docs-images/96/128308915/images/13-0.jpg "3, pp. 1 15, 2011. [42] W. Kienzle, F. A. Wichmann, M. O. Franz, and B. Schölkopf, A nonparametric approach to bottom-up visual saliency, in Proc. NIPS, 2006, pp. 689 696. [43] C.-C. Wu, F. A. Wick, and M.")
![Pomplun, Guidance of visual attention by semantic information in real-world scenes, Frontiers Psychol., vol.5, no. 54, pp. 1 13, 2014. [44] L. Zhang, M. H. Tong, T. K. Marks, H. Shan, and G. W.](/docs-images/96/128308915/images/13-1.jpg "Cottrell, SUN: A Bayesian framework for saliency using natural statistics, J. Vis., vol. 8, no. 7, pp. 1 20, 2008. [45] A. Torralba, Modeling global scene factors in attention, J. Opt. Soc. Amer.")
13 YANG et al.: UNIFIED FRAMEWORK FOR SS DETECTION BY CONTOUR-GUIDED VISUAL SEARCH 3487 [41] Q. Zhao and C. Koch, Learning a saliency map using fixated locations in natural scenes, J. Vis., vol. 11, no. 3, pp. 1 15, [42] W. Kienzle, F. A. Wichmann, M. O. Franz, and B. Schölkopf, A nonparametric approach to bottom-up visual saliency, in Proc. NIPS, 2006, pp [43] C.-C. Wu, F. A. Wick, and M. Pomplun, Guidance of visual attention by semantic information in real-world scenes, Frontiers Psychol., vol.5, no. 54, pp. 1 13, [44] L. Zhang, M. H. Tong, T. K. Marks, H. Shan, and G. W. Cottrell, SUN: A Bayesian framework for saliency using natural statistics, J. Vis., vol. 8, no. 7, pp. 1 20, [45] A. Torralba, Modeling global scene factors in attention, J. Opt. Soc. Amer. A, vol. 20, no. 7, pp , [46] A. Torralba, A. Oliva, M. S. Castelhano, and J. M. Henderson, Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search, Psychol. Rev., vol. 113, no. 4, pp , Oct [47] L. Itti and P. F. Baldi, Bayesian surprise attracts human attention, in Proc. NIPS, 2005, pp [48] S. Lu, C. Tan, and J.-H. Lim, Robust and efficient saliency modeling from image co-occurrence histograms, IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 1, pp , Jan [49] T. Liu et al., Learning to detect a salient object, IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 2, pp , Feb [50] M.-M. Cheng, N. J. Mitra, X. Huang, P. H. S. Torr, and S.-M. Hu, Global contrast based salient region detection, IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp , Mar [51] F. Perazzi, P. Krähenbühl, Y. Pritch, and A. Hornung, Saliency filters: Contrast based filtering for salient region detection, in Proc. IEEE CVPR, Jun. 2012, pp [52] R. Margolin, A. Tal, and L. Zelnik-Manor, What makes a patch distinct? in Proc. IEEE CVPR, Jun. 2013, pp [53] D. A. Klein et al., Center-surround divergence of feature statistics for salient object detection, in Proc. IEEE ICCV, Nov. 2011, pp [54] Y. Wei, F. Wen, W. Zhu, and J. Sun, Geodesic saliency using background priors, in Proc. ECCV, 2012, pp [55] W. Zhu, S. Liang, Y. Wei, and J. Sun, Saliency optimization from robust background detection, in Proc. IEEE CVPR, Jun. 2014, pp [56] B. Alexe, T. Deselaers, and V. Ferrari, Measuring the objectness of image windows, IEEE Trans. Pattern Anal. Mach. Intell., vol. 34, no. 11, pp , Nov [57] I. Endres and D. Hoiem, Category-independent object proposals with diverse ranking, IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 2, pp , Feb [58] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. Torr, Bing: Binarized normed gradients for objectness estimation at 300 fps, in Proc. IEEE CVPR, Jun. 2014, pp [59] R. P. Rao, Bayesian inference and attentional modulation in the visual cortex, Neuroreport, vol. 16, no. 16, pp , [60] S. Chikkerur, T. Serre, C. Tan, and T. Poggio, What and where: A Bayesian inference theory of attention, Vis. Res., vol. 50, no. 22, pp , [61] Y. Xie, H. Lu, and M.-H. Yang, Bayesian saliency via low and mid level cues, IEEE Trans. Image Process., vol. 22, no. 5, pp , May [62] J. Zhang and S. Sclaroff, Saliency detection: A Boolean map approach, in Proc. IEEE ICCV, Dec. 2013, pp [63] A. Oliva and A. Torralba, Building the gist of a scene: The role of global image features in recognition, Prog. Brain Res., vol. 155, pp , Oct [64] L. Chen, The topological approach to perceptual organization, Vis. Cognit., vol. 12, no. 4, pp , [65] M. Chen, Y. Yan, X. Gong, C. D. Gilbert, H. Liang, and W. Li, Incremental integration of global contours through interplay between visual cortical areas, Neuron, vol. 82, no. 3, pp , [66] P. L. Rosin, A simple method for detecting salient regions, Pattern Recognit., vol. 42, no. 11, pp , Nov [67] S. Anstis, Visual filling-in, Current Biol., vol. 20, no. 16, pp. R664 R666, [68] H. Neumann, L. Pessoa, and T. Hansen, Visual filling-in for computing perceptual surface properties, Biol. Cybern., vol. 85, no. 5, pp , [69] S. Grossberg, E. Mingolla, and J. Williamson, Synthetic aperture radar processing by a multiple scale neural system for boundary and surface representation, Neural Netw., vol. 8, nos. 7 8, pp , [70] K. Yang, S. Gao, C. Li, and Y. Li, Efficient color boundary detection with color-opponent mechanisms, in Proc. IEEE CVPR, Jun. 2013, pp [71] B. W. Tatler, The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions, J. Vis., vol. 7, no. 14, pp. 1 17, [72] V. Mante, R. A. Frazor, V. Bonin, W. S. Geisler, and M. Carandini, Independence of luminance and contrast in natural scenes and in the early visual system, Nature Neurosci., vol. 8, no. 12, pp , [73] R. A. Frazor and W. S. Geisler, Local luminance and contrast in natural images, Vis. Res., vol. 46, no. 10, pp , [74] J. T. Lindgren, J. Hurri, and A. Hyvärinen, Spatial dependencies between local luminance and contrast in natural images, J. Vis., vol. 8, no. 12, p. 6, [75] E. Switkes and M. A. Crognale, Comparison of color and luminance contrast: Apples versus oranges? Vis. Res., vol. 39, no. 10, pp , [76] S. Clery, M. Bloj, and J. M. Harris, Interactions between luminance and color signals: Effects on shape, J. Vis., vol. 13, no. 5, p. 16, [77] P. Domingos and M. Pazzani, On the optimality of the simple Bayesian classifier under zero-one loss, Mach. Learn., vol. 29, nos. 2 3, pp , [78] E. Rahtu, J. Kannala, M. Salo, and J. Heikkilä, Segmenting salient objects from images and videos, in Proc. 11th ECCV, 2010, pp [79] M. Jiang, S. Huang, J. Duan, and Q. Zhao, Salicon: Saliency in context, in Proc. CVPR, Jun. 2015, pp [80] R. J. Peters, A. Iyer, L. Itti, and C. Koch, Components of bottom-up gaze allocation in natural images, Vis. Res., vol. 45, no. 8, pp , [81] A. Borji, H. R. Tavakoli, D. N. Sihite, and L. Itti, Analysis of scores, datasets, and models in visual saliency prediction, in Proc. IEEE ICCV, Dec. 2013, pp [82] Y. Zhai and M. Shah, Visual attention detection in video sequences using spatiotemporal cues, in Proc. 14th ACM MM, 2006, pp [83] R. Margolin, L. Zelnik-Manor, and A. Tal, How to evaluate foreground maps, in Proc. IEEE CVPR, Jun. 2014, pp [84] M.-M. Cheng, J. Warrell, W.-Y. Lin, S. Zheng, V. Vineet, and N. Crook, Efficient salient region detection with soft image abstraction, in Proc. IEEE ICCV, Dec. 2013, pp [85] X. Peng, L. Zhang, and Z. Yi, Scalable sparse subspace clustering, in Proc. CVPR, Jun. 2013, pp [86] L. G. Ungerleider and J. V. Haxby, What and where in the human brain, Current Opinion Neurobiol., vol. 4, no. 2, pp , Kai-Fu Yang received the B.Sc. and M.Sc. degrees in biomedical engineering from the University of Electronic Science and Technology of China, Chengdu, China, in 2009 and 2012, respectively, where he is currently pursuing the Ph.D. degree. His research interests include visual mechanism modeling and image processing. Hui Li received the B.Sc. degree in biomedical engineering from the University of Electronic Science and Technology of China, Chengdu, China, in 2013, where she is currently pursuing the M.Sc. degree. Her research interests include visual mechanism modeling and image processing.

 received the Ph.D.")
14 3488 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 Chao-Yi Li received the degree from Chinese Medical University, Shenyang, China, in 1956, and the degree from Fudan University, Shanghai, China, in He is currently a Professor with the University of Electronic Science and Technology of China, Chengdu, China, and the Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences. His research interest is mainly in visual neurophysiology. Yong-Jie Li (M 14) received the Ph.D. degree in biomedical engineering from the University of Electronic Science and Technology of China (UESTC), Chengdu, China, in He is currently a Professor with the Key Laboratory for Neuroinformation of Ministry of Education, School of Life Science and Technology, UESTC. His research interests include visual mechanism modeling, image processing, and intelligent computation.
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING
 VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
Computational Cognitive Science
 Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Validating the Visual Saliency Model
 Validating the Visual Saliency Model Ali Alsam and Puneet Sharma Department of Informatics & e-learning (AITeL), Sør-Trøndelag University College (HiST), Trondheim, Norway er.puneetsharma@gmail.com Abstract.
Validating the Visual Saliency Model Ali Alsam and Puneet Sharma Department of Informatics & e-learning (AITeL), Sør-Trøndelag University College (HiST), Trondheim, Norway er.puneetsharma@gmail.com Abstract.
Computational Cognitive Science. The Visual Processing Pipeline. The Visual Processing Pipeline. Lecture 15: Visual Attention.
 Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Finding Saliency in Noisy Images
 Finding Saliency in Noisy Images Chelhwon Kim and Peyman Milanfar Electrical Engineering Department, University of California, Santa Cruz, CA, USA ABSTRACT Recently, many computational saliency models
Finding Saliency in Noisy Images Chelhwon Kim and Peyman Milanfar Electrical Engineering Department, University of California, Santa Cruz, CA, USA ABSTRACT Recently, many computational saliency models
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis
 Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
Computational Cognitive Science
 Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
The 29th Fuzzy System Symposium (Osaka, September 9-, 3) Color Feature Maps (BY, RG) Color Saliency Map Input Image (I) Linear Filtering and Gaussian
 Color Feature Maps (BY, RG) Color Saliency Map Input Image (I) Linear Filtering and Gaussian") The 29th Fuzzy System Symposium (Osaka, September 9-, 3) A Fuzzy Inference Method Based on Saliency Map for Prediction Mao Wang, Yoichiro Maeda 2, Yasutake Takahashi Graduate School of Engineering, University
The 29th Fuzzy System Symposium (Osaka, September 9-, 3) A Fuzzy Inference Method Based on Saliency Map for Prediction Mao Wang, Yoichiro Maeda 2, Yasutake Takahashi Graduate School of Engineering, University
A Visual Saliency Map Based on Random Sub-Window Means
 A Visual Saliency Map Based on Random Sub-Window Means Tadmeri Narayan Vikram 1,2, Marko Tscherepanow 1 and Britta Wrede 1,2 1 Applied Informatics Group 2 Research Institute for Cognition and Robotics
A Visual Saliency Map Based on Random Sub-Window Means Tadmeri Narayan Vikram 1,2, Marko Tscherepanow 1 and Britta Wrede 1,2 1 Applied Informatics Group 2 Research Institute for Cognition and Robotics
Natural Scene Statistics and Perception. W.S. Geisler
 Natural Scene Statistics and Perception W.S. Geisler Some Important Visual Tasks Identification of objects and materials Navigation through the environment Estimation of motion trajectories and speeds
Natural Scene Statistics and Perception W.S. Geisler Some Important Visual Tasks Identification of objects and materials Navigation through the environment Estimation of motion trajectories and speeds
Models of Attention. Models of Attention
 Models of Models of predictive: can we predict eye movements (bottom up attention)? [L. Itti and coll] pop out and saliency? [Z. Li] Readings: Maunsell & Cook, the role of attention in visual processing,
Models of Models of predictive: can we predict eye movements (bottom up attention)? [L. Itti and coll] pop out and saliency? [Z. Li] Readings: Maunsell & Cook, the role of attention in visual processing,
I. INTRODUCTION VISUAL saliency, which is a term for the pop-out
 IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 27, NO. 6, JUNE 2016 1177 Spatiochromatic Context Modeling for Color Saliency Analysis Jun Zhang, Meng Wang, Member, IEEE, Shengping Zhang,
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 27, NO. 6, JUNE 2016 1177 Spatiochromatic Context Modeling for Color Saliency Analysis Jun Zhang, Meng Wang, Member, IEEE, Shengping Zhang,
EARLY STAGE DIAGNOSIS OF LUNG CANCER USING CT-SCAN IMAGES BASED ON CELLULAR LEARNING AUTOMATE
 EARLY STAGE DIAGNOSIS OF LUNG CANCER USING CT-SCAN IMAGES BASED ON CELLULAR LEARNING AUTOMATE SAKTHI NEELA.P.K Department of M.E (Medical electronics) Sengunthar College of engineering Namakkal, Tamilnadu,
EARLY STAGE DIAGNOSIS OF LUNG CANCER USING CT-SCAN IMAGES BASED ON CELLULAR LEARNING AUTOMATE SAKTHI NEELA.P.K Department of M.E (Medical electronics) Sengunthar College of engineering Namakkal, Tamilnadu,
GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES
 GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES Jie Wu and Liqing Zhang MOE-Microsoft Laboratory for Intelligent Computing and Intelligent Systems Dept. of CSE, Shanghai Jiao Tong
GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES Jie Wu and Liqing Zhang MOE-Microsoft Laboratory for Intelligent Computing and Intelligent Systems Dept. of CSE, Shanghai Jiao Tong
Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling
 AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
Visual Saliency with Statistical Priors
 Int J Comput Vis (2014) 107:239 253 DOI 10.1007/s11263-013-0678-0 Visual Saliency with Statistical Priors Jia Li Yonghong Tian Tiejun Huang Received: 21 December 2012 / Accepted: 21 November 2013 / Published
Int J Comput Vis (2014) 107:239 253 DOI 10.1007/s11263-013-0678-0 Visual Saliency with Statistical Priors Jia Li Yonghong Tian Tiejun Huang Received: 21 December 2012 / Accepted: 21 November 2013 / Published
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION
 MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
Local Image Structures and Optic Flow Estimation
 Local Image Structures and Optic Flow Estimation Sinan KALKAN 1, Dirk Calow 2, Florentin Wörgötter 1, Markus Lappe 2 and Norbert Krüger 3 1 Computational Neuroscience, Uni. of Stirling, Scotland; {sinan,worgott}@cn.stir.ac.uk
Local Image Structures and Optic Flow Estimation Sinan KALKAN 1, Dirk Calow 2, Florentin Wörgötter 1, Markus Lappe 2 and Norbert Krüger 3 1 Computational Neuroscience, Uni. of Stirling, Scotland; {sinan,worgott}@cn.stir.ac.uk
Fusing Generic Objectness and Visual Saliency for Salient Object Detection
 Fusing Generic Objectness and Visual Saliency for Salient Object Detection Yasin KAVAK 06/12/2012 Citation 1: Salient Object Detection: A Benchmark Fusing for Salient Object Detection INDEX (Related Work)
Fusing Generic Objectness and Visual Saliency for Salient Object Detection Yasin KAVAK 06/12/2012 Citation 1: Salient Object Detection: A Benchmark Fusing for Salient Object Detection INDEX (Related Work)
Computational modeling of visual attention and saliency in the Smart Playroom
 Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Methods for comparing scanpaths and saliency maps: strengths and weaknesses
 Methods for comparing scanpaths and saliency maps: strengths and weaknesses O. Le Meur olemeur@irisa.fr T. Baccino thierry.baccino@univ-paris8.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/
Methods for comparing scanpaths and saliency maps: strengths and weaknesses O. Le Meur olemeur@irisa.fr T. Baccino thierry.baccino@univ-paris8.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/
AUTOMATIC MEASUREMENT ON CT IMAGES FOR PATELLA DISLOCATION DIAGNOSIS
 AUTOMATIC MEASUREMENT ON CT IMAGES FOR PATELLA DISLOCATION DIAGNOSIS Qi Kong 1, Shaoshan Wang 2, Jiushan Yang 2,Ruiqi Zou 3, Yan Huang 1, Yilong Yin 1, Jingliang Peng 1 1 School of Computer Science and
AUTOMATIC MEASUREMENT ON CT IMAGES FOR PATELLA DISLOCATION DIAGNOSIS Qi Kong 1, Shaoshan Wang 2, Jiushan Yang 2,Ruiqi Zou 3, Yan Huang 1, Yilong Yin 1, Jingliang Peng 1 1 School of Computer Science and
On the implementation of Visual Attention Architectures
 On the implementation of Visual Attention Architectures KONSTANTINOS RAPANTZIKOS AND NICOLAS TSAPATSOULIS DEPARTMENT OF ELECTRICAL AND COMPUTER ENGINEERING NATIONAL TECHNICAL UNIVERSITY OF ATHENS 9, IROON
On the implementation of Visual Attention Architectures KONSTANTINOS RAPANTZIKOS AND NICOLAS TSAPATSOULIS DEPARTMENT OF ELECTRICAL AND COMPUTER ENGINEERING NATIONAL TECHNICAL UNIVERSITY OF ATHENS 9, IROON
Keywords Fuzzy Logic, Fuzzy Rule, Fuzzy Membership Function, Fuzzy Inference System, Edge Detection, Regression Analysis.
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Modified Fuzzy
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Modified Fuzzy
An Attentional Framework for 3D Object Discovery
 An Attentional Framework for 3D Object Discovery Germán Martín García and Simone Frintrop Cognitive Vision Group Institute of Computer Science III University of Bonn, Germany Saliency Computation Saliency
An Attentional Framework for 3D Object Discovery Germán Martín García and Simone Frintrop Cognitive Vision Group Institute of Computer Science III University of Bonn, Germany Saliency Computation Saliency
Classification of Synapses Using Spatial Protein Data
 Classification of Synapses Using Spatial Protein Data Jenny Chen and Micol Marchetti-Bowick CS229 Final Project December 11, 2009 1 MOTIVATION Many human neurological and cognitive disorders are caused
Classification of Synapses Using Spatial Protein Data Jenny Chen and Micol Marchetti-Bowick CS229 Final Project December 11, 2009 1 MOTIVATION Many human neurological and cognitive disorders are caused
A Model for Automatic Diagnostic of Road Signs Saliency
 A Model for Automatic Diagnostic of Road Signs Saliency Ludovic Simon (1), Jean-Philippe Tarel (2), Roland Brémond (2) (1) Researcher-Engineer DREIF-CETE Ile-de-France, Dept. Mobility 12 rue Teisserenc
A Model for Automatic Diagnostic of Road Signs Saliency Ludovic Simon (1), Jean-Philippe Tarel (2), Roland Brémond (2) (1) Researcher-Engineer DREIF-CETE Ile-de-France, Dept. Mobility 12 rue Teisserenc
Implementation of Automatic Retina Exudates Segmentation Algorithm for Early Detection with Low Computational Time
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 5 Issue 10 Oct. 2016, Page No. 18584-18588 Implementation of Automatic Retina Exudates Segmentation Algorithm
www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 5 Issue 10 Oct. 2016, Page No. 18584-18588 Implementation of Automatic Retina Exudates Segmentation Algorithm
Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination
 Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination Timothy N. Rubin (trubin@uci.edu) Michael D. Lee (mdlee@uci.edu) Charles F. Chubb (cchubb@uci.edu) Department of Cognitive
Hierarchical Bayesian Modeling of Individual Differences in Texture Discrimination Timothy N. Rubin (trubin@uci.edu) Michael D. Lee (mdlee@uci.edu) Charles F. Chubb (cchubb@uci.edu) Department of Cognitive
ANALYSIS AND DETECTION OF BRAIN TUMOUR USING IMAGE PROCESSING TECHNIQUES
 ANALYSIS AND DETECTION OF BRAIN TUMOUR USING IMAGE PROCESSING TECHNIQUES P.V.Rohini 1, Dr.M.Pushparani 2 1 M.Phil Scholar, Department of Computer Science, Mother Teresa women s university, (India) 2 Professor
ANALYSIS AND DETECTION OF BRAIN TUMOUR USING IMAGE PROCESSING TECHNIQUES P.V.Rohini 1, Dr.M.Pushparani 2 1 M.Phil Scholar, Department of Computer Science, Mother Teresa women s university, (India) 2 Professor
Visual Saliency Based on Multiscale Deep Features Supplementary Material
 Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features
 Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features U.Swamy Kumar PG Scholar Department of ECE, K.S.R.M College of Engineering (Autonomous), Kadapa. ABSTRACT Salient
Salient Object Detection in Videos Based on SPATIO-Temporal Saliency Maps and Colour Features U.Swamy Kumar PG Scholar Department of ECE, K.S.R.M College of Engineering (Autonomous), Kadapa. ABSTRACT Salient
Advertisement Evaluation Based On Visual Attention Mechanism
 2nd International Conference on Economics, Management Engineering and Education Technology (ICEMEET 2016) Advertisement Evaluation Based On Visual Attention Mechanism Yu Xiao1, 2, Peng Gan1, 2, Yuling
2nd International Conference on Economics, Management Engineering and Education Technology (ICEMEET 2016) Advertisement Evaluation Based On Visual Attention Mechanism Yu Xiao1, 2, Peng Gan1, 2, Yuling
Computational Models of Visual Attention: Bottom-Up and Top-Down. By: Soheil Borhani
 Computational Models of Visual Attention: Bottom-Up and Top-Down By: Soheil Borhani Neural Mechanisms for Visual Attention 1. Visual information enter the primary visual cortex via lateral geniculate nucleus
Computational Models of Visual Attention: Bottom-Up and Top-Down By: Soheil Borhani Neural Mechanisms for Visual Attention 1. Visual information enter the primary visual cortex via lateral geniculate nucleus
Automated Assessment of Diabetic Retinal Image Quality Based on Blood Vessel Detection
 Y.-H. Wen, A. Bainbridge-Smith, A. B. Morris, Automated Assessment of Diabetic Retinal Image Quality Based on Blood Vessel Detection, Proceedings of Image and Vision Computing New Zealand 2007, pp. 132
Y.-H. Wen, A. Bainbridge-Smith, A. B. Morris, Automated Assessment of Diabetic Retinal Image Quality Based on Blood Vessel Detection, Proceedings of Image and Vision Computing New Zealand 2007, pp. 132
Neurally Inspired Mechanisms for the Dynamic Visual Attention Map Generation Task
 Neurally Inspired Mechanisms for the Dynamic Visual Attention Map Generation Task Maria T. Lopez 1, Miguel A. Fernandez 1, Antonio Fernandez-Caballero 1, and Ana E. Delgado 2 Departamento de Informatica
Neurally Inspired Mechanisms for the Dynamic Visual Attention Map Generation Task Maria T. Lopez 1, Miguel A. Fernandez 1, Antonio Fernandez-Caballero 1, and Ana E. Delgado 2 Departamento de Informatica
196 IEEE TRANSACTIONS ON AUTONOMOUS MENTAL DEVELOPMENT, VOL. 2, NO. 3, SEPTEMBER 2010
 196 IEEE TRANSACTIONS ON AUTONOMOUS MENTAL DEVELOPMENT, VOL. 2, NO. 3, SEPTEMBER 2010 Top Down Gaze Movement Control in Target Search Using Population Cell Coding of Visual Context Jun Miao, Member, IEEE,
196 IEEE TRANSACTIONS ON AUTONOMOUS MENTAL DEVELOPMENT, VOL. 2, NO. 3, SEPTEMBER 2010 Top Down Gaze Movement Control in Target Search Using Population Cell Coding of Visual Context Jun Miao, Member, IEEE,
Webpage Saliency. National University of Singapore
 Webpage Saliency Chengyao Shen 1,2 and Qi Zhao 2 1 Graduate School for Integrated Science and Engineering, 2 Department of Electrical and Computer Engineering, National University of Singapore Abstract.
Webpage Saliency Chengyao Shen 1,2 and Qi Zhao 2 1 Graduate School for Integrated Science and Engineering, 2 Department of Electrical and Computer Engineering, National University of Singapore Abstract.
Study on perceptually-based fitting line-segments
 Regeo. Geometric Reconstruction Group www.regeo.uji.es Technical Reports. Ref. 08/2014 Study on perceptually-based fitting line-segments Raquel Plumed, Pedro Company, Peter A.C. Varley Department of Mechanical
Regeo. Geometric Reconstruction Group www.regeo.uji.es Technical Reports. Ref. 08/2014 Study on perceptually-based fitting line-segments Raquel Plumed, Pedro Company, Peter A.C. Varley Department of Mechanical
A Hierarchical Visual Saliency Model for Character Detection in Natural Scenes
 A Hierarchical Visual Saliency Model for Character Detection in Natural Scenes Renwu Gao 1(B), Faisal Shafait 2, Seiichi Uchida 3, and Yaokai Feng 3 1 Information Sciene and Electrical Engineering, Kyushu
A Hierarchical Visual Saliency Model for Character Detection in Natural Scenes Renwu Gao 1(B), Faisal Shafait 2, Seiichi Uchida 3, and Yaokai Feng 3 1 Information Sciene and Electrical Engineering, Kyushu
A HMM-based Pre-training Approach for Sequential Data
 A HMM-based Pre-training Approach for Sequential Data Luca Pasa 1, Alberto Testolin 2, Alessandro Sperduti 1 1- Department of Mathematics 2- Department of Developmental Psychology and Socialisation University
A HMM-based Pre-training Approach for Sequential Data Luca Pasa 1, Alberto Testolin 2, Alessandro Sperduti 1 1- Department of Mathematics 2- Department of Developmental Psychology and Socialisation University
Keywords- Saliency Visual Computational Model, Saliency Detection, Computer Vision, Saliency Map. Attention Bottle Neck
 Volume 3, Issue 9, September 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Visual Attention
Volume 3, Issue 9, September 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Visual Attention
Vision: Over Ov view Alan Yuille
 Vision: Overview Alan Yuille Why is Vision Hard? Complexity and Ambiguity of Images. Range of Vision Tasks. More 10x10 images 256^100 = 6.7 x 10 ^240 than the total number of images seen by all humans
Vision: Overview Alan Yuille Why is Vision Hard? Complexity and Ambiguity of Images. Range of Vision Tasks. More 10x10 images 256^100 = 6.7 x 10 ^240 than the total number of images seen by all humans
The Attraction of Visual Attention to Texts in Real-World Scenes
 The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
Improved Intelligent Classification Technique Based On Support Vector Machines
 Improved Intelligent Classification Technique Based On Support Vector Machines V.Vani Asst.Professor,Department of Computer Science,JJ College of Arts and Science,Pudukkottai. Abstract:An abnormal growth
Improved Intelligent Classification Technique Based On Support Vector Machines V.Vani Asst.Professor,Department of Computer Science,JJ College of Arts and Science,Pudukkottai. Abstract:An abnormal growth
On the role of context in probabilistic models of visual saliency
 1 On the role of context in probabilistic models of visual saliency Date Neil Bruce, Pierre Kornprobst NeuroMathComp Project Team, INRIA Sophia Antipolis, ENS Paris, UNSA, LJAD 2 Overview What is saliency?
1 On the role of context in probabilistic models of visual saliency Date Neil Bruce, Pierre Kornprobst NeuroMathComp Project Team, INRIA Sophia Antipolis, ENS Paris, UNSA, LJAD 2 Overview What is saliency?
Cancer Cells Detection using OTSU Threshold Algorithm
 Cancer Cells Detection using OTSU Threshold Algorithm Nalluri Sunny 1 Velagapudi Ramakrishna Siddhartha Engineering College Mithinti Srikanth 2 Velagapudi Ramakrishna Siddhartha Engineering College Kodali
Cancer Cells Detection using OTSU Threshold Algorithm Nalluri Sunny 1 Velagapudi Ramakrishna Siddhartha Engineering College Mithinti Srikanth 2 Velagapudi Ramakrishna Siddhartha Engineering College Kodali
Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention
 Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention Tapani Raiko and Harri Valpola School of Science and Technology Aalto University (formerly Helsinki University of
Oscillatory Neural Network for Image Segmentation with Biased Competition for Attention Tapani Raiko and Harri Valpola School of Science and Technology Aalto University (formerly Helsinki University of
Adding Shape to Saliency: A Computational Model of Shape Contrast
 Adding Shape to Saliency: A Computational Model of Shape Contrast Yupei Chen 1, Chen-Ping Yu 2, Gregory Zelinsky 1,2 Department of Psychology 1, Department of Computer Science 2 Stony Brook University
Adding Shape to Saliency: A Computational Model of Shape Contrast Yupei Chen 1, Chen-Ping Yu 2, Gregory Zelinsky 1,2 Department of Psychology 1, Department of Computer Science 2 Stony Brook University
Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios
 2012 Ninth Conference on Computer and Robot Vision Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios Neil D. B. Bruce*, Xun Shi*, and John K. Tsotsos Department of Computer
2012 Ninth Conference on Computer and Robot Vision Recurrent Refinement for Visual Saliency Estimation in Surveillance Scenarios Neil D. B. Bruce*, Xun Shi*, and John K. Tsotsos Department of Computer
Hierarchical Convolutional Features for Visual Tracking
 Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Flexible, High Performance Convolutional Neural Networks for Image Classification
 Flexible, High Performance Convolutional Neural Networks for Image Classification Dan C. Cireşan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, Jürgen Schmidhuber IDSIA, USI and SUPSI Manno-Lugano,
Flexible, High Performance Convolutional Neural Networks for Image Classification Dan C. Cireşan, Ueli Meier, Jonathan Masci, Luca M. Gambardella, Jürgen Schmidhuber IDSIA, USI and SUPSI Manno-Lugano,
Subjective randomness and natural scene statistics
 Psychonomic Bulletin & Review 2010, 17 (5), 624-629 doi:10.3758/pbr.17.5.624 Brief Reports Subjective randomness and natural scene statistics Anne S. Hsu University College London, London, England Thomas
Psychonomic Bulletin & Review 2010, 17 (5), 624-629 doi:10.3758/pbr.17.5.624 Brief Reports Subjective randomness and natural scene statistics Anne S. Hsu University College London, London, England Thomas
IJREAS Volume 2, Issue 2 (February 2012) ISSN: LUNG CANCER DETECTION USING DIGITAL IMAGE PROCESSING ABSTRACT
 ISSN: LUNG CANCER DETECTION USING DIGITAL IMAGE PROCESSING ABSTRACT") LUNG CANCER DETECTION USING DIGITAL IMAGE PROCESSING Anita Chaudhary* Sonit Sukhraj Singh* ABSTRACT In recent years the image processing mechanisms are used widely in several medical areas for improving
LUNG CANCER DETECTION USING DIGITAL IMAGE PROCESSING Anita Chaudhary* Sonit Sukhraj Singh* ABSTRACT In recent years the image processing mechanisms are used widely in several medical areas for improving
Recognizing Scenes by Simulating Implied Social Interaction Networks
 Recognizing Scenes by Simulating Implied Social Interaction Networks MaryAnne Fields and Craig Lennon Army Research Laboratory, Aberdeen, MD, USA Christian Lebiere and Michael Martin Carnegie Mellon University,
Recognizing Scenes by Simulating Implied Social Interaction Networks MaryAnne Fields and Craig Lennon Army Research Laboratory, Aberdeen, MD, USA Christian Lebiere and Michael Martin Carnegie Mellon University,
Reading Assignments: Lecture 18: Visual Pre-Processing. Chapters TMB Brain Theory and Artificial Intelligence
 Brain Theory and Artificial Intelligence Lecture 18: Visual Pre-Processing. Reading Assignments: Chapters TMB2 3.3. 1 Low-Level Processing Remember: Vision as a change in representation. At the low-level,
Brain Theory and Artificial Intelligence Lecture 18: Visual Pre-Processing. Reading Assignments: Chapters TMB2 3.3. 1 Low-Level Processing Remember: Vision as a change in representation. At the low-level,
A Neural Network Architecture for.
 A Neural Network Architecture for Self-Organization of Object Understanding D. Heinke, H.-M. Gross Technical University of Ilmenau, Division of Neuroinformatics 98684 Ilmenau, Germany e-mail: dietmar@informatik.tu-ilmenau.de
A Neural Network Architecture for Self-Organization of Object Understanding D. Heinke, H.-M. Gross Technical University of Ilmenau, Division of Neuroinformatics 98684 Ilmenau, Germany e-mail: dietmar@informatik.tu-ilmenau.de
An Evaluation of Motion in Artificial Selective Attention
 An Evaluation of Motion in Artificial Selective Attention Trent J. Williams Bruce A. Draper Colorado State University Computer Science Department Fort Collins, CO, U.S.A, 80523 E-mail: {trent, draper}@cs.colostate.edu
An Evaluation of Motion in Artificial Selective Attention Trent J. Williams Bruce A. Draper Colorado State University Computer Science Department Fort Collins, CO, U.S.A, 80523 E-mail: {trent, draper}@cs.colostate.edu
Evaluating Visual Saliency Algorithms: Past, Present and Future
 Journal of Imaging Science and Technology R 59(5): 050501-1 050501-17, 2015. c Society for Imaging Science and Technology 2015 Evaluating Visual Saliency Algorithms: Past, Present and Future Puneet Sharma
Journal of Imaging Science and Technology R 59(5): 050501-1 050501-17, 2015. c Society for Imaging Science and Technology 2015 Evaluating Visual Saliency Algorithms: Past, Present and Future Puneet Sharma
The Importance of Time in Visual Attention Models
 The Importance of Time in Visual Attention Models Degree s Thesis Audiovisual Systems Engineering Author: Advisors: Marta Coll Pol Xavier Giró-i-Nieto and Kevin Mc Guinness Dublin City University (DCU)
The Importance of Time in Visual Attention Models Degree s Thesis Audiovisual Systems Engineering Author: Advisors: Marta Coll Pol Xavier Giró-i-Nieto and Kevin Mc Guinness Dublin City University (DCU)
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION. {zzwang, ruihuang, lwan,
 EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
EXEMPLAR BASED IMAGE SALIENT OBJECT DETECTION Zezheng Wang Rui Huang, Liang Wan 2 Wei Feng School of Computer Science and Technology, Tianjin University, Tianjin, China 2 School of Computer Software, Tianjin
SUN: A Model of Visual Salience Using Natural Statistics. Gary Cottrell Lingyun Zhang Matthew Tong Tim Marks Honghao Shan Nick Butko Javier Movellan
 SUN: A Model of Visual Salience Using Natural Statistics Gary Cottrell Lingyun Zhang Matthew Tong Tim Marks Honghao Shan Nick Butko Javier Movellan 1 Collaborators QuickTime and a TIFF (LZW) decompressor
SUN: A Model of Visual Salience Using Natural Statistics Gary Cottrell Lingyun Zhang Matthew Tong Tim Marks Honghao Shan Nick Butko Javier Movellan 1 Collaborators QuickTime and a TIFF (LZW) decompressor
Real-time computational attention model for dynamic scenes analysis
 Computer Science Image and Interaction Laboratory Real-time computational attention model for dynamic scenes analysis Matthieu Perreira Da Silva Vincent Courboulay 19/04/2012 Photonics Europe 2012 Symposium,
Computer Science Image and Interaction Laboratory Real-time computational attention model for dynamic scenes analysis Matthieu Perreira Da Silva Vincent Courboulay 19/04/2012 Photonics Europe 2012 Symposium,
A Vision-based Affective Computing System. Jieyu Zhao Ningbo University, China
 A Vision-based Affective Computing System Jieyu Zhao Ningbo University, China Outline Affective Computing A Dynamic 3D Morphable Model Facial Expression Recognition Probabilistic Graphical Models Some
A Vision-based Affective Computing System Jieyu Zhao Ningbo University, China Outline Affective Computing A Dynamic 3D Morphable Model Facial Expression Recognition Probabilistic Graphical Models Some
Object recognition and hierarchical computation
 Object recognition and hierarchical computation Challenges in object recognition. Fukushima s Neocognitron View-based representations of objects Poggio s HMAX Forward and Feedback in visual hierarchy Hierarchical
Object recognition and hierarchical computation Challenges in object recognition. Fukushima s Neocognitron View-based representations of objects Poggio s HMAX Forward and Feedback in visual hierarchy Hierarchical
Sensory Cue Integration
 Sensory Cue Integration Summary by Byoung-Hee Kim Computer Science and Engineering (CSE) http://bi.snu.ac.kr/ Presentation Guideline Quiz on the gist of the chapter (5 min) Presenters: prepare one main
Sensory Cue Integration Summary by Byoung-Hee Kim Computer Science and Engineering (CSE) http://bi.snu.ac.kr/ Presentation Guideline Quiz on the gist of the chapter (5 min) Presenters: prepare one main
Neuro-Inspired Statistical. Rensselaer Polytechnic Institute National Science Foundation
 Neuro-Inspired Statistical Pi Prior Model lfor Robust Visual Inference Qiang Ji Rensselaer Polytechnic Institute National Science Foundation 1 Status of Computer Vision CV has been an active area for over
Neuro-Inspired Statistical Pi Prior Model lfor Robust Visual Inference Qiang Ji Rensselaer Polytechnic Institute National Science Foundation 1 Status of Computer Vision CV has been an active area for over
Segmentation of Tumor Region from Brain Mri Images Using Fuzzy C-Means Clustering And Seeded Region Growing
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 5, Ver. I (Sept - Oct. 2016), PP 20-24 www.iosrjournals.org Segmentation of Tumor Region from Brain
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 5, Ver. I (Sept - Oct. 2016), PP 20-24 www.iosrjournals.org Segmentation of Tumor Region from Brain
Detection of terrorist threats in air passenger luggage: expertise development
 Loughborough University Institutional Repository Detection of terrorist threats in air passenger luggage: expertise development This item was submitted to Loughborough University's Institutional Repository
Loughborough University Institutional Repository Detection of terrorist threats in air passenger luggage: expertise development This item was submitted to Loughborough University's Institutional Repository
Intelligent Edge Detector Based on Multiple Edge Maps. M. Qasim, W.L. Woon, Z. Aung. Technical Report DNA # May 2012
 Intelligent Edge Detector Based on Multiple Edge Maps M. Qasim, W.L. Woon, Z. Aung Technical Report DNA #2012-10 May 2012 Data & Network Analytics Research Group (DNA) Computing and Information Science
Intelligent Edge Detector Based on Multiple Edge Maps M. Qasim, W.L. Woon, Z. Aung Technical Report DNA #2012-10 May 2012 Data & Network Analytics Research Group (DNA) Computing and Information Science
Modeling the Deployment of Spatial Attention
 17 Chapter 3 Modeling the Deployment of Spatial Attention 3.1 Introduction When looking at a complex scene, our visual system is confronted with a large amount of visual information that needs to be broken
17 Chapter 3 Modeling the Deployment of Spatial Attention 3.1 Introduction When looking at a complex scene, our visual system is confronted with a large amount of visual information that needs to be broken
Dynamic Visual Attention: Searching for coding length increments
 Dynamic Visual Attention: Searching for coding length increments Xiaodi Hou 1,2 and Liqing Zhang 1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University No. 8 Dongchuan Road,
Dynamic Visual Attention: Searching for coding length increments Xiaodi Hou 1,2 and Liqing Zhang 1 1 Department of Computer Science and Engineering, Shanghai Jiao Tong University No. 8 Dongchuan Road,
Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections
 Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections New: Bias-variance decomposition, biasvariance tradeoff, overfitting, regularization, and feature selection Yi
Review: Logistic regression, Gaussian naïve Bayes, linear regression, and their connections New: Bias-variance decomposition, biasvariance tradeoff, overfitting, regularization, and feature selection Yi
A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions
 FINAL VERSION PUBLISHED IN IEEE TRANSACTIONS ON IMAGE PROCESSING 06 A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions Milind S. Gide and Lina J.
FINAL VERSION PUBLISHED IN IEEE TRANSACTIONS ON IMAGE PROCESSING 06 A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions Milind S. Gide and Lina J.
Evaluation of the Impetuses of Scan Path in Real Scene Searching
 Evaluation of the Impetuses of Scan Path in Real Scene Searching Chen Chi, Laiyun Qing,Jun Miao, Xilin Chen Graduate University of Chinese Academy of Science,Beijing 0009, China. Key Laboratory of Intelligent
Evaluation of the Impetuses of Scan Path in Real Scene Searching Chen Chi, Laiyun Qing,Jun Miao, Xilin Chen Graduate University of Chinese Academy of Science,Beijing 0009, China. Key Laboratory of Intelligent
HUMAN VISUAL PERCEPTION CONCEPTS AS MECHANISMS FOR SALIENCY DETECTION
 HUMAN VISUAL PERCEPTION CONCEPTS AS MECHANISMS FOR SALIENCY DETECTION Oana Loredana BUZATU Gheorghe Asachi Technical University of Iasi, 11, Carol I Boulevard, 700506 Iasi, Romania lbuzatu@etti.tuiasi.ro
HUMAN VISUAL PERCEPTION CONCEPTS AS MECHANISMS FOR SALIENCY DETECTION Oana Loredana BUZATU Gheorghe Asachi Technical University of Iasi, 11, Carol I Boulevard, 700506 Iasi, Romania lbuzatu@etti.tuiasi.ro
Psychophysical tests of the hypothesis of a bottom-up saliency map in primary visual cortex
 Psychophysical tests of the hypothesis of a bottom-up saliency map in primary visual cortex In press for Public Library of Science, Computational Biology, (2007). Citation: Zhaoping L. May KA (2007) Psychophysical
Psychophysical tests of the hypothesis of a bottom-up saliency map in primary visual cortex In press for Public Library of Science, Computational Biology, (2007). Citation: Zhaoping L. May KA (2007) Psychophysical
Early Detection of Lung Cancer
 Early Detection of Lung Cancer Aswathy N Iyer Dept Of Electronics And Communication Engineering Lymie Jose Dept Of Electronics And Communication Engineering Anumol Thomas Dept Of Electronics And Communication
Early Detection of Lung Cancer Aswathy N Iyer Dept Of Electronics And Communication Engineering Lymie Jose Dept Of Electronics And Communication Engineering Anumol Thomas Dept Of Electronics And Communication
INCORPORATING VISUAL ATTENTION MODELS INTO IMAGE QUALITY METRICS
 INCORPORATING VISUAL ATTENTION MODELS INTO IMAGE QUALITY METRICS Welington Y.L. Akamine and Mylène C.Q. Farias, Member, IEEE Department of Computer Science University of Brasília (UnB), Brasília, DF, 70910-900,
INCORPORATING VISUAL ATTENTION MODELS INTO IMAGE QUALITY METRICS Welington Y.L. Akamine and Mylène C.Q. Farias, Member, IEEE Department of Computer Science University of Brasília (UnB), Brasília, DF, 70910-900,
ADAPTING COPYCAT TO CONTEXT-DEPENDENT VISUAL OBJECT RECOGNITION
 ADAPTING COPYCAT TO CONTEXT-DEPENDENT VISUAL OBJECT RECOGNITION SCOTT BOLLAND Department of Computer Science and Electrical Engineering The University of Queensland Brisbane, Queensland 4072 Australia
ADAPTING COPYCAT TO CONTEXT-DEPENDENT VISUAL OBJECT RECOGNITION SCOTT BOLLAND Department of Computer Science and Electrical Engineering The University of Queensland Brisbane, Queensland 4072 Australia
Development of novel algorithm by combining Wavelet based Enhanced Canny edge Detection and Adaptive Filtering Method for Human Emotion Recognition
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 12, Issue 9 (September 2016), PP.67-72 Development of novel algorithm by combining
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 12, Issue 9 (September 2016), PP.67-72 Development of novel algorithm by combining
Mammogram Analysis: Tumor Classification
 Mammogram Analysis: Tumor Classification Term Project Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is the
Mammogram Analysis: Tumor Classification Term Project Report Geethapriya Raghavan geeragh@mail.utexas.edu EE 381K - Multidimensional Digital Signal Processing Spring 2005 Abstract Breast cancer is the
The synergy of top-down and bottom-up attention in complex task: going beyond saliency models.
 The synergy of top-down and bottom-up attention in complex task: going beyond saliency models. Enkhbold Nyamsuren (e.nyamsuren@rug.nl) Niels A. Taatgen (n.a.taatgen@rug.nl) Department of Artificial Intelligence,
The synergy of top-down and bottom-up attention in complex task: going beyond saliency models. Enkhbold Nyamsuren (e.nyamsuren@rug.nl) Niels A. Taatgen (n.a.taatgen@rug.nl) Department of Artificial Intelligence,
TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING
 134 TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING H.F.S.M.Fonseka 1, J.T.Jonathan 2, P.Sabeshan 3 and M.B.Dissanayaka 4 1 Department of Electrical And Electronic Engineering, Faculty
134 TWO HANDED SIGN LANGUAGE RECOGNITION SYSTEM USING IMAGE PROCESSING H.F.S.M.Fonseka 1, J.T.Jonathan 2, P.Sabeshan 3 and M.B.Dissanayaka 4 1 Department of Electrical And Electronic Engineering, Faculty
B657: Final Project Report Holistically-Nested Edge Detection
 B657: Final roject Report Holistically-Nested Edge Detection Mingze Xu & Hanfei Mei May 4, 2016 Abstract Holistically-Nested Edge Detection (HED), which is a novel edge detection method based on fully
B657: Final roject Report Holistically-Nested Edge Detection Mingze Xu & Hanfei Mei May 4, 2016 Abstract Holistically-Nested Edge Detection (HED), which is a novel edge detection method based on fully
Design of Palm Acupuncture Points Indicator
 Design of Palm Acupuncture Points Indicator Wen-Yuan Chen, Shih-Yen Huang and Jian-Shie Lin Abstract The acupuncture points are given acupuncture or acupressure so to stimulate the meridians on each corresponding
Design of Palm Acupuncture Points Indicator Wen-Yuan Chen, Shih-Yen Huang and Jian-Shie Lin Abstract The acupuncture points are given acupuncture or acupressure so to stimulate the meridians on each corresponding
Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation
 Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation U. Baid 1, S. Talbar 2 and S. Talbar 1 1 Department of E&TC Engineering, Shri Guru Gobind Singhji
Comparative Study of K-means, Gaussian Mixture Model, Fuzzy C-means algorithms for Brain Tumor Segmentation U. Baid 1, S. Talbar 2 and S. Talbar 1 1 Department of E&TC Engineering, Shri Guru Gobind Singhji
G5)H/C8-)72)78)2I-,8/52& ()*+,-./,-0))12-345)6/3/782 9:-8;<;4.= J-3/ J-3/ "#&' "#% "#"% "#%$
H/C8-)72)78)2I-,8/52& ()*+,-./,-0))12-345)6/3/782 9:-8;<;4.= J-3/ J-3/ #&' #% #% #%$") # G5)H/C8-)72)78)2I-,8/52& #% #$ # # &# G5)H/C8-)72)78)2I-,8/52' @5/AB/7CD J-3/ /,?8-6/2@5/AB/7CD #&' #% #$ # # '#E ()*+,-./,-0))12-345)6/3/782 9:-8;;4. @5/AB/7CD J-3/ #' /,?8-6/2@5/AB/7CD #&F #&' #% #$
# G5)H/C8-)72)78)2I-,8/52& #% #$ # # &# G5)H/C8-)72)78)2I-,8/52' @5/AB/7CD J-3/ /,?8-6/2@5/AB/7CD #&' #% #$ # # '#E ()*+,-./,-0))12-345)6/3/782 9:-8;;4. @5/AB/7CD J-3/ #' /,?8-6/2@5/AB/7CD #&F #&' #% #$
Brain Tumor segmentation and classification using Fcm and support vector machine
 Brain Tumor segmentation and classification using Fcm and support vector machine Gaurav Gupta 1, Vinay singh 2 1 PG student,m.tech Electronics and Communication,Department of Electronics, Galgotia College
Brain Tumor segmentation and classification using Fcm and support vector machine Gaurav Gupta 1, Vinay singh 2 1 PG student,m.tech Electronics and Communication,Department of Electronics, Galgotia College
Image Enhancement and Compression using Edge Detection Technique
 Image Enhancement and Compression using Edge Detection Technique Sanjana C.Shekar 1, D.J.Ravi 2 1M.Tech in Signal Processing, Dept. Of ECE, Vidyavardhaka College of Engineering, Mysuru 2Professor, Dept.
Image Enhancement and Compression using Edge Detection Technique Sanjana C.Shekar 1, D.J.Ravi 2 1M.Tech in Signal Processing, Dept. Of ECE, Vidyavardhaka College of Engineering, Mysuru 2Professor, Dept.
MBios 478: Systems Biology and Bayesian Networks, 27 [Dr. Wyrick] Slide #1. Lecture 27: Systems Biology and Bayesian Networks
![MBios 478: Systems Biology and Bayesian Networks, 27 [Dr. Wyrick] Slide #1. Lecture 27: Systems Biology and Bayesian Networks](/thumbs/80/82116384.jpg "MBios 478: Systems Biology and Bayesian Networks, 27 [Dr. Wyrick] Slide #1. Lecture 27: Systems Biology and Bayesian Networks") MBios 478: Systems Biology and Bayesian Networks, 27 [Dr. Wyrick] Slide #1 Lecture 27: Systems Biology and Bayesian Networks Systems Biology and Regulatory Networks o Definitions o Network motifs o Examples
MBios 478: Systems Biology and Bayesian Networks, 27 [Dr. Wyrick] Slide #1 Lecture 27: Systems Biology and Bayesian Networks Systems Biology and Regulatory Networks o Definitions o Network motifs o Examples
Saliency aggregation: Does unity make strength?
 Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
Automatic Hemorrhage Classification System Based On Svm Classifier
 Automatic Hemorrhage Classification System Based On Svm Classifier Abstract - Brain hemorrhage is a bleeding in or around the brain which are caused by head trauma, high blood pressure and intracranial
Automatic Hemorrhage Classification System Based On Svm Classifier Abstract - Brain hemorrhage is a bleeding in or around the brain which are caused by head trauma, high blood pressure and intracranial
Sum of Neurally Distinct Stimulus- and Task-Related Components.
 SUPPLEMENTARY MATERIAL for Cardoso et al. 22 The Neuroimaging Signal is a Linear Sum of Neurally Distinct Stimulus- and Task-Related Components. : Appendix: Homogeneous Linear ( Null ) and Modified Linear
SUPPLEMENTARY MATERIAL for Cardoso et al. 22 The Neuroimaging Signal is a Linear Sum of Neurally Distinct Stimulus- and Task-Related Components. : Appendix: Homogeneous Linear ( Null ) and Modified Linear
Deep Networks and Beyond. Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University
 Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Deep Networks and Beyond Alan Yuille Bloomberg Distinguished Professor Depts. Cognitive Science and Computer Science Johns Hopkins University Artificial Intelligence versus Human Intelligence Understanding
Learning Spatiotemporal Gaps between Where We Look and What We Focus on
 Express Paper Learning Spatiotemporal Gaps between Where We Look and What We Focus on Ryo Yonetani 1,a) Hiroaki Kawashima 1,b) Takashi Matsuyama 1,c) Received: March 11, 2013, Accepted: April 24, 2013,
Express Paper Learning Spatiotemporal Gaps between Where We Look and What We Focus on Ryo Yonetani 1,a) Hiroaki Kawashima 1,b) Takashi Matsuyama 1,c) Received: March 11, 2013, Accepted: April 24, 2013,
Visual Saliency Based on Scale-Space Analysis in the Frequency Domain
 JOURNAL OF L A T E X CLASS FILES, VOL. 6, NO., JANUARY 27 Visual Saliency Based on Scale-Space Analysis in the Frequency Domain Jian Li, Student Member, IEEE, Martin D. Levine, Fellow, IEEE, Xiangjing
JOURNAL OF L A T E X CLASS FILES, VOL. 6, NO., JANUARY 27 Visual Saliency Based on Scale-Space Analysis in the Frequency Domain Jian Li, Student Member, IEEE, Martin D. Levine, Fellow, IEEE, Xiangjing
Predicting Search User Examination with Visual Saliency
 Predicting Search User Examination with Visual Saliency Yiqun Liu, Zeyang Liu, Ke Zhou, Meng Wang, Huanbo Luan, Chao Wang, Min Zhang, Shaoping Ma, Tsinghua National Laboratory for Information Science and
Predicting Search User Examination with Visual Saliency Yiqun Liu, Zeyang Liu, Ke Zhou, Meng Wang, Huanbo Luan, Chao Wang, Min Zhang, Shaoping Ma, Tsinghua National Laboratory for Information Science and
Probabilistic Evaluation of Saliency Models
 Matthias Kümmerer Matthias Bethge Centre for Integrative Neuroscience, University of Tübingen, Germany October 8, 2016 1 Introduction Model evaluation Modelling Saliency Maps 2 Matthias Ku mmerer, Matthias
Matthias Kümmerer Matthias Bethge Centre for Integrative Neuroscience, University of Tübingen, Germany October 8, 2016 1 Introduction Model evaluation Modelling Saliency Maps 2 Matthias Ku mmerer, Matthias
Attention Estimation by Simultaneous Observation of Viewer and View
 Attention Estimation by Simultaneous Observation of Viewer and View Anup Doshi and Mohan M. Trivedi Computer Vision and Robotics Research Lab University of California, San Diego La Jolla, CA 92093-0434
Attention Estimation by Simultaneous Observation of Viewer and View Anup Doshi and Mohan M. Trivedi Computer Vision and Robotics Research Lab University of California, San Diego La Jolla, CA 92093-0434