A Deep Multi-Level Network for Saliency Prediction
|
|
|
- Daisy Farmer
- 6 years ago
- Views:
Transcription
1 A Deep Multi-Level Network for Saliency Prediction Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra and Rita Cucchiara Dipartimento di Ingegneria Enzo Ferrari Università degli Studi di Modena e Reggio Emilia {name.surname}@unimore.it arxiv: v2 [cs.cv] 18 Jul 2017 Abstract This paper presents a novel deep architecture for saliency prediction. Current state of the art models for saliency prediction employ Fully Convolutional networks that perform a non-linear combination of features extracted from the last convolutional layer to predict saliency maps. We propose an architecture which, instead, combines features extracted at different levels of a Convolutional Neural Network (CNN). model is composed of three main blocks: a feature extraction CNN, a feature encoding network, that weights low and high level feature maps, and a prior learning network. We compare our solution with state of the art saliency models on two public benchmarks datasets. Results show that our model outperforms under all evaluation metrics on the SALICON dataset, which is currently the largest public dataset for saliency prediction, and achieves competitive results on the MIT300 benchmark. Code is available at I. INTRODUCTION When human observers look at an image, effective attentional mechanisms attract their gazes on salient regions which have distinctive variations in visual stimuli. Emulating such ability has been studied for more than 80 years by neuroscientists [1] and more recently by computer vision researches [2]. Traditionally, algorithms for saliency prediction focused on identifying the fixation points that human viewers would focus on at first glance. Others have concentrated on highlighting the most important object regions in an image [3], [4], [5]. We focus on the first type of saliency models, that try to predict eye fixations over an image. Inspired by biological studies, researchers have defined hand-crafted and multi-scale features that capture a large spectrum of stimuli: lower-level features (color, texture, contrast) [6] or higher-level concepts (faces, people, text, horizon) [7]. However, given the large variety of aspects that can contribute to define visual saliency, it is difficult to design approaches that combine all these hand-tuned factors in an appropriate way. In recent years, Deep learning techniques have shown impressive results in several vision tasks, such as image classification [8] and semantic segmentation [9]. Motivated by these achievements, first attempts to predict saliency map with deep convolutional networks have been performed [10], [11]. These solutions suffered from the small amount of training data compared to the ones available in other contexts requiring the usage of limited number of layers or the usage of pretrained architectures generated for other tasks. The recent publication of the large dataset SALICON [12], collected thanks to crowdsourcing techniques, allows researches to increase the number of convolutional layers reducing the overfitting risk [13], [14]. Moreover, it is well known that when observers view complex scenes presented on computer monitors, there is a strong tendency to look more frequently around the center of the scene than around the periphery [15]. This has been exploited in past works on saliency prediction, by incorporating handcrafted priors into saliency maps, or by learning the relative contribution of different priors. In this paper we present a deep learning architecture for predicting saliency maps, which exploits multi-level features extracted from a CNN, while still being trainable end-to-end. In contrast to the current trend, we let the network learn its own prior from training data. A new loss function is also designed to train the proposed network and to tackle the imbalance problem of saliency maps. II. RELATED WORK In the last decade saliency prediction has been widely studied. The seminal works by Koch and Ullman [16] and Itti et al. [2] introduced a biologically-plausible architecture for saliency detection that extracts multi-scale image features based on color, intensity and orientation. Later, Hou and Zange [6] proposed a method that analyzes the log spectrum of each image and obtains the spectral residual, which allows the estimation of the behavior of pre-attentive visual search. Torralba et al. [17] show how global contextual information can improve the prediction of observers eye movements in real-world scenes. Similarly, Goferman et al. [18] present a technique which aims at identifying salient regions that are distinctive with respect to both their local and global surroundings. Similarly to Cerf et al. [7], Judd et al. [19] propose an approach that combines low-level features (color, orientation and intensity) with high-level semantic information (i.e. the location of faces, cars and text) and show that this solution significantly improves the ability to predict eye fixations. In general, these approaches presented hand-tuned features or trained specific higher-level classifiers. A first attempt to model saliency with deep convolutional networks (DCNs) has been recently proposed by Vig et al. [10]. They propose Ensembles of Deep Networks (edn),



2 Input image Learned Prior Bilinear Upsampling MultiLevel features maps Conv 3x3 Saliency features maps Conv 1x1 Saliency map Fig. 1. Overview of our model (see Section III for details). A CNN is used to compute low and high level features from the input image. Extracted features maps are then fed to an Encoding network, which learns a feature weighting function to generate saliency-specific feature maps. A prior image is also learned and applied to the predicted saliency map. a CNN with three layers. Since the amount of data available to learn saliency is generally limited, this architecture cannot scale to outperform the current state-of-the art. To address this issue, Kümmerer et al. [11] present a way of reusing existing neural networks, trained for image classification, to predict fixation maps. In particular, they present Deep Gaze, a neural network that uses the well-known AlexNet [8] architecture to generate a high dimensional feature space, which is used to create a saliency map. Similarly, Huang et al. [12] propose an architecture that integrates saliency prediction into DCNs pretrained for object recognition (AlexNet [8], VGG-16 [20] and GoogLeNet [21]). The key component is a fine-tuning of DNNs weights with an objective function based on the saliency evaluation metrics, such as Normalized Scanpath Saliency (NSS), Similarity and KL-Divergence. Liu et al. [22] propose a multi-resolution CNN that is trained from image regions centered on fixation and nonfixation locations at multi-scales. Recently, Srinivas et al. [13] presented DeepFix, in which they introduce Location Biased Convolution filters that allow the network to exploit location dependent patterns. Pan et al. [14] present two different architectures: a shallow convnet trained from scratch and a deep convnet that uses parameters previous learned on the ILSVRC-12 dataset. What the majority of these approaches share is the use of Fully Convolutional Networks which are trained to predict saliency map from a non-linear combination of high level features, extracted from the last convolutional layer. architecture learns how to weight features coming from different levels of a CNN, and demonstrates the effectiveness of using medium level features. III. PROPOSED APPROACH saliency model is composed by three main parts: given an input image, a CNN extracts low, medium and high level features; then, an encoding network builds saliency-specific features and produces a temporary saliency map. A prior is then learned and applied to produce the final saliency prediction. Figure 1 reports a summary of the architecture. Feature extraction network The first component of our architecture is a Fully Convolutional network with 13 layers, which takes the input image and produces features maps for the encoding network. We build our architecture on the popular 16 layers model from VGG [20], which is well known for its elegance and simplicity, and at the same time yields nearly state of the art results in image classification and good generalization properties. However, like any standard CNN architecture, it has the significant disadvantage of reducing the size of feature maps at higher levels with respect to the input size. This is due to the presence of spatial pooling layers which have a stride greater than one: the output of each layer is a threedimensional tensor with shape k, where k is the number of filters of the layer, and f is the downsampling factor of that stage of the network. In the VGG-16 model there are five max-pooling stages with kernel size k = 2 and stride 2. Given an input image with size W H, the output feature map has size W 2 H 5 2, thus a Fully Convolutional model 5 built upon the VGG-16 would output a saliency map rescaled by a factor of 32. To limit this rescaling phenomenon, we remove the last pooling stage and decrease the stride of the last but one, while keeping unchanged its stride. This way, the output feature map of our feature extraction network are rescaled by a factor of 8 with respect to the input image. In the following, we will refer to the output size of the feature extraction network as w h, with w = W 8 and h = H 8. For reference, a complete description of the network is reported in Figure 2. Encoding network We take feature maps at three different locations: the output of the third pooling layer (which contains 256 feature maps), that of the last pooling layer (512 feature maps), and the output of the last convolutional layer (512 feature maps). In the following, we will call these maps, re- H f W f
3 spectively, conv3, conv4 and conv5, since they come from the third, fourth and fifth convolutional stage of the network. They all share the same spatial size, and are concatenated to form a tensor with 1280 channels, which is fed to a Dropout layer with retain probability 0.5, to improve generalization. A convolutional layer then learns 64 saliency-specific feature maps with a 3 3 kernel. A final 1 1 convolution learns to weight the importance of each saliency feature map to produce the final predicted feature map. Prior learning Instead of using pre-defined priors as done in the past, we let the network learn its own custom prior. To this end, we learn a coarse w h mask (with w w and h h), initialized to one, upsample and apply it to the predicted saliency map with pixel-wise multiplication. Given the learned prior U with shape w h, we interpolate the pixels of U to produce an output prior map V of size w h. We compute a sampling grid G of shape w h associating each element of U with real-valued coordinates into V. If G i,j = (x i,j, y i,j ) then U i,j should be equal to V at (x i,j, y i,j ); however since (x i,j, y i,j ) are real-valued, we convolve with a sampling kernel and set V x,y = U i,j k x (x x i,j )k y (y y i,j ) (1) w h i=1 j=1 where k x ( ) and k y ( ) are bilinear kernels, corresponding to k x (d) = max ( 0, w w d ) and k y (d) = max ( 0, h h d ). w and h were set to w/10 and h/10 in all our tests. Training At training time, we randomly sample a minibatch containing N training saliency maps (in our experiments N = 10), and encourage the network to minimize a loss function through Stochastic Gradient Descent. loss function is inspired by three objectives: predictions should be pixelwise similar to ground truth maps, therefore a square error loss φ(x i ) y 2 is a reasonable choice. Secondly, predicted maps should be invariant to their maximum, and there is no point in forcing the network to produce values in a given numerical range, so predictions are normalized by their maximum. Third, the loss should give the same importance to high and low ground truth values, even though the majority of ground truth pixels are close to zero. For this reason, the deviation between predicted values and ground-truth values y i is weighted by a linear function α y i, which tends to give more importance to pixels with high ground-truth fixation probability. The overall loss function is thus L(w) = 1 N N i=1 φ(x i) max φ(x i) y i α y i 2 + λ 1 U 2 (2) where a L 2 regularization term is added to penalize the deviation of the prior mask U from its initial value, thus encouraging the network to adapt to ground truth maps by changing convolutional weights rather than modifying the prior. Weights for the encoding network are initialized according to [23], and biases are initialized to zero. SGD is applied with Nesterov momentum 0.9, weight decay conv3-64 conv3-64 maxpool 2-2 conv3-128 conv3-128 maxpool 2-2 conv3-256 conv3-256 conv3-256 maxpool 2-2 maxpool 2-1 Feature extraction network Dropout conv3-64 conv1-1 Encoding network Fig. 2. Architecture of the proposed networks. The convolutional layer parameters are denoted as conv<receptive field size>-<number of channels>. The ReLU activation function is not shown for brevity. and learning rate Parameters α and λ are respectively set to 1.1 and 1/(w h ) in all our experiments. A. Experimental setup IV. EXPERIMENTAL EVALUATION We evaluate the effectiveness of our proposal on two publicly available datasets: SALICON [24] and MIT300 [28]. SALICON is currently the largest public dataset for saliency prediction, and contains 10,000 training images, 5,000 validation images and 5,000 testing images, taken from the Microsoft CoCo dataset [29]. Saliency maps were generated by collecting mouse movements, as a replacement of eye-tracking systems, and authors show an high degree of similarity between their maps and those created from eye-tracking data. MIT300 is one of the most commonly used datasets for saliency prediction, in spite of its limited size. It consists of 300 natural images, in which Saliency maps have been created from eye-tracking data of 39 observers. Saliency maps are not public available, and predictions must be submitted to the MIT saliency benchmark [30] for evaluation. Organizers of the benchmark suggest to use the MIT1003 [19] dataset for fine-tuning the model. This includes 1003 images taken from Flickr and LabelMe, generated through eye-tracking data of 15 participants. Evaluation metrics Saliency prediction results are usually evaluated with a large variety of metrics: Similarity, Linear Correlation Coefficient (CC), AUC Shuffled, AUC Borji, AUC Judd, Normalized Scanpath Saliency (NSS) and Earth Mover s Distance (EMD). Some of these metrics compare the predicted saliency map with the ground truth map generated from
4 TABLE I COMPARISON RESULTS ON THE SALICON TEST SET [24]. CC AUC shuffled AUC Judd method Deep Convnet - Pan et al. [14] Shallow Convnet - Pan et al. [14] WHU IIP Rare 2012 Improved [25] Xidian Baseline: BMS [26] Baseline: GBVS [27] Baseline: Itti [2] fixation points, while other directly compare the predicted saliency map with fixation points [31]. The Similarity metric [28] computes the sum of pixelwise minimums between the predicted saliency map SM and the human eye fixation map F M, where SM and F M are supposed to be probability distributions and sum up to one. A similarity score of one indicates that the predicted map is identical to the ground truth one. The linear correlation coefficient (CC), instead is the Pearson s linear coefficient between SM and F M. It ranges between 1 and 1, and a score close to 1 or 1 indicates a perfect linear relationship between the two maps. Earth Mover s Distance (EMD) represents the minimal cost to transform the probability distribution of the saliency map SM into the one of the human eye fixations F M. Therefore, a larger EMD indicates a larger difference between the two maps. The Normalized Scanpath Saliency (NSS) metric was defined specifically for the evaluation of saliency models [32]. The idea is to quantify the saliency map values at the eye fixation locations and to normalize it whit the saliency map variance NSS(p) = SM(p) µ SM σ SM (3) where p is the location of one fixation and SM is the saliency map which is normalized to have a zero mean and unit standard deviation. The final NSS score is the average of N SS(p) for all fixations. Finally, the Area Under the ROC curve (AUC) is one of the most widely used metrics for the evaluation of maps predicted from saliency models. There are several different implementations of this metric. In our experiments we use AUC Judd, AUC Borji and shuffled AUC. The AUC Judd and the AUC Borji choose non-fixation points with a uniform distribution, otherwise shuffled AUC uses human fixations of other images in the dataset as non-fixation distribution. In that way, centered distribution of human fixations of the dataset is taken into account. B. Feature importance analysis method relies on a non-linear combination of features extracted at different levels of a CNN. To validate our multilevel approach, we first evaluate the relative importance of features coming from each level. In the following, we define the importance of a feature as the extent to which a variation of the feature can affect the predicted map. Let us start by considering a linear model where different levels of a CNN are combined to obtain a pixel of the saliency map φ i (x) φ i (x) = w T i x + θ i (4) where w i and θ i are the weight vector and the bias relative to pixel i, while x represents the activation coming from different levels of the feature extraction CNN, and φ i (x) is the predicted saliency pixel. It is easy to see that the magnitude of elements in w i defines the importance of the corresponding features. In the extreme case of a pixel of the feature map which is always multiplied by 0, it is straightforward to see that part of the feature map is ignored by the model, and has therefore no importance, while a pixel with high absolute values in w i will have a considerable effect on the predicted saliency pixel. In our model, φ i ( ) is a highly non-linear function of the input, due to the presence of the encoding network and of the prior, thus the above reasoning is not directly applicable. Instead, given an image x j, we can approximate φ i (x j ) in the neighborhood of x j as follows φ i (x j ) φ i (x j ) T x + θ (5) An intuitive explanation of this approximation is that the magnitude of the partial derivatives indicates which features need to be changed to affect the model. Also notice that Eq. 5 is equivalent to a first order Taylor expansion. To get an estimation of the importance of each pixel in an activation map regardless of the choice of x j, we can average the element-wise absolute values of the gradient computed in the neighborhood of each validation sample. w i = 1 N N [ ] φ i x 1 (x j), φ i x 2 (x j),, φ i x d (x j) j=1 where d is the dimensionality of x j. Then, to get the relative importance of each activation map, we average the values of w i corresponding to that map, and L 1 normalize the resulting importances. To get an estimate of the importance of feature maps extracted from the CNN, we should compute φ i (x j ) for every (6)
5 TABLE II COMPARISON RESULTS ON THE MIT300 TEST SET [28]. Similarity CC AUC shuffled AUC Borji AUC Judd NSS EMD Infinite humans DeepFix [13] SALICON [12] method Pan et al. - Deep Convnet [14] BMS [26] Deep Gaze 2 [11] Mr-CNN [22] Pan et al. - Shallow Convnet [14] GBVS [27] Rare 2012 Improved [25] Judd [19] edn [10] test image j and for every saliency pixel i. To reduce the amount of required computation, instead of computing the gradient of each saliency pixel, we compute the gradient of the mean and variance of the output saliency map, in the neighborhood of each test sample. Applying Eq. 6, we get an indication of the contribution of each feature pixel to the mean and variance of the predicted map. Figure 3 reports the relative importance of activation maps coming from conv3, conv4 and conv5 on the model trained on SALICON. It is easy to notice that all features give a valuable contribution to the final result, and that while high level features are still the most relevant ones, medium level features have a considerable role in the prediction of the saliency map. This confirms our strategy to incorporate activations coming from different levels. C. Comparison with state of the art We evaluate our model on the SALICON dataset and on the MIT300 benchmark. In the first case, the network is trained on training images from the SALICON dataset, in the latter after training on SALICON we finetune on the MIT1003 dataset, as suggested by the MIT300 benchmark organizers. s from all datasets were zero-padded to fit a 4 : 3 aspect ratio, and then resized to ,50 0,45 0,40 0,35 0,30 0,25 0,20 0,15 0,10 0,05 0,00 (a) Contribution to mean 0,50 0,45 0,40 0,35 0,30 0,25 0,20 0,15 0,10 0,05 0,00 (b) Contribution to variance Fig. 3. Contribution of features extracted from conv3, conv4 and conv5 to prediction mean and variance. Table I compares the performance of our model on SAL- ICON in terms of CC, AUC shuffled and AUC Judd. As it can be observed, our solution outperforms all competitors by a margin of 12% according to CC metric, 4% and 1% according to AUC shuffled and AUC Judd. For reference, the proposed solution is also evaluated on the MIT300 saliency benchmark which contains results of almost 60 different methods. Table II presents a comparison between our approach and top performers in this benchmark. method outperforms the vast majority of the approaches in the leaderboard of the benchmark, and achieves competitive results when compared to the top ranked approaches. Figure 4 presents instead a qualitative comparison showing eight randomly chosen input images from SALICON and MIT1003 datasets, their corresponding ground truth annotations and predicted saliency maps. These examples clearly show how our approach is able to predict saliency maps that are very similar to the ground truth, while saliency maps generated by other methods are far less consistent with the ground truth. Finally, we present some failure cases in Figure 5. As shown, when there is no a clear and explicit object in the image, eye fixations tend to be biased toward image center, which our model fails to predict. V. CONCLUSIONS This paper presented a novel deep learning architecture for saliency prediction. model learns a non-linear combination of medium and high level features extracted from a CNN, and a prior to apply to predicted saliency maps, while still being trainable end-to-end. Qualitative and quantitative comparisons with state of the art approaches demonstrate the effectiveness of the proposal on the biggest dataset and on the most popular public benchmark for saliency prediction. ACKNOWLEDGMENT We acknowledge the support of NVIDIA Corporation with the donation of the GPUs used in this work. This work was partially supported by the Fondazione Cassa di Risparmio di Modena project: Vision for Augmented Experience and the PON R&C project DICET-INMOTO (Cod. PON04a2 D).
![Deep [14] Shallow [14] [25] [27] [22] [10]](/docs-images/72/67900950/images/6-0.jpg "[25] [27] Fig. 4.")


![dataset [19]. Best viewed in color. Fig. 5.](/docs-images/72/67900950/images/6-3.jpg "Example of failure cases on validation images")
![from SALICON dataset [24].](/docs-images/72/67900950/images/6-4.jpg "Best viewed in color. R EFERENCES [1] G. T.")

![, University of Chicago Press, 1935. [2] L.](/docs-images/72/67900950/images/6-6.jpg "Itti, C. Koch, and E.")

![TPAMI,, no. 11, pp. 1254 1259, 1998. [3] G.](/docs-images/72/67900950/images/6-8.jpg "Li and Y.")


![CVPR, 2013. [5] H. Jiang, J. Wang, Z. Yuan, Y.](/docs-images/72/67900950/images/6-11.jpg "Wu, N. Zheng, and S.")

![approach, in CVPR, 2013. [6] X. Hou and L.](/docs-images/72/67900950/images/6-13.jpg "Zhang, Saliency detection: A spectral")
![residual approach, in CVPR, 2007. [7] M.](/docs-images/72/67900950/images/6-14.jpg "Cerf, E. P. Frady, and C.")










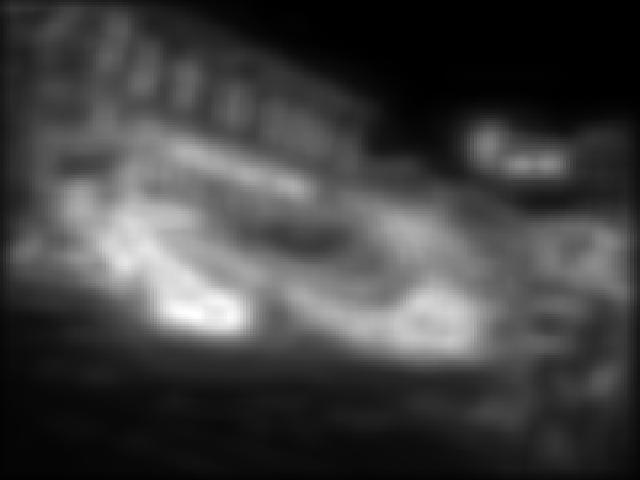



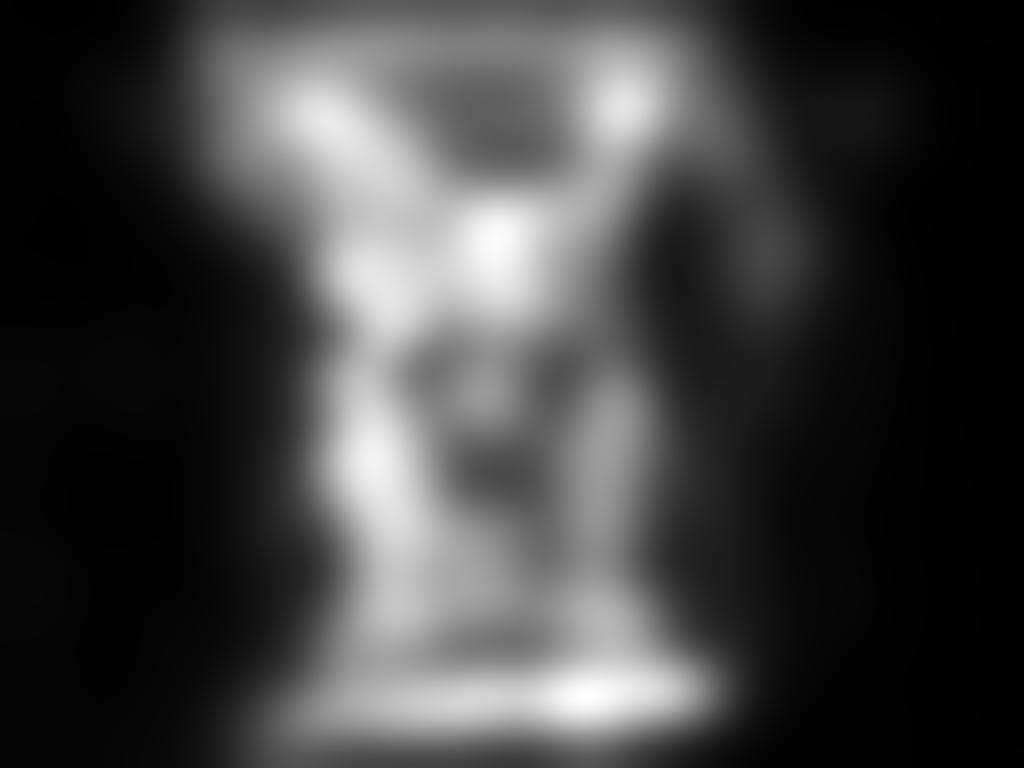




















6 Deep [14] Shallow [14] [25] [27] [22] [10] [25] [27] Fig. 4. Qualitative results and comparison to the state of the art. Left: validation images from SALICON dataset [24]. Right: validation images from MIT1003 dataset [19]. Best viewed in color. Fig. 5. Example of failure cases on validation images from SALICON dataset [24]. Best viewed in color. R EFERENCES [1] G. T. Buswell, How people look at pictures: a study of the psychology and perception in art., University of Chicago Press, [2] L. Itti, C. Koch, and E. Niebur, A model of saliency-based visual attention for rapid scene analysis, IEEE TPAMI,, no. 11, pp , [3] G. Li and Y. Yu, Visual saliency based on multiscale deep features, in CVPR, [4] Q. Yan, L. Xu, J. Shi, and J. Jia, Hierarchical saliency detection, in CVPR, [5] H. Jiang, J. Wang, Z. Yuan, Y. Wu, N. Zheng, and S. Li, Salient object detection: A discriminative regional feature integration approach, in CVPR, [6] X. Hou and L. Zhang, Saliency detection: A spectral residual approach, in CVPR, [7] M. Cerf, E. P. Frady, and C. Koch, Faces and text attract gaze independent of the task: Experimental data and computer model, Journal of vision, vol. 9, no. 12, pp , [8] A. Krizhevsky, I. Sutskever, and G. E. Hinton, net classification with deep convolutional neural networks, in ANIPS, 2012, pp [9] J. Long, E. Shelhamer, and T. Darrell, Fully convolutional networks for semantic segmentation, in CVPR, [10] E. Vig, M. Dorr, and D. Cox, Large-scale optimization of hierarchical features for saliency prediction in natural images, in CVPR, [11] M. K ummerer, L. Theis, and M. Bethge, Deep Gaze I: Boosting saliency prediction with feature maps trained on Net, arxiv preprint arxiv: , [12] X. Huang, C. Shen, X. Boix, and Q. Zhao, SALICON: Reducing the Semantic Gap in Saliency Prediction by Adapting Deep Neural Networks, in ICCV, [13] S. S. Kruthiventi, K. Ayush, and R. V. Babu, DeepFix: A Fully Convolutional Neural Network for predicting Human Eye Fixations, arxiv preprint arxiv: , [14] J. Pan, K. McGuinness, S. E., N. O Connor, and X. Gir o-i Nieto, Shallow and Deep Convolutional Networks for Saliency Prediction, in CVPR, [15] B. W. Tatler, The central fixation bias in scene viewing: Selecting an optimal viewing position independently of motor biases and image feature distributions, Journal of Vision, vol. 7, no. 14, pp. 4 4, [16] C. Koch and S. Ullman, Shifts in selective visual attention: towards the underlying neural circuitry, in Matters of intelligence, pp Springer, [17] A. Torralba, A. Oliva, M. S. Castelhano, and J. M. Henderson, Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search, Psychological review, vol. 113, no. 4, pp. 766, [18] S. Goferman, L. Zelnik-Manor, and A. Tal, Context-aware saliency detection, IEEE TPAMI, vol. 34, no. 10, pp , [19] T. Judd, K. Ehinger, F. Durand, and A. Torralba, Learning to predict where humans look, in ICCV, [20] K. Simonyan and A. Zisserman, Very deep convolutional networks for large-scale image recognition, CoRR, vol. abs/ , [21] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, Going deeper with convolutions, in CVPR, [22] N. Liu, J. Han, D. Zhang, S. Wen, and T. Liu, Predicting eye fixations using convolutional neural networks, in CVPR, [23] X. Glorot and Y. Bengio, Understanding the difficulty of training deep feedforward neural networks, in International conference on artificial intelligence and statistics, 2010, pp [24] M. Jiang, S. Huang, J. Duan, and Q. Zhao, Salicon: Saliency in context, in CVPR, [25] N. Riche, M. Mancas, M. Duvinage, M. Mibulumukini, B. Gosselin, and T. Dutoit, Rare2012: A multi-scale rarity-based saliency detection with its comparative statistical analysis, Signal Processing: Communication, vol. 28, no. 6, pp , [26] J. Zhang and S. Sclaroff, Saliency detection: A boolean map approach, in ICCV, [27] J. Harel, C. Koch, and P. Perona, Graph-based visual saliency, in ANIPS, 2006, pp [28] T. Judd, F. Durand, and A. Torralba, A benchmark of computational models of saliency to predict human fixations, in MIT Technical Report, [29] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ar, and C. L. Zitnick, Microsoft coco: Common objects in context, in ECCV, [30] Z. Bylinskii, T. Judd, A. Borji, L. Itti, F. Durand, A. Oliva, and A. Torralba, Mit saliency benchmark, [31] N. Riche, M. Duvinage, M. Mancas, B. Gosselin, and T. Dutoit, Saliency and human fixations: state-of-the-art and study of comparison metrics, in ICCV, [32] R. J. Peters, A. Iyer, L. Itti, and C. Koch, Components of bottom-up gaze allocation in natural images, Vision research, vol. 45, no. 18, pp , 2005.
Multi-Level Net: a Visual Saliency Prediction Model
 Multi-Level Net: a Visual Saliency Prediction Model Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, Rita Cucchiara Department of Engineering Enzo Ferrari, University of Modena and Reggio Emilia {name.surname}@unimore.it
Multi-Level Net: a Visual Saliency Prediction Model Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, Rita Cucchiara Department of Engineering Enzo Ferrari, University of Modena and Reggio Emilia {name.surname}@unimore.it
arxiv: v3 [cs.cv] 1 Jul 2018
![arxiv: v3 [cs.cv] 1 Jul 2018](/thumbs/83/87692676.jpg "arxiv: v3 [cs.cv] 1 Jul 2018") 1 Computer Vision and Image Understanding journal homepage: www.elsevier.com SalGAN: visual saliency prediction with adversarial networks arxiv:1701.01081v3 [cs.cv] 1 Jul 2018 Junting Pan a, Cristian Canton-Ferrer
1 Computer Vision and Image Understanding journal homepage: www.elsevier.com SalGAN: visual saliency prediction with adversarial networks arxiv:1701.01081v3 [cs.cv] 1 Jul 2018 Junting Pan a, Cristian Canton-Ferrer
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
 SalGAN: Visual Saliency Prediction with Generative Adversarial Networks Junting Pan, Elisa Sayrol and Xavier Giro-i-Nieto Image Processing Group Universitat Politecnica de Catalunya (UPC) Barcelona, Catalonia/Spain
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks Junting Pan, Elisa Sayrol and Xavier Giro-i-Nieto Image Processing Group Universitat Politecnica de Catalunya (UPC) Barcelona, Catalonia/Spain
Where should saliency models look next?
 Where should saliency models look next? Zoya Bylinskii 1, Adrià Recasens 1, Ali Borji 2, Aude Oliva 1, Antonio Torralba 1, and Frédo Durand 1 1 Computer Science and Artificial Intelligence Laboratory Massachusetts
Where should saliency models look next? Zoya Bylinskii 1, Adrià Recasens 1, Ali Borji 2, Aude Oliva 1, Antonio Torralba 1, and Frédo Durand 1 1 Computer Science and Artificial Intelligence Laboratory Massachusetts
arxiv: v1 [cs.cv] 3 Sep 2018
![arxiv: v1 [cs.cv] 3 Sep 2018](/thumbs/85/91733898.jpg "arxiv: v1 [cs.cv] 3 Sep 2018") Learning Saliency Prediction From Sparse Fixation Pixel Map Shanghua Xiao Department of Computer Science, Sichuan University, Sichuan Province, China arxiv:1809.00644v1 [cs.cv] 3 Sep 2018 2015223040036@stu.scu.edu.cn
Learning Saliency Prediction From Sparse Fixation Pixel Map Shanghua Xiao Department of Computer Science, Sichuan University, Sichuan Province, China arxiv:1809.00644v1 [cs.cv] 3 Sep 2018 2015223040036@stu.scu.edu.cn
arxiv: v1 [cs.cv] 1 Feb 2017
![arxiv: v1 [cs.cv] 1 Feb 2017](/thumbs/81/84358435.jpg "arxiv: v1 [cs.cv] 1 Feb 2017") Visual Saliency Prediction Using a Mixture of Deep Neural Networks Samuel Dodge and Lina Karam Arizona State University {sfdodge,karam}@asu.edu arxiv:1702.00372v1 [cs.cv] 1 Feb 2017 Abstract Visual saliency
Visual Saliency Prediction Using a Mixture of Deep Neural Networks Samuel Dodge and Lina Karam Arizona State University {sfdodge,karam}@asu.edu arxiv:1702.00372v1 [cs.cv] 1 Feb 2017 Abstract Visual saliency
CSE Introduction to High-Perfomance Deep Learning ImageNet & VGG. Jihyung Kil
 CSE 5194.01 - Introduction to High-Perfomance Deep Learning ImageNet & VGG Jihyung Kil ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
CSE 5194.01 - Introduction to High-Perfomance Deep Learning ImageNet & VGG Jihyung Kil ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton,
An Integrated Model for Effective Saliency Prediction
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) An Integrated Model for Effective Saliency Prediction Xiaoshuai Sun, 1,2 Zi Huang, 1 Hongzhi Yin, 1 Heng Tao Shen 1,3
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) An Integrated Model for Effective Saliency Prediction Xiaoshuai Sun, 1,2 Zi Huang, 1 Hongzhi Yin, 1 Heng Tao Shen 1,3
Task-driven Webpage Saliency
 Task-driven Webpage Saliency Quanlong Zheng 1[0000 0001 5059 0078], Jianbo Jiao 1,2[0000 0003 0833 5115], Ying Cao 1[0000 0002 9288 3167], and Rynson W.H. Lau 1[0000 0002 8957 8129] 1 Department of Computer
Task-driven Webpage Saliency Quanlong Zheng 1[0000 0001 5059 0078], Jianbo Jiao 1,2[0000 0003 0833 5115], Ying Cao 1[0000 0002 9288 3167], and Rynson W.H. Lau 1[0000 0002 8957 8129] 1 Department of Computer
Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model
 1 Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model arxiv:1611.09571v4 [cs.cv] 9 Jul 2018 Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, and Rita Cucchiara Abstract Data-driven
1 Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model arxiv:1611.09571v4 [cs.cv] 9 Jul 2018 Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, and Rita Cucchiara Abstract Data-driven
Computational modeling of visual attention and saliency in the Smart Playroom
 Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Computational modeling of visual attention and saliency in the Smart Playroom Andrew Jones Department of Computer Science, Brown University Abstract The two canonical modes of human visual attention bottomup
Deep Visual Attention Prediction
 IEEE TRANSACTIONS ON IMAGE PROCESSING 1 Deep Visual Attention Prediction Wenguan Wang, and Jianbing Shen, Senior Member, IEEE arxiv:1705.02544v3 [cs.cv] 22 Mar 2018 Abstract In this work, we aim to predict
IEEE TRANSACTIONS ON IMAGE PROCESSING 1 Deep Visual Attention Prediction Wenguan Wang, and Jianbing Shen, Senior Member, IEEE arxiv:1705.02544v3 [cs.cv] 22 Mar 2018 Abstract In this work, we aim to predict
Validating the Visual Saliency Model
 Validating the Visual Saliency Model Ali Alsam and Puneet Sharma Department of Informatics & e-learning (AITeL), Sør-Trøndelag University College (HiST), Trondheim, Norway er.puneetsharma@gmail.com Abstract.
Validating the Visual Saliency Model Ali Alsam and Puneet Sharma Department of Informatics & e-learning (AITeL), Sør-Trøndelag University College (HiST), Trondheim, Norway er.puneetsharma@gmail.com Abstract.
Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet
 Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet Matthias Kümmerer 1, Lucas Theis 1,2*, and Matthias Bethge 1,3,4* 1 Werner Reichardt Centre for Integrative Neuroscience,
Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet Matthias Kümmerer 1, Lucas Theis 1,2*, and Matthias Bethge 1,3,4* 1 Werner Reichardt Centre for Integrative Neuroscience,
THE human visual system has an exceptional ability of
 SUBMITTED MANUSCRIPT TO IEEE TCDS 1 DeepFeat: A Bottom Up and Top Down Saliency Model Based on Deep Features of Convolutional Neural Nets Ali Mahdi, Student Member, IEEE, and Jun Qin, Member, IEEE arxiv:1709.02495v1
SUBMITTED MANUSCRIPT TO IEEE TCDS 1 DeepFeat: A Bottom Up and Top Down Saliency Model Based on Deep Features of Convolutional Neural Nets Ali Mahdi, Student Member, IEEE, and Jun Qin, Member, IEEE arxiv:1709.02495v1
Hierarchical Convolutional Features for Visual Tracking
 Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
Hierarchical Convolutional Features for Visual Tracking Chao Ma Jia-Bin Huang Xiaokang Yang Ming-Husan Yang SJTU UIUC SJTU UC Merced ICCV 2015 Background Given the initial state (position and scale), estimate
arxiv: v2 [cs.cv] 22 Mar 2018
![arxiv: v2 [cs.cv] 22 Mar 2018](/thumbs/94/122062874.jpg "arxiv: v2 [cs.cv] 22 Mar 2018") Deep saliency: What is learnt by a deep network about saliency? Sen He 1 Nicolas Pugeault 1 arxiv:1801.04261v2 [cs.cv] 22 Mar 2018 Abstract Deep convolutional neural networks have achieved impressive performance
Deep saliency: What is learnt by a deep network about saliency? Sen He 1 Nicolas Pugeault 1 arxiv:1801.04261v2 [cs.cv] 22 Mar 2018 Abstract Deep convolutional neural networks have achieved impressive performance
Marc Assens, Xavier Giro-i-Nieto, Kevin McGuinness, Noel E. O Connor
 Accepted Manuscript Scanpath and saliency prediction on 360 degree images Marc Assens, Xavier Giro-i-Nieto, Kevin McGuinness, Noel E. O Connor PII: S0923-5965(18)30620-9 DOI: https://doi.org/10.1016/j.image.2018.06.006
Accepted Manuscript Scanpath and saliency prediction on 360 degree images Marc Assens, Xavier Giro-i-Nieto, Kevin McGuinness, Noel E. O Connor PII: S0923-5965(18)30620-9 DOI: https://doi.org/10.1016/j.image.2018.06.006
A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions
 FINAL VERSION PUBLISHED IN IEEE TRANSACTIONS ON IMAGE PROCESSING 06 A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions Milind S. Gide and Lina J.
FINAL VERSION PUBLISHED IN IEEE TRANSACTIONS ON IMAGE PROCESSING 06 A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions Milind S. Gide and Lina J.
The Importance of Time in Visual Attention Models
 The Importance of Time in Visual Attention Models Degree s Thesis Audiovisual Systems Engineering Author: Advisors: Marta Coll Pol Xavier Giró-i-Nieto and Kevin Mc Guinness Dublin City University (DCU)
The Importance of Time in Visual Attention Models Degree s Thesis Audiovisual Systems Engineering Author: Advisors: Marta Coll Pol Xavier Giró-i-Nieto and Kevin Mc Guinness Dublin City University (DCU)
SALIENCY refers to a component (object, pixel, person) in a
 in a") 1 Personalized Saliency and Its Prediction Yanyu Xu *, Shenghua Gao *, Junru Wu *, Nianyi Li, and Jingyi Yu arxiv:1710.03011v2 [cs.cv] 16 Jun 2018 Abstract Nearly all existing visual saliency models by
1 Personalized Saliency and Its Prediction Yanyu Xu *, Shenghua Gao *, Junru Wu *, Nianyi Li, and Jingyi Yu arxiv:1710.03011v2 [cs.cv] 16 Jun 2018 Abstract Nearly all existing visual saliency models by
Multi-attention Guided Activation Propagation in CNNs
 Multi-attention Guided Activation Propagation in CNNs Xiangteng He and Yuxin Peng (B) Institute of Computer Science and Technology, Peking University, Beijing, China pengyuxin@pku.edu.cn Abstract. CNNs
Multi-attention Guided Activation Propagation in CNNs Xiangteng He and Yuxin Peng (B) Institute of Computer Science and Technology, Peking University, Beijing, China pengyuxin@pku.edu.cn Abstract. CNNs
Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction
 TO APPEAR IN IEEE TRANSACTIONS ON MULTIMEDIA, 2017 1 Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction Cagdas Bak, Aysun Kocak, Erkut Erdem, and Aykut Erdem arxiv:1607.04730v2 [cs.cv] 15
TO APPEAR IN IEEE TRANSACTIONS ON MULTIMEDIA, 2017 1 Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction Cagdas Bak, Aysun Kocak, Erkut Erdem, and Aykut Erdem arxiv:1607.04730v2 [cs.cv] 15
arxiv: v1 [cs.cv] 2 Jun 2017
![arxiv: v1 [cs.cv] 2 Jun 2017](/thumbs/74/71415505.jpg "arxiv: v1 [cs.cv] 2 Jun 2017") INTEGRATED DEEP AND SHALLOW NETWORKS FOR SALIENT OBJECT DETECTION Jing Zhang 1,2, Bo Li 1, Yuchao Dai 2, Fatih Porikli 2 and Mingyi He 1 1 School of Electronics and Information, Northwestern Polytechnical
INTEGRATED DEEP AND SHALLOW NETWORKS FOR SALIENT OBJECT DETECTION Jing Zhang 1,2, Bo Li 1, Yuchao Dai 2, Fatih Porikli 2 and Mingyi He 1 1 School of Electronics and Information, Northwestern Polytechnical
Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling
 AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
AAAI -13 July 16, 2013 Video Saliency Detection via Dynamic Consistent Spatio- Temporal Attention Modelling Sheng-hua ZHONG 1, Yan LIU 1, Feifei REN 1,2, Jinghuan ZHANG 2, Tongwei REN 3 1 Department of
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION
 MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
MEMORABILITY OF NATURAL SCENES: THE ROLE OF ATTENTION Matei Mancas University of Mons - UMONS, Belgium NumediArt Institute, 31, Bd. Dolez, Mons matei.mancas@umons.ac.be Olivier Le Meur University of Rennes
arxiv: v1 [cs.cv] 3 May 2016
![arxiv: v1 [cs.cv] 3 May 2016](/thumbs/96/127479778.jpg "arxiv: v1 [cs.cv] 3 May 2016") WEPSAM: WEAKLY PRE-LEARNT SALIENCY MODEL Avisek Lahiri 1 Sourya Roy 2 Anirban Santara 3 Pabitra Mitra 3 Prabir Kumar Biswas 1 1 Dept. of Electronics and Electrical Communication Engineering, IIT Kharagpur,
WEPSAM: WEAKLY PRE-LEARNT SALIENCY MODEL Avisek Lahiri 1 Sourya Roy 2 Anirban Santara 3 Pabitra Mitra 3 Prabir Kumar Biswas 1 1 Dept. of Electronics and Electrical Communication Engineering, IIT Kharagpur,
THE last two decades have witnessed enormous development
 1 Semantic and Contrast-Aware Saliency Xiaoshuai Sun arxiv:1811.03736v1 [cs.cv] 9 Nov 2018 Abstract In this paper, we proposed an integrated model of semantic-aware and contrast-aware saliency combining
1 Semantic and Contrast-Aware Saliency Xiaoshuai Sun arxiv:1811.03736v1 [cs.cv] 9 Nov 2018 Abstract In this paper, we proposed an integrated model of semantic-aware and contrast-aware saliency combining
The Impact of Visual Saliency Prediction in Image Classification
 Dublin City University Insight Centre for Data Analytics Universitat Politecnica de Catalunya Escola Tècnica Superior d Enginyeria de Telecomunicacions de Barcelona Eric Arazo Sánchez The Impact of Visual
Dublin City University Insight Centre for Data Analytics Universitat Politecnica de Catalunya Escola Tècnica Superior d Enginyeria de Telecomunicacions de Barcelona Eric Arazo Sánchez The Impact of Visual
A Data-driven Metric for Comprehensive Evaluation of Saliency Models
 A Data-driven Metric for Comprehensive Evaluation of Saliency Models Jia Li 1,2, Changqun Xia 1, Yafei Song 1, Shu Fang 3, Xiaowu Chen 1 1 State Key Laboratory of Virtual Reality Technology and Systems,
A Data-driven Metric for Comprehensive Evaluation of Saliency Models Jia Li 1,2, Changqun Xia 1, Yafei Song 1, Shu Fang 3, Xiaowu Chen 1 1 State Key Laboratory of Virtual Reality Technology and Systems,
Saliency aggregation: Does unity make strength?
 Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
Saliency aggregation: Does unity make strength? Olivier Le Meur a and Zhi Liu a,b a IRISA, University of Rennes 1, FRANCE b School of Communication and Information Engineering, Shanghai University, CHINA
PathGAN: Visual Scanpath Prediction with Generative Adversarial Networks
 PathGAN: Visual Scanpath Prediction with Generative Adversarial Networks Marc Assens 1, Kevin McGuinness 1, Xavier Giro-i-Nieto 2, and Noel E. O Connor 1 1 Insight Centre for Data Analytic, Dublin City
PathGAN: Visual Scanpath Prediction with Generative Adversarial Networks Marc Assens 1, Kevin McGuinness 1, Xavier Giro-i-Nieto 2, and Noel E. O Connor 1 1 Insight Centre for Data Analytic, Dublin City
Saliency in Crowd. 1 Introduction. Ming Jiang, Juan Xu, and Qi Zhao
 Saliency in Crowd Ming Jiang, Juan Xu, and Qi Zhao Department of Electrical and Computer Engineering National University of Singapore Abstract. Theories and models on saliency that predict where people
Saliency in Crowd Ming Jiang, Juan Xu, and Qi Zhao Department of Electrical and Computer Engineering National University of Singapore Abstract. Theories and models on saliency that predict where people
Multi-Scale Salient Object Detection with Pyramid Spatial Pooling
 Multi-Scale Salient Object Detection with Pyramid Spatial Pooling Jing Zhang, Yuchao Dai, Fatih Porikli and Mingyi He School of Electronics and Information, Northwestern Polytechnical University, China.
Multi-Scale Salient Object Detection with Pyramid Spatial Pooling Jing Zhang, Yuchao Dai, Fatih Porikli and Mingyi He School of Electronics and Information, Northwestern Polytechnical University, China.
Convolutional Neural Networks (CNN)
") Convolutional Neural Networks (CNN) Algorithm and Some Applications in Computer Vision Luo Hengliang Institute of Automation June 10, 2014 Luo Hengliang (Institute of Automation) Convolutional Neural Networks
Convolutional Neural Networks (CNN) Algorithm and Some Applications in Computer Vision Luo Hengliang Institute of Automation June 10, 2014 Luo Hengliang (Institute of Automation) Convolutional Neural Networks
Understanding Low- and High-Level Contributions to Fixation Prediction
 Understanding Low- and High-Level Contributions to Fixation Prediction Matthias Kümmerer, Thomas S.A. Wallis, Leon A. Gatys, Matthias Bethge University of Tübingen, Centre for Integrative Neuroscience
Understanding Low- and High-Level Contributions to Fixation Prediction Matthias Kümmerer, Thomas S.A. Wallis, Leon A. Gatys, Matthias Bethge University of Tübingen, Centre for Integrative Neuroscience
Visual Saliency Based on Multiscale Deep Features Supplementary Material
 Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
Visual Saliency Based on Multiscale Deep Features Supplementary Material Guanbin Li Yizhou Yu Department of Computer Science, The University of Hong Kong https://sites.google.com/site/ligb86/mdfsaliency/
A Visual Saliency Map Based on Random Sub-Window Means
 A Visual Saliency Map Based on Random Sub-Window Means Tadmeri Narayan Vikram 1,2, Marko Tscherepanow 1 and Britta Wrede 1,2 1 Applied Informatics Group 2 Research Institute for Cognition and Robotics
A Visual Saliency Map Based on Random Sub-Window Means Tadmeri Narayan Vikram 1,2, Marko Tscherepanow 1 and Britta Wrede 1,2 1 Applied Informatics Group 2 Research Institute for Cognition and Robotics
Saliency in Crowd. Ming Jiang, Juan Xu, and Qi Zhao
 Saliency in Crowd Ming Jiang, Juan Xu, and Qi Zhao Department of Electrical and Computer Engineering National University of Singapore, Singapore eleqiz@nus.edu.sg Abstract. Theories and models on saliency
Saliency in Crowd Ming Jiang, Juan Xu, and Qi Zhao Department of Electrical and Computer Engineering National University of Singapore, Singapore eleqiz@nus.edu.sg Abstract. Theories and models on saliency
Methods for comparing scanpaths and saliency maps: strengths and weaknesses
 Methods for comparing scanpaths and saliency maps: strengths and weaknesses O. Le Meur olemeur@irisa.fr T. Baccino thierry.baccino@univ-paris8.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/
Methods for comparing scanpaths and saliency maps: strengths and weaknesses O. Le Meur olemeur@irisa.fr T. Baccino thierry.baccino@univ-paris8.fr Univ. of Rennes 1 http://www.irisa.fr/temics/staff/lemeur/
arxiv: v1 [cs.cv] 13 Jul 2018
![arxiv: v1 [cs.cv] 13 Jul 2018](/thumbs/84/89699669.jpg "arxiv: v1 [cs.cv] 13 Jul 2018") Multi-Scale Convolutional-Stack Aggregation for Robust White Matter Hyperintensities Segmentation Hongwei Li 1, Jianguo Zhang 3, Mark Muehlau 2, Jan Kirschke 2, and Bjoern Menze 1 arxiv:1807.05153v1 [cs.cv]
Multi-Scale Convolutional-Stack Aggregation for Robust White Matter Hyperintensities Segmentation Hongwei Li 1, Jianguo Zhang 3, Mark Muehlau 2, Jan Kirschke 2, and Bjoern Menze 1 arxiv:1807.05153v1 [cs.cv]
Going from Image to Video Saliency: Augmenting Image Salience with Dynamic Attentional Push
 Going from Image to Video Saliency: Augmenting Image Salience with Dynamic Attentional Push Siavash Gorji James J. Clark Centre for Intelligent Machines, Department of Electrical and Computer Engineering,
Going from Image to Video Saliency: Augmenting Image Salience with Dynamic Attentional Push Siavash Gorji James J. Clark Centre for Intelligent Machines, Department of Electrical and Computer Engineering,
Look, Perceive and Segment: Finding the Salient Objects in Images via Two-stream Fixation-Semantic CNNs
 Look, Perceive and Segment: Finding the Salient Objects in Images via Two-stream Fixation-Semantic CNNs Xiaowu Chen 1, Anlin Zheng 1, Jia Li 1,2, Feng Lu 1,2 1 State Key Laboratory of Virtual Reality Technology
Look, Perceive and Segment: Finding the Salient Objects in Images via Two-stream Fixation-Semantic CNNs Xiaowu Chen 1, Anlin Zheng 1, Jia Li 1,2, Feng Lu 1,2 1 State Key Laboratory of Virtual Reality Technology
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images
 Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images Sachin Mehta 1, Ezgi Mercan 1, Jamen Bartlett 2, Donald Weaver 2, Joann G. Elmore 1, and Linda Shapiro 1 1 University
Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images Sachin Mehta 1, Ezgi Mercan 1, Jamen Bartlett 2, Donald Weaver 2, Joann G. Elmore 1, and Linda Shapiro 1 1 University
Object-based Saliency as a Predictor of Attention in Visual Tasks
 Object-based Saliency as a Predictor of Attention in Visual Tasks Michal Dziemianko (m.dziemianko@sms.ed.ac.uk) Alasdair Clarke (a.clarke@ed.ac.uk) Frank Keller (keller@inf.ed.ac.uk) Institute for Language,
Object-based Saliency as a Predictor of Attention in Visual Tasks Michal Dziemianko (m.dziemianko@sms.ed.ac.uk) Alasdair Clarke (a.clarke@ed.ac.uk) Frank Keller (keller@inf.ed.ac.uk) Institute for Language,
Learning Spatiotemporal Gaps between Where We Look and What We Focus on
 Express Paper Learning Spatiotemporal Gaps between Where We Look and What We Focus on Ryo Yonetani 1,a) Hiroaki Kawashima 1,b) Takashi Matsuyama 1,c) Received: March 11, 2013, Accepted: April 24, 2013,
Express Paper Learning Spatiotemporal Gaps between Where We Look and What We Focus on Ryo Yonetani 1,a) Hiroaki Kawashima 1,b) Takashi Matsuyama 1,c) Received: March 11, 2013, Accepted: April 24, 2013,
Webpage Saliency. National University of Singapore
 Webpage Saliency Chengyao Shen 1,2 and Qi Zhao 2 1 Graduate School for Integrated Science and Engineering, 2 Department of Electrical and Computer Engineering, National University of Singapore Abstract.
Webpage Saliency Chengyao Shen 1,2 and Qi Zhao 2 1 Graduate School for Integrated Science and Engineering, 2 Department of Electrical and Computer Engineering, National University of Singapore Abstract.
arxiv: v2 [cs.cv] 7 Jun 2018
![arxiv: v2 [cs.cv] 7 Jun 2018](/thumbs/79/79761281.jpg "arxiv: v2 [cs.cv] 7 Jun 2018") Deep supervision with additional labels for retinal vessel segmentation task Yishuo Zhang and Albert C.S. Chung Lo Kwee-Seong Medical Image Analysis Laboratory, Department of Computer Science and Engineering,
Deep supervision with additional labels for retinal vessel segmentation task Yishuo Zhang and Albert C.S. Chung Lo Kwee-Seong Medical Image Analysis Laboratory, Department of Computer Science and Engineering,
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis
 Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
Object-Level Saliency Detection Combining the Contrast and Spatial Compactness Hypothesis Chi Zhang 1, Weiqiang Wang 1, 2, and Xiaoqian Liu 1 1 School of Computer and Control Engineering, University of
arxiv: v1 [cs.cv] 1 Sep 2016
![arxiv: v1 [cs.cv] 1 Sep 2016](/thumbs/89/98062352.jpg "arxiv: v1 [cs.cv] 1 Sep 2016") arxiv:1609.00072v1 [cs.cv] 1 Sep 2016 Attentional Push: Augmenting Salience with Shared Attention Modeling Siavash Gorji James J. Clark Centre for Intelligent Machines, Department of Electrical and Computer
arxiv:1609.00072v1 [cs.cv] 1 Sep 2016 Attentional Push: Augmenting Salience with Shared Attention Modeling Siavash Gorji James J. Clark Centre for Intelligent Machines, Department of Electrical and Computer
Object Detectors Emerge in Deep Scene CNNs
 Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Object Detectors Emerge in Deep Scene CNNs Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba Presented By: Collin McCarthy Goal: Understand how objects are represented in CNNs Are
Progressive Attention Guided Recurrent Network for Salient Object Detection
 Progressive Attention Guided Recurrent Network for Salient Object Detection Xiaoning Zhang, Tiantian Wang, Jinqing Qi, Huchuan Lu, Gang Wang Dalian University of Technology, China Alibaba AILabs, China
Progressive Attention Guided Recurrent Network for Salient Object Detection Xiaoning Zhang, Tiantian Wang, Jinqing Qi, Huchuan Lu, Gang Wang Dalian University of Technology, China Alibaba AILabs, China
Automated diagnosis of pneumothorax using an ensemble of convolutional neural networks with multi-sized chest radiography images
 Automated diagnosis of pneumothorax using an ensemble of convolutional neural networks with multi-sized chest radiography images Tae Joon Jun, Dohyeun Kim, and Daeyoung Kim School of Computing, KAIST,
Automated diagnosis of pneumothorax using an ensemble of convolutional neural networks with multi-sized chest radiography images Tae Joon Jun, Dohyeun Kim, and Daeyoung Kim School of Computing, KAIST,
Deriving an appropriate baseline for describing fixation behaviour. Alasdair D. F. Clarke. 1. Institute of Language, Cognition and Computation
 Central Baselines 1 Running head: CENTRAL BASELINES Deriving an appropriate baseline for describing fixation behaviour Alasdair D. F. Clarke 1. Institute of Language, Cognition and Computation School of
Central Baselines 1 Running head: CENTRAL BASELINES Deriving an appropriate baseline for describing fixation behaviour Alasdair D. F. Clarke 1. Institute of Language, Cognition and Computation School of
Efficient Deep Model Selection
 Efficient Deep Model Selection Jose Alvarez Researcher Data61, CSIRO, Australia GTC, May 9 th 2017 www.josemalvarez.net conv1 conv2 conv3 conv4 conv5 conv6 conv7 conv8 softmax prediction???????? Num Classes
Efficient Deep Model Selection Jose Alvarez Researcher Data61, CSIRO, Australia GTC, May 9 th 2017 www.josemalvarez.net conv1 conv2 conv3 conv4 conv5 conv6 conv7 conv8 softmax prediction???????? Num Classes
arxiv: v1 [cs.cv] 17 Aug 2017
![arxiv: v1 [cs.cv] 17 Aug 2017](/thumbs/78/78278805.jpg "arxiv: v1 [cs.cv] 17 Aug 2017") Deep Learning for Medical Image Analysis Mina Rezaei, Haojin Yang, Christoph Meinel Hasso Plattner Institute, Prof.Dr.Helmert-Strae 2-3, 14482 Potsdam, Germany {mina.rezaei,haojin.yang,christoph.meinel}@hpi.de
Deep Learning for Medical Image Analysis Mina Rezaei, Haojin Yang, Christoph Meinel Hasso Plattner Institute, Prof.Dr.Helmert-Strae 2-3, 14482 Potsdam, Germany {mina.rezaei,haojin.yang,christoph.meinel}@hpi.de
The Attraction of Visual Attention to Texts in Real-World Scenes
 The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
The Attraction of Visual Attention to Texts in Real-World Scenes Hsueh-Cheng Wang (hchengwang@gmail.com) Marc Pomplun (marc@cs.umb.edu) Department of Computer Science, University of Massachusetts at Boston,
Salient Object Detection Driven by Fixation Prediction
 Salient Object Detection Driven by Fixation Prediction Wenguan Wang 1, Jianbing Shen 1,2, Xingping Dong 1, Ali Borji 3 1 Beijing Lab of Intelligent Information Technology, School of Computer Science, Beijing
Salient Object Detection Driven by Fixation Prediction Wenguan Wang 1, Jianbing Shen 1,2, Xingping Dong 1, Ali Borji 3 1 Beijing Lab of Intelligent Information Technology, School of Computer Science, Beijing
Aggregated Sparse Attention for Steering Angle Prediction
 Aggregated Sparse Attention for Steering Angle Prediction Sen He, Dmitry Kangin, Yang Mi and Nicolas Pugeault Department of Computer Sciences,University of Exeter, Exeter, EX4 4QF Email: {sh752, D.Kangin,
Aggregated Sparse Attention for Steering Angle Prediction Sen He, Dmitry Kangin, Yang Mi and Nicolas Pugeault Department of Computer Sciences,University of Exeter, Exeter, EX4 4QF Email: {sh752, D.Kangin,
arxiv: v2 [cs.cv] 3 Jun 2018
![arxiv: v2 [cs.cv] 3 Jun 2018](/thumbs/89/97775247.jpg "arxiv: v2 [cs.cv] 3 Jun 2018") S4ND: Single-Shot Single-Scale Lung Nodule Detection Naji Khosravan and Ulas Bagci Center for Research in Computer Vision (CRCV), School of Computer Science, University of Central Florida, Orlando, FL.
S4ND: Single-Shot Single-Scale Lung Nodule Detection Naji Khosravan and Ulas Bagci Center for Research in Computer Vision (CRCV), School of Computer Science, University of Central Florida, Orlando, FL.
Predicting When Saliency Maps are Accurate and Eye Fixations Consistent
 Predicting When Saliency Maps are Accurate and Eye Fixations Consistent Anna Volokitin Michael Gygli Xavier Boix 2,3 Computer Vision Laboratory, ETH Zurich, Switzerland 2 Department of Electrical and Computer
Predicting When Saliency Maps are Accurate and Eye Fixations Consistent Anna Volokitin Michael Gygli Xavier Boix 2,3 Computer Vision Laboratory, ETH Zurich, Switzerland 2 Department of Electrical and Computer
arxiv: v1 [cs.cv] 28 Dec 2018
![arxiv: v1 [cs.cv] 28 Dec 2018](/thumbs/93/111330693.jpg "arxiv: v1 [cs.cv] 28 Dec 2018") Salient Object Detection via High-to-Low Hierarchical Context Aggregation Yun Liu 1 Yu Qiu 1 Le Zhang 2 JiaWang Bian 1 Guang-Yu Nie 3 Ming-Ming Cheng 1 1 Nankai University 2 A*STAR 3 Beijing Institute
Salient Object Detection via High-to-Low Hierarchical Context Aggregation Yun Liu 1 Yu Qiu 1 Le Zhang 2 JiaWang Bian 1 Guang-Yu Nie 3 Ming-Ming Cheng 1 1 Nankai University 2 A*STAR 3 Beijing Institute
Computational Cognitive Science
 Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
Computational Cognitive Science Lecture 19: Contextual Guidance of Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 20 November
Adding Shape to Saliency: A Computational Model of Shape Contrast
 Adding Shape to Saliency: A Computational Model of Shape Contrast Yupei Chen 1, Chen-Ping Yu 2, Gregory Zelinsky 1,2 Department of Psychology 1, Department of Computer Science 2 Stony Brook University
Adding Shape to Saliency: A Computational Model of Shape Contrast Yupei Chen 1, Chen-Ping Yu 2, Gregory Zelinsky 1,2 Department of Psychology 1, Department of Computer Science 2 Stony Brook University
An Experimental Analysis of Saliency Detection with respect to Three Saliency Levels
 An Experimental Analysis of Saliency Detection with respect to Three Saliency Levels Antonino Furnari, Giovanni Maria Farinella, Sebastiano Battiato {furnari,gfarinella,battiato}@dmi.unict.it Department
An Experimental Analysis of Saliency Detection with respect to Three Saliency Levels Antonino Furnari, Giovanni Maria Farinella, Sebastiano Battiato {furnari,gfarinella,battiato}@dmi.unict.it Department
Keywords- Saliency Visual Computational Model, Saliency Detection, Computer Vision, Saliency Map. Attention Bottle Neck
 Volume 3, Issue 9, September 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Visual Attention
Volume 3, Issue 9, September 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Visual Attention
arxiv: v1 [stat.ml] 23 Jan 2017
![arxiv: v1 [stat.ml] 23 Jan 2017](/thumbs/81/83414183.jpg "arxiv: v1 [stat.ml] 23 Jan 2017") Learning what to look in chest X-rays with a recurrent visual attention model arxiv:1701.06452v1 [stat.ml] 23 Jan 2017 Petros-Pavlos Ypsilantis Department of Biomedical Engineering King s College London
Learning what to look in chest X-rays with a recurrent visual attention model arxiv:1701.06452v1 [stat.ml] 23 Jan 2017 Petros-Pavlos Ypsilantis Department of Biomedical Engineering King s College London
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING
 VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
VIDEO SALIENCY INCORPORATING SPATIOTEMPORAL CUES AND UNCERTAINTY WEIGHTING Yuming Fang, Zhou Wang 2, Weisi Lin School of Computer Engineering, Nanyang Technological University, Singapore 2 Department of
Probabilistic Evaluation of Saliency Models
 Matthias Kümmerer Matthias Bethge Centre for Integrative Neuroscience, University of Tübingen, Germany October 8, 2016 1 Introduction Model evaluation Modelling Saliency Maps 2 Matthias Ku mmerer, Matthias
Matthias Kümmerer Matthias Bethge Centre for Integrative Neuroscience, University of Tübingen, Germany October 8, 2016 1 Introduction Model evaluation Modelling Saliency Maps 2 Matthias Ku mmerer, Matthias
arxiv: v2 [cs.cv] 29 Jan 2019
![arxiv: v2 [cs.cv] 29 Jan 2019](/thumbs/88/117548796.jpg "arxiv: v2 [cs.cv] 29 Jan 2019") Comparison of Deep Learning Approaches for Multi-Label Chest X-Ray Classification Ivo M. Baltruschat 1,2,, Hannes Nickisch 3, Michael Grass 3, Tobias Knopp 1,2, and Axel Saalbach 3 arxiv:1803.02315v2 [cs.cv]
Comparison of Deep Learning Approaches for Multi-Label Chest X-Ray Classification Ivo M. Baltruschat 1,2,, Hannes Nickisch 3, Michael Grass 3, Tobias Knopp 1,2, and Axel Saalbach 3 arxiv:1803.02315v2 [cs.cv]
HHS Public Access Author manuscript Med Image Comput Comput Assist Interv. Author manuscript; available in PMC 2018 January 04.
 Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules Xinyang Feng 1, Jie Yang 1, Andrew F. Laine 1, and Elsa D. Angelini 1,2 1 Department of Biomedical Engineering,
Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules Xinyang Feng 1, Jie Yang 1, Andrew F. Laine 1, and Elsa D. Angelini 1,2 1 Department of Biomedical Engineering,
Delving into Salient Object Subitizing and Detection
 Delving into Salient Object Subitizing and Detection Shengfeng He 1 Jianbo Jiao 2 Xiaodan Zhang 2,3 Guoqiang Han 1 Rynson W.H. Lau 2 1 South China University of Technology, China 2 City University of Hong
Delving into Salient Object Subitizing and Detection Shengfeng He 1 Jianbo Jiao 2 Xiaodan Zhang 2,3 Guoqiang Han 1 Rynson W.H. Lau 2 1 South China University of Technology, China 2 City University of Hong
Saliency Prediction with Active Semantic Segmentation
 JIANG et al.: SALIENCY PREDICTION WITH ACTIVE SEMANTIC SEGMENTATION 1 Saliency Prediction with Active Semantic Segmentation Ming Jiang 1 mjiang@u.nus.edu Xavier Boix 1,3 elexbb@nus.edu.sg Juan Xu 1 jxu@nus.edu.sg
JIANG et al.: SALIENCY PREDICTION WITH ACTIVE SEMANTIC SEGMENTATION 1 Saliency Prediction with Active Semantic Segmentation Ming Jiang 1 mjiang@u.nus.edu Xavier Boix 1,3 elexbb@nus.edu.sg Juan Xu 1 jxu@nus.edu.sg
Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation
 Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation Takumi Ege, Yoshikazu Ando, Ryosuke Tanno, Wataru Shimoda and Keiji Yanai Department of Informatics, The University of Electro-Communications,
Image-Based Estimation of Real Food Size for Accurate Food Calorie Estimation Takumi Ege, Yoshikazu Ando, Ryosuke Tanno, Wataru Shimoda and Keiji Yanai Department of Informatics, The University of Electro-Communications,
Highly Accurate Brain Stroke Diagnostic System and Generative Lesion Model. Junghwan Cho, Ph.D. CAIDE Systems, Inc. Deep Learning R&D Team
 Highly Accurate Brain Stroke Diagnostic System and Generative Lesion Model Junghwan Cho, Ph.D. CAIDE Systems, Inc. Deep Learning R&D Team Established in September, 2016 at 110 Canal st. Lowell, MA 01852,
Highly Accurate Brain Stroke Diagnostic System and Generative Lesion Model Junghwan Cho, Ph.D. CAIDE Systems, Inc. Deep Learning R&D Team Established in September, 2016 at 110 Canal st. Lowell, MA 01852,
Do Deep Neural Networks Suffer from Crowding?
 Do Deep Neural Networks Suffer from Crowding? Anna Volokitin Gemma Roig ι Tomaso Poggio voanna@vision.ee.ethz.ch gemmar@mit.edu tp@csail.mit.edu Center for Brains, Minds and Machines, Massachusetts Institute
Do Deep Neural Networks Suffer from Crowding? Anna Volokitin Gemma Roig ι Tomaso Poggio voanna@vision.ee.ethz.ch gemmar@mit.edu tp@csail.mit.edu Center for Brains, Minds and Machines, Massachusetts Institute
Computational Cognitive Science
 Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Computational Cognitive Science Lecture 15: Visual Attention Chris Lucas (Slides adapted from Frank Keller s) School of Informatics University of Edinburgh clucas2@inf.ed.ac.uk 14 November 2017 1 / 28
Comparison of Two Approaches for Direct Food Calorie Estimation
 Comparison of Two Approaches for Direct Food Calorie Estimation Takumi Ege and Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka, Chofu-shi, Tokyo
Comparison of Two Approaches for Direct Food Calorie Estimation Takumi Ege and Keiji Yanai Department of Informatics, The University of Electro-Communications, Tokyo 1-5-1 Chofugaoka, Chofu-shi, Tokyo
Expert identification of visual primitives used by CNNs during mammogram classification
 Expert identification of visual primitives used by CNNs during mammogram classification Jimmy Wu a, Diondra Peck b, Scott Hsieh c, Vandana Dialani, MD d, Constance D. Lehman, MD e, Bolei Zhou a, Vasilis
Expert identification of visual primitives used by CNNs during mammogram classification Jimmy Wu a, Diondra Peck b, Scott Hsieh c, Vandana Dialani, MD d, Constance D. Lehman, MD e, Bolei Zhou a, Vasilis
When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment
 When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment Honglin Zheng1, Tianlang Chen2, Jiebo Luo3 Department of Computer Science University of Rochester, Rochester,
When Saliency Meets Sentiment: Understanding How Image Content Invokes Emotion and Sentiment Honglin Zheng1, Tianlang Chen2, Jiebo Luo3 Department of Computer Science University of Rochester, Rochester,
arxiv: v1 [cs.cv] 15 Aug 2018
![arxiv: v1 [cs.cv] 15 Aug 2018](/thumbs/83/87651811.jpg "arxiv: v1 [cs.cv] 15 Aug 2018") Ensemble of Convolutional Neural Networks for Dermoscopic Images Classification Tomáš Majtner 1, Buda Bajić 2, Sule Yildirim 3, Jon Yngve Hardeberg 3, Joakim Lindblad 4,5 and Nataša Sladoje 4,5 arxiv:1808.05071v1
Ensemble of Convolutional Neural Networks for Dermoscopic Images Classification Tomáš Majtner 1, Buda Bajić 2, Sule Yildirim 3, Jon Yngve Hardeberg 3, Joakim Lindblad 4,5 and Nataša Sladoje 4,5 arxiv:1808.05071v1
The 29th Fuzzy System Symposium (Osaka, September 9-, 3) Color Feature Maps (BY, RG) Color Saliency Map Input Image (I) Linear Filtering and Gaussian
 Color Feature Maps (BY, RG) Color Saliency Map Input Image (I) Linear Filtering and Gaussian") The 29th Fuzzy System Symposium (Osaka, September 9-, 3) A Fuzzy Inference Method Based on Saliency Map for Prediction Mao Wang, Yoichiro Maeda 2, Yasutake Takahashi Graduate School of Engineering, University
The 29th Fuzzy System Symposium (Osaka, September 9-, 3) A Fuzzy Inference Method Based on Saliency Map for Prediction Mao Wang, Yoichiro Maeda 2, Yasutake Takahashi Graduate School of Engineering, University
Learning to Predict Saliency on Face Images
 Learning to Predict Saliency on Face Images Mai Xu, Yun Ren, Zulin Wang School of Electronic and Information Engineering, Beihang University, Beijing, 9, China MaiXu@buaa.edu.cn Abstract This paper proposes
Learning to Predict Saliency on Face Images Mai Xu, Yun Ren, Zulin Wang School of Electronic and Information Engineering, Beihang University, Beijing, 9, China MaiXu@buaa.edu.cn Abstract This paper proposes
Computational Cognitive Science. The Visual Processing Pipeline. The Visual Processing Pipeline. Lecture 15: Visual Attention.
 Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Lecture 15: Visual Attention School of Informatics University of Edinburgh keller@inf.ed.ac.uk November 11, 2016 1 2 3 Reading: Itti et al. (1998). 1 2 When we view an image, we actually see this: The
Shu Kong. Department of Computer Science, UC Irvine
 Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
Ubiquitous Fine-Grained Computer Vision Shu Kong Department of Computer Science, UC Irvine Outline 1. Problem definition 2. Instantiation 3. Challenge 4. Fine-grained classification with holistic representation
B657: Final Project Report Holistically-Nested Edge Detection
 B657: Final roject Report Holistically-Nested Edge Detection Mingze Xu & Hanfei Mei May 4, 2016 Abstract Holistically-Nested Edge Detection (HED), which is a novel edge detection method based on fully
B657: Final roject Report Holistically-Nested Edge Detection Mingze Xu & Hanfei Mei May 4, 2016 Abstract Holistically-Nested Edge Detection (HED), which is a novel edge detection method based on fully
Learned Region Sparsity and Diversity Also Predict Visual Attention
 Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Learned Region Sparsity and Diversity Also Predict Visual Attention Zijun Wei 1, Hossein Adeli 2, Gregory Zelinsky 1,2, Minh Hoai 1, Dimitris Samaras 1 1. Department of Computer Science 2. Department of
Action from Still Image Dataset and Inverse Optimal Control to Learn Task Specific Visual Scanpaths
 Action from Still Image Dataset and Inverse Optimal Control to Learn Task Specific Visual Scanpaths Stefan Mathe 1,3 and Cristian Sminchisescu 2,1 1 Institute of Mathematics of the Romanian Academy of
Action from Still Image Dataset and Inverse Optimal Control to Learn Task Specific Visual Scanpaths Stefan Mathe 1,3 and Cristian Sminchisescu 2,1 1 Institute of Mathematics of the Romanian Academy of
VISUAL search is necessary for rapid scene analysis
 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 3475 A Unified Framework for Salient Structure Detection by Contour-Guided Visual Search Kai-Fu Yang, Hui Li, Chao-Yi Li, and Yong-Jie
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 25, NO. 8, AUGUST 2016 3475 A Unified Framework for Salient Structure Detection by Contour-Guided Visual Search Kai-Fu Yang, Hui Li, Chao-Yi Li, and Yong-Jie
Objects do not predict fixations better than early saliency: A re-analysis of Einhäuser et al. s data
 Journal of Vision (23) 3():8, 4 http://www.journalofvision.org/content/3//8 Objects do not predict fixations better than early saliency: A re-analysis of Einhäuser et al. s data Ali Borji Department of
Journal of Vision (23) 3():8, 4 http://www.journalofvision.org/content/3//8 Objects do not predict fixations better than early saliency: A re-analysis of Einhäuser et al. s data Ali Borji Department of
Advertisement Evaluation Based On Visual Attention Mechanism
 2nd International Conference on Economics, Management Engineering and Education Technology (ICEMEET 2016) Advertisement Evaluation Based On Visual Attention Mechanism Yu Xiao1, 2, Peng Gan1, 2, Yuling
2nd International Conference on Economics, Management Engineering and Education Technology (ICEMEET 2016) Advertisement Evaluation Based On Visual Attention Mechanism Yu Xiao1, 2, Peng Gan1, 2, Yuling
Final Report: Automated Semantic Segmentation of Volumetric Cardiovascular Features and Disease Assessment
 Final Report: Automated Semantic Segmentation of Volumetric Cardiovascular Features and Disease Assessment Tony Lindsey 1,3, Xiao Lu 1 and Mojtaba Tefagh 2 1 Department of Biomedical Informatics, Stanford
Final Report: Automated Semantic Segmentation of Volumetric Cardiovascular Features and Disease Assessment Tony Lindsey 1,3, Xiao Lu 1 and Mojtaba Tefagh 2 1 Department of Biomedical Informatics, Stanford
A HMM-based Pre-training Approach for Sequential Data
 A HMM-based Pre-training Approach for Sequential Data Luca Pasa 1, Alberto Testolin 2, Alessandro Sperduti 1 1- Department of Mathematics 2- Department of Developmental Psychology and Socialisation University
A HMM-based Pre-training Approach for Sequential Data Luca Pasa 1, Alberto Testolin 2, Alessandro Sperduti 1 1- Department of Mathematics 2- Department of Developmental Psychology and Socialisation University
GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES
 GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES Jie Wu and Liqing Zhang MOE-Microsoft Laboratory for Intelligent Computing and Intelligent Systems Dept. of CSE, Shanghai Jiao Tong
GESTALT SALIENCY: SALIENT REGION DETECTION BASED ON GESTALT PRINCIPLES Jie Wu and Liqing Zhang MOE-Microsoft Laboratory for Intelligent Computing and Intelligent Systems Dept. of CSE, Shanghai Jiao Tong
Improving Saliency Models by Predicting Human Fixation Patches
 Improving Saliency Models by Predicting Human Fixation Patches Rachit Dubey 1, Akshat Dave 2, and Bernard Ghanem 1 1 King Abdullah University of Science and Technology, Saudi Arabia 2 University of California
Improving Saliency Models by Predicting Human Fixation Patches Rachit Dubey 1, Akshat Dave 2, and Bernard Ghanem 1 1 King Abdullah University of Science and Technology, Saudi Arabia 2 University of California
ArtTalk: Labeling Images with Thematic and Emotional Content
 ArtTalk: Labeling Images with Thematic and Emotional Content Yifan Wang Stanford University, VMware 3401 Hillview Ave, Palo Alto, CA, 94304 yifanwang@vmware.com Mana Lewis Chez Mana Co. mana@chezmana.com
ArtTalk: Labeling Images with Thematic and Emotional Content Yifan Wang Stanford University, VMware 3401 Hillview Ave, Palo Alto, CA, 94304 yifanwang@vmware.com Mana Lewis Chez Mana Co. mana@chezmana.com